CVPR2021 Part 2:百篇AR/VR关联性研究成果汇总

或能应用于增强现实/虚拟现实的部分论文及相关摘要
(映维网 2021年07月08日)2021年计算机视觉和模式识别大会(Conference on Computer Vision and Pattern Recognition;CVPR)早前已经公布了收录的论文,涵盖对象映射与渲染,3D人类姿态生成,语义分割和透明对象关键点估计等一系列的计算机视觉研究。
延伸阅读:CVPR2021 Part 1:百篇AR/VR关联性研究成果汇总
下面映维网整理了或能应用于增强现实/虚拟现实的部分论文及相关摘要,一共分三篇,这是第二篇:
1. Single-Stage Instance Shadow Detectionwith Bidirectional Relation Learning

实例阴影检测的目的是找到与投射阴影的对象配对的阴影实例。之前的研究采用两阶段框架,首先从区域建议中预测阴影实例、对象实例和阴影对象关联,然后利用后处理对预测进行匹配,并形成最终的阴影对象对。本文提出了一种新的单阶段完全进化网络结构,通过一个双向关系学习模块,其以端到端的方式直接学习阴影和对象实例之间的关系。与以往的研究相比,本方法积极探索阴影与对象之间的内在联系,更好地学习阴影与对象之间的配对,从而提高了阴影检测的整体性能。
相关论文:Single-Stage Instance Shadow Detectionwith Bidirectional Relation Learning
2. Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion
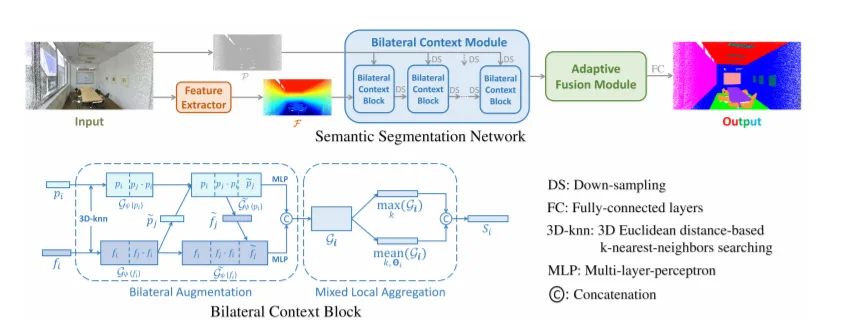
鉴于当前三维传感器的突出特点,对基本点云数据进行细粒度分析是值得进一步研究的问题。特别是真实的点云场景能够直观地捕捉到真实世界中的复杂环境,但三维数据的原始性对机器感知提出了很大的挑战。在这项研究中,我们专注于基本的视觉任务:语义分割。一方面,为了减少邻近点的歧义,我们充分利用双边结构中的几何和语义特征来增强其局部情景。另一方面,我们从多个分辨率综合解释了点的显著性,并在点级采用自适应融合的方法表示特征图,从而实现了精确的语义分割。另外,为了验证我们的关键模块,我们提供具体的消融研究和直观的可视化。通过在三个不同的基准上与最先进的网络进行比较,我们证明了我们网络的有效性。
相关论文:Semantic Segmentation for Real Point Cloud Scenes via Bilateral Augmentation and Adaptive Fusion
3. AutoInt: Automatic Integration for Fast Neural Volume Rendering
......(全文 9621 字,剩余 8883 字)








