研发实战:如何为Quest 2优化移植PC VR内容《Showdown》

将《Showdown》移植到Quest 2并进行各种优化
(映维网Nweon 2022年05月14日)《Showdown》是Epic利用UE4开发的PC VR演示内容,并在2014年首次在Connect大会亮相。团队将这个作品移植到Quest 2,并希望尽可能保持PC版本的视觉逼真度,同时以一致的90 FPS运行。为了达到这个目标,你必须为移动渲染器显著优化CPU和GPU性能。
Application SpaceWarp(AppSW)则是一种面向开发者的优化技术,允许应用以实际显示刷新率的一半进行渲染(例如72 FPS的一半36 FPS),从而为合适的内容释放额外的计算能力。在Meta的初始测试中,AppSW为应用提供了高达70%的额外计算,而且几乎没有可感知的瑕疵。
在上一篇博文中,软件工程师扎科·德雷克(Zac Drake)将撰文介绍了AppSW是如何提高《Showdown》的性能,并演示了如何分析AppSW和其他渲染设置的影响。对于这篇博文,德雷克会讲解是如何把《Showdown》带到Quest 2,在过程中识别性能瓶颈,以及解决CPU和GPU密集型应用的具体优化方案。对于需要将项目移植到Quest的开发者,这值得参考。下面是映维网的具体整理:
Quest 2版《Showdown Demo》的UE4画质表现
◐ 1. 流程
从PC VR项目开始,我们的移植涉及数个阶段:
-
构建能够在Quest运行的项目
-
禁用性能密集型功能
-
衡量基线性能
-
优化精简项目
-
在重新启用单个功能时对其进行优化
-
重新启用功能
-
衡量性能影响
-
根据需要进行优化Building and Running
◐ 2. 构建和运行
在Unreal Editor中打开PC项目的副本,并将Android添加到Supported Platforms后,你需要对不太明显的设置进行更改。找到其中大多数设置的快速方法是利用Oculus Performance Window。
[Project Settings项目设置>Plugin插件>OculusVR>启动Oculus Performance Window]
◐ 2.1 项目设置
-
Disable Mobile HDR:Quest目前不支持Mobile HDR。禁用HDR可以减轻GPU负载,因为它减少每像素处理的数据。
[Project Settings项目设置 > Engine引擎 > Rendering渲染 > VR > Mobile HDR]
-
Enable Multi-View启用多视图:通过同时处理左眼和右眼的Tile,可以在VR中实现更高效的渲染。
[Project Settings项目设置 > Engine引擎 > Rendering渲染 > VR > Mobile Multi-View]
-
FFRDynamic:根据GPU利用率自动调整注视点渲染水平。
[Project Settings项目设置>Plugin插件>OculusVR>Mobile]
-
Vulkan:我们强烈鼓励在Quest中使用Vulkan。Oculus fork of Unreal包括数个针对Vulkan的修复和改进。AppSW和tonemap subpass都需要Vulkan。
在本文介绍范围之外,我们进行的其他改动包括:
-
更新至UE4.27
-
将Matinees转换为Level Sequencer。Matinees是一种不受欢迎的系统,并已由Level Sequencer所取代。
◐ 2.2 材质
-
移除折射输入:它们只支持MobileHDR,如上所述,Quest不支持MobileHDR。
-
更换不兼容的材质:特定材质在移动设备的行为不正确。对于《Showdown》,这包括第一辆车和机器人使用的shadow blob。我们暂时禁用了阴影,但最终换成了另一种材质。只要你使用移动友好的材质,阴影就可以很好地用于Quest。Unreal文档提供了有关移动材质限制的详细信息。
◐ 3. 禁用高成本功能
下一步是尽可能简化项目,以便在Quest实现可接受的性能(60 FPS或以上)。所以,我们采取了下列措施:
-
隐藏对整体体验不重要的actor,包括:所有碎片/垃圾;背景建筑;地铁入口;标志和海报;建筑的花俏装饰;动态照明
-
禁用所有粒子emitter。它们将在稍后的过程中逐个重新启用。
-
特定视觉效果(窗口反射、机器人眼睛周围的光晕等)过于昂贵,而禁用它们对整体体验没有太大影响。
这时,尽管存在低帧率和频繁卡顿的问题,但我们能够在设备打包和运行apk。如果你遇到类似问题,不要担心,我们将讨论其中的每一个问题。但首先,我们先收集性能指标,以衡量在做出更改时的改进。
◐ 4. 衡量性能
优化的关键是识别超载的特定系统资源。然后,你就可以针对高负载功能和流程进行优化或消除。
每次剖析应用时,请务必回答以下问题:
-
应用是否达到我的性能目标?具体来说,帧持续时间是否满足我的目标,例如72 fps是13.9 ms或90 fps是11.3 ms。
-
如果没有,应用是属于CPU bound或GPU bound?
