谷歌CVPR2021:AR/VR关联性研究成果

或能用于增强现实/虚拟现实的部分论文
(映维网 2021年06月24日)2021年计算机视觉和模式识别大会(Conference on Computer Vision and Pattern Recognition;CVPR)正在如火如荼地进行中,并已经公布了收录的论文。
对于今年的CVPR大会,谷歌人工智能团队共有70多份论文获得了收录,并介绍了在计算机视觉的一系列研究,包括对象映射与渲染,3D人类姿态生成,语义分割和透明对象关键点估计等等。
下面映维网整理了或能应用于增强现实/虚拟现实的部分论文及相关摘要:
◐ 1. SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans
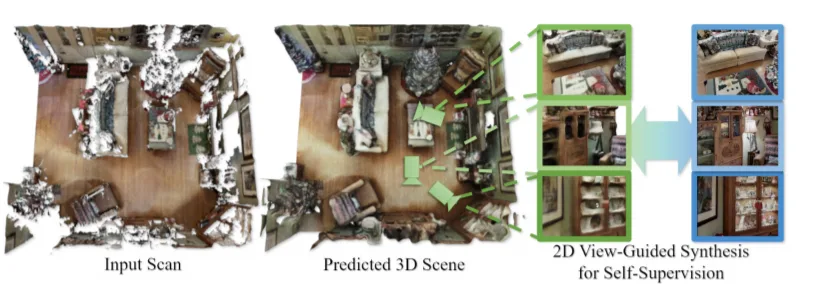
SPSG可以以自监督方式学习推断未观察到的场景几何和颜色,从而根据RGB-D扫描观察中生成高质量彩色三维场景模型。这种自监督方法用更完整的版本来关联不完整的RGB-D扫描,从而同时修复几何和颜色。值得注意的是,所述方法不依赖3D重建损失来为3D几何和颜色重建提供信息,而是建议在2D渲染操作对抗性和感知损失,以实现场景的高分辨率、高质量彩色重建。这利用了来自单个原始RGB-D帧的高分辨率、自一致性信号。所以,通过直接利用2D信号来为3D场景生成提供信息,团队提出的方法能够生成3D场景的高质量彩色重建。
相关论文:SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans
2. LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization
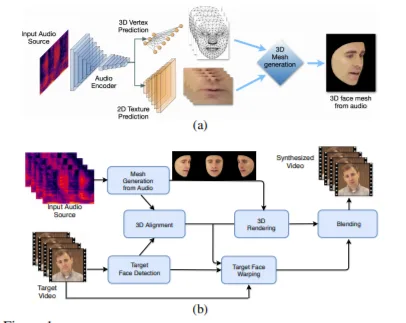
在这篇论文中,团队提出了一个基于视频的学习框架,其可以根据音频制作三维人脸说话效果的动画。研究人员提出了两种显著提高了数据采样效率的训练时数据归一化方法。首先,团队在一个标准化的空间中分离和表示人脸,其中所述空间将三维几何体、头部姿态和纹理解耦。这将预测问题分解为三维人脸形状和相应二维纹理atlas的回归。其次,研究人员利用面部对称性和皮肤的近似反照率恒定性来分离和去除时空光照变化。结合两者,这种归一化化允许简单的网络在新环境照明下生成高保真的唇音同步视频,同时只使用单个特定于说话人的视频进行训练。另外,为了稳定时间动态,研究人员引入了一种将模型置于先前视觉状态的自回归方法。
3. GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
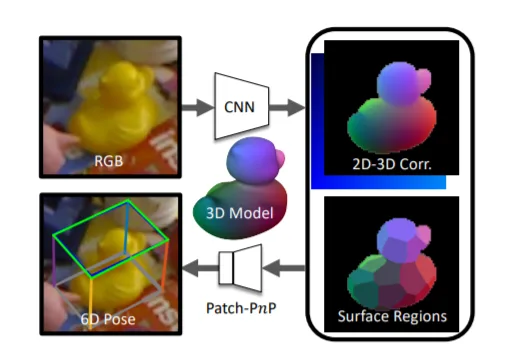
从一幅RGB图像中进行6D姿态估计是计算机视觉中的一项基本任务。目前,基于深度学习的方法主要依赖于一种间接策略:首先在图像平面和对象坐标系之间建立二维-三维的对应关系,然后应用PnP/RANSAC算法的变体。然而,这种两级管道不是端到端可训练,所以很难用于需要可微姿态的众多任务。另一方面,基于直接回归的方法目前不如基于几何的方法。在这项研究中,团队对直接方法和间接方法进行了深入的研究,并提出了一个简单而有效的Geometry-guided Direct Regression Network(GDR-Net),其能够从基于密集对应的中间几何表示中以端到端方式学习6D姿态。
相关论文:GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
4. Neural Descent for Visual 3D Human Pose and Shape
......(全文 3423 字,剩余 2452 字)