CVPR2021 Part 1:百篇AR/VR关联性研究成果汇总

或能应用于增强现实/虚拟现实的部分论文及相关摘要
(映维网 2021年07月07日)2021年计算机视觉和模式识别大会(Conference on Computer Vision and Pattern Recognition;CVPR)早前已经公布了收录的论文,涵盖对象映射与渲染,3D人类姿态生成,语义分割和透明对象关键点估计等一系列的计算机视觉研究。
延伸阅读:CVPR2021 Part 1:百篇AR/VR关联性研究成果汇总
下面映维网整理了或能应用于增强现实/虚拟现实的部分论文及相关摘要,一共分三篇,这是第一篇:
1. Polka Lines: Learning Structured Illumination and Reconstruction for Active Stereo
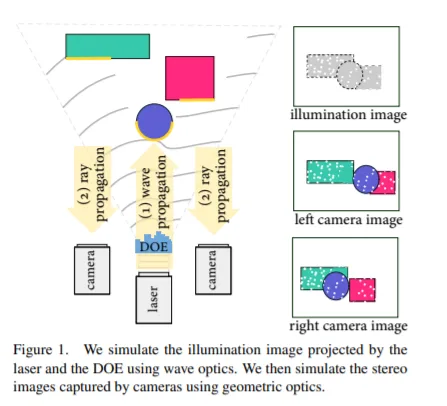
从结构光捕获中恢复深度的主动立体摄像头已成为三维场景重建和跨应用领域理解任务的基础传感器。主动立体摄像头在对象表面投影一个伪随机点图案,以独立于对象纹理提取视差。这种手动制作的图案是在与场景统计、环境照明条件和重建方法隔离的情况下设计而成。在这项研究中,我们提出了一种方法来共同学习结构化照明和重建。我们提出了一种基于波动光学和几何光学的主动立体可微成像模型和三目重建网络。我们将这种联合优化图案称为“Polka Line”,而连同重建网络,它们能够在整个成像条件下实现精确的主动立体深度估计。
相关论文:Polka Lines: Learning Structured Illumination and Reconstruction for Active Stereo
2. Visually Informed Binaural Audio Generation without Binaural Audios
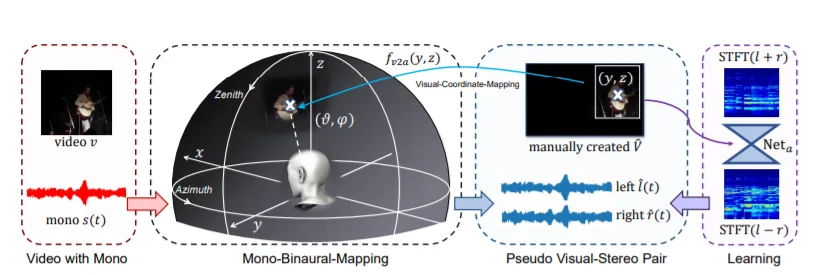
立体声音频,尤其是双耳音频,在沉浸式环境中起着至关重要的作用。最近的研究探索了通过多声道音频采集监督的立体声音频。但由于专业记录设备的要求,现有的数据集在规模和种类方面受到限制,从而阻碍了监督方法在现实场景中的推广。我们在这项研究中提出了PseudoBinaural,一个无需双耳录音的有效管道。关键的洞察是仔细建立伪视觉立体对与单声道数据的训练。具体来说,我们利用球谐分解和头相关脉冲响应(HRIR)来确定空间位置和接收到的双耳音频之间的关系。然后在视觉模态中,单声道数据的相应视觉线索手动放置在声源位置以形成对。与完全监督模式相比,我们的管道在交叉数据集评估中表现出极大的稳定性,并且在主观偏好下达到了相当的性能。
相关论文:Visually Informed Binaural Audio Generation without Binaural Audios
3. Dual Attention Guided Gaze Target Detection in the Wild
......(全文 9271 字,剩余 8509 字)