-
如果是CPU bound,主线程或渲染线程花费的时间是否太长?
-
如果是GPU bound,是vertex问题还是fragment问题?
下面我们来看看确定瓶颈的过程,以及解决瓶颈的方法。分析工具之间存在很大的重叠,每个开发者都有自己的偏好,所以我们尝试提供多种选择。
◐ 4.1 CPU bound或GPU bound
当你需要确定瓶颈是CPU还是GPU上时,有几种方法可以检查是哪一个降低了帧率。
-
Oculus Developer Hub(ODH):在Performance Analyzer选项卡中观察统计数据。
-
CPU>CPU level &GPU>GPU level:如果存在性能问题的应用是CPU 4和GPU 2,则答案是CPU bound,因为依然存在可用的GPU开销。但如果两个level都为4,且应用程序存在问题,则这个数字没有太大帮助。你应该使用其他指标。
-
Timing > App GPU Time:如果显示的时间长度超过单个帧的长度(90 fps是11.1ms),则答案是GPU bound。
-
GPU > GPU Utilization:如果这个值最大为100%,则答案是GPU bound。
-
-
VrApi:你可以在logcat VrApi输出中找到与“adb logcat-s VrApi”相同的统计信息。
-
你同时可以在Unreal Insights、Perfetto或RenderDoc中使用systrace信息来确定游戏和渲染线程的时间。
有关使用Perfetto设置systrace的详细信息,请参阅前一篇博文
◐ 延伸阅读:研发实战:《Showdown》如何通过AppSW技术提高性能
5. CPU性能
在分析CPU时,你将看到两个主线程;游戏线程和渲染线程。如果任何一个线程占用的时间超过了所需的帧持续时间,都会对帧速率产生负面影响。所以,我们来看看如何确定线程是否花费太长时间,以及如何优化它们。
在分析CPU时,你将看到两个主线程;游戏线程和渲染线程。如果任何一个线程占用的时间超过了所需的帧持续时间,都会对帧速率产生负面影响。所以,我们来看看如何确定线程是否花费太长时间,以及如何优化它们。
哪个线程太长?
