CVPR2021 Part 3:百篇AR/VR关联性研究成果汇总

或能应用于增强现实/虚拟现实的部分论文及相关摘要
(映维网 2021年07月09日)2021年计算机视觉和模式识别大会(Conference on Computer Vision and Pattern Recognition;CVPR)早前已经公布了收录的论文,涵盖对象映射与渲染,3D人类姿态生成,语义分割和透明对象关键点估计等一系列的计算机视觉研究。
延伸阅读:CVPR2021 Part 1:百篇AR/VR关联性研究成果汇总
◐ 延伸阅读:CVPR2021 Part 2:百篇AR/VR关联性研究成果汇总
下面映维网整理了或能应用于增强现实/虚拟现实的部分论文及相关摘要,一共三篇,这是第三篇:
1. SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
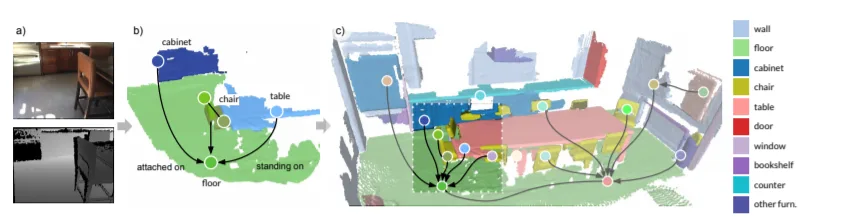
场景图是一种紧凑的显式表示方法,并成功地应用于各种二维场景理解任务中。本文提出了一种从给定RGB-D帧序列的3D环境中逐步建立语义场景图的方法。我们利用图神经网络从原始场景组件中聚集点网特征。我们同时提出了一种新的注意机制,它非常适合在这种增量重建场景中出现的部分和缺失的图形数据。尽管我们提出的方法设计成在场景的子贴图上运行,但我们同时展示了它在整个3D场景中的传递。实验表明,我们的方法比3D场景图预测方法大幅度地提高,其精度与其他3D语义和全景分割方法相一致,而速度则为35Hz。
相关论文:SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
2. How Privacy-Preserving are Line Clouds? Recovering Scene Details from 3D Lines

视觉定位是估计给定图像相对于已知场景的camera姿态的问题。视觉定位算法是先进的计算机视觉应用的基本组成部分。在实际应用中,许多算法通过运动点云结构来表示场景,并使用查询图像和三维点之间的2D-3D匹配来估计camera的姿态。如最近所示,通过将稀疏点云的渲染转换为图像,可以从Structure-from-Motion(SfM)点云中准确地恢复图像细节。为了解决由此产生的潜在用户隐私风险,最近有人提议将点云提升为线云,方法是用经过这些点的随机定向三维线替换三维点。人类无法理解由此产生的表示,而且它能够有效地防止了点云到图像的转换。本文表明,大量的三维场景几何信息保存在这些线云中,使我们能够(近似)恢复三维点位置,从而(近似)恢复图像内容。我们的方法是基于这样的观察,即直线之间的最近点可以很好地逼近原始的三维点。
相关论文:How Privacy-Preserving are Line Clouds? Recovering Scene Details from 3D Lines
3. Shape and Material Capture at Home

在本文中,我们提出了一种只使用摄像头,手电筒,和可选三脚架来估计对象几何和反射率的技术。我们提出了一种简单的数据捕获技术,其中用户在对象周围走动,用手电筒照明,并且只需捕获少量图像。我们的主要技术贡献是引入了一种递归神经结构,所述结构可以预测2{k}*2{k}分辨率下的几何结构和反射率,给定2{k}*2{k}分辨率下的输入图像,并以2{k-1}*2{k-1}分辨率从上一步估计几何结构和反射率。这种递归结构称为RecNet,它以256×256的分辨率进行训练,但在推理过程中可以很容易地对1024×1024个图像进行操作。结果表明,在给定三幅或更少的输入图像的情况下,我们的方法可以产生更精确的表面法线和反照率,特别是在高光区域和投射阴影区域。
4. We are More than Our Joints: Predicting how 3D Bodies Move
......(全文 10590 字,剩余 9534 字)