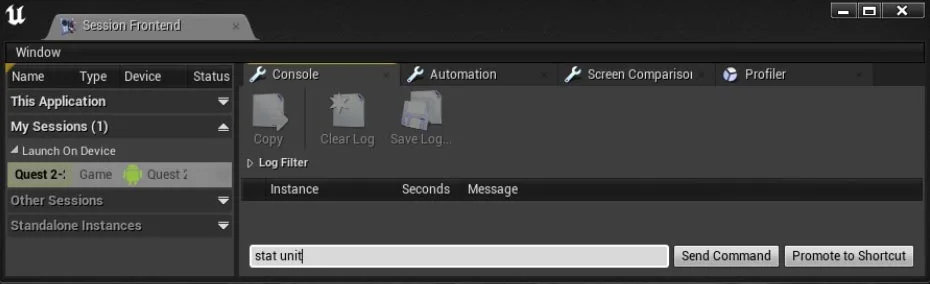
◐ 5.1 UE4 Session Frontend
-
从Unreal Editor启动应用
-
[Window > Developer Tools > Session Frontend]
-
选择Console选项卡
-
在左侧,展开“My Sessions”和“Launch On Device”
-
选择你的Quest
-
在Console选项卡的底部输入“stat unit”,然后单击“Send Command”
-
在设备端,查看Game(游戏线程)和Draw(渲染线程)的值
◐ 5.2 ADB
或者,你可以使用以下adb命令启用相同的统计信息:
adb shell “am broadcast -a android.intent.action.RUN -e cmd ‘stat unit’”
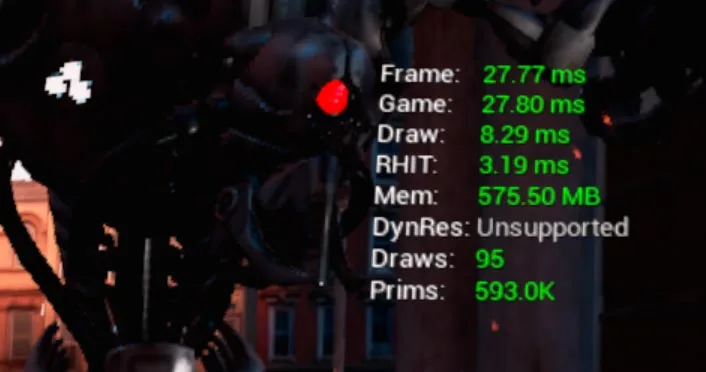
利用显示的信息,你可以确定游戏或渲染线程是否需要更长的时间。在上面的屏幕截图中,应用程序明显受到游戏线程的限制。接下来我们将研究如何优化游戏和渲染线程。
◐ 6. 游戏线程
游戏线程处理所有游戏逻辑和物理模拟。它可能会受众多actor和复杂Blueprint逻辑困扰。
◐ 6.1 actor
-
减少骨骼网格: 使用Skeletal Mesh Reduction Plugin骨骼网格缩减插件来减少骨骼网格。
-
隐藏actor:在可能的情况下,隐藏actor以减少CPU处理。汽车翻车后会挡住士兵。这时候可以隐藏士兵。
◐ 6.2 Blueprint
-
增加Tick Interval :不是所有元素都需要更新每一帧。尽可能增加Tick Interval。请注意,勾选这个选项可能会影响物理/碰撞,甚至视觉效果,所以在使用时要小心。
-
[Blueprint > Details > Actor Tick > Tick Interval (secs)]
-
-
Nativize Blueprints——如果你有特别复杂的Blueprint,你可以通过转换成原生C++来提高它们的效率。
◐ 6.3 物理
禁用碰撞:这不会适用于所有场景,但因为《Showdown》不是交互式内容,我们可以通过禁用士兵的碰撞检测来节省物理处理。
[Details > Collision > Collision Presets = NoCollision]
◐ 6.4 粒子
Epic提供了有关粒子系统优化的有用细节:Unreal文档;Unreal文档
-
减少粒子数和寿命:场景中的粒子越多,寿命越长,需要进行的评估就越多。将寿命限制在效果所需的持续时间内是一种很好的做法。
-
减少活动emitter:Tick Time直接受场景中活动emitter的数量影响。场景中活动emitter越多,Tick Time越长。除非要求emitter在关卡开始时循环,你才将emitter设置为自动激活。
-
禁用碰撞:碰撞模块的成本非常昂贵,可能会对CPU性能产生显著影响。所以请考虑在视觉可接受时禁用粒子碰撞。在粒子编辑器中,从每个emitter移除碰撞模块。
◐ 7. 渲染线程
渲染线程绘制对GPU的调用。即便几何数据没有减少,但将对象组合到单个绘制调用中会更有效。提高渲染线程性能的主要方法是通过组合actor和instancing来减少绘制调用。
概括言之:减少绘制调用
◐ 7.1 actor
-
合并actor:通过将对象合并为单个actor来减少绘制调用。请记住,在合并对象时,合并的bounding box大小会增加。较大的bounding box可能意味着对象被剔除的频率较低,并会导致CPU和GPU处理更多的绘制调用。重要的是要分析场景,以确保在合并时提高性能。在《Showdown》中,我们广泛使用 Proxy Geometry Tool来合并建筑物和场景的其他部分。
-
[Window > Developer Tools > Merge Actors]
-
-
隐藏actor:如上文所述,隐藏被翻转汽车遮挡的士兵同样可以减少绘制调用
◐ 7.2 Instancing
实例化允许你在单个绘制调用中渲染一批相同的网格。网格的顶点已可用于GPU。然而,GPU需要一个transform来渲染网格的每个occurrence。实例化将transform存储在GPU内存中,这样就可以将它们批处理为单个绘制调用。
-
自动Instancing:这是最简单的方法。引擎将为你发现并批量复制网格。
-
Instanced Static Mesh (ISM):不是在场景中创建多个静态网格,而是创建一个空actor,添加ISM组件,并在组件属性中添加实例。注意:所述实例不是单独剔除,不能在运行时移动。
-
Hierarchical Instanced Static Mesh (HISM)-与ISMs类似,但提供LOD和距离剔除支持。不过,这会增加性能成本。
更多关于渲染线程优化的详细信息请访问Epic文档。
◐ 8. GPU性能
不同于其他GPU为顶点和片段着色器采用不同的计算单元,高通使用统一的着色器架构。相同的核心运行顶点着色器和片段着色器。你不会遇到这样一种情况:有太多的片段工作,以至于顶点工作可以并行完成而不需要花费成本。
换句话说,了解哪个阶段、片段或顶点需要GPU的大部分时间依然非常有用,因为每个阶段都应用了不同的优化。
你可以使用ovrgpuprofiler查看片段和顶点花费的时间。
-
从adb shell运行“ovrgpuprofiler-r”
-
检查以下各项的值:
-
%时间着色片段
-
%时间着色顶点
-
另一个测试是将应用程序的渲染比例缩小到较小的值(如0.2),从而渲染更少的像素。这将渲染更少的片段,但保留场景复杂性。
-
运行VrApi
-
adb logcat-s VrApi
-
-
记下应用时间
-
减少像素密度
-
*adb shell “am broadcast -a android.intent.action.RUN -e cmd ‘vr.PixelDensity 0.2’”
-
-
再次检查VrApi应用时间
-
如果应用时间改善,则片段工作多。
-
如果应用时间没有改善,则顶点工作多(或可能会是CPU bound)。
-
注意:这个方法同样可以作为判断GPU bound与CPU bound的一个指标,因为移动VR应用更可能是fragment bound而不是vertex bound。如果应用时间随着像素密度的降低而提高,你应该再看看CPU利用率。

◐ 9. Vertex 顶点
顶点密集型应用存在场景复杂性问题。这本质上是太多三角形同时渲染。
概括言之:减少三角形/顶点
-
生成LOD:与camera保持一定距离时减少网格细节。Unreal提供了一个可以减少静态网格多边形数的自动LOD工具。对于《Showdown》,这包括汽车、垃圾桶、机器人和建筑物。我们发现默认距离不会触发level change,所以我们手动调整了它们。我们的LOD工作流程是:
-
在静态或骨架网格编辑器中打开网格
-
禁用 [LOD Settings > Auto Compute LOD Distances]
-
增加[LOD Settings > Number of LODs]到2以创建LOD 1
-
启用 [View Mode > Level Of Detail Coloration > Mesh LOD Coloration]
-
View Mode视图模式通常在场景视图的左上角显示为“Lit”。
-
这可以在网格编辑器和主编辑器窗口中更改。
-
调整 [LOD 1 > Screen Size] 并确认LOD正在切换。
-

-
降低网格复杂性:对于复杂网格,你可能会发现LOD 0包含的三角形比视觉上可以识别的多。在这种情况下,可以减少LOD的三角形百分比,也可以将Minimum LOD增加到LOD 1。
-
[Mesh Editor > Details > LOD 0 > Reduction Settings > Percent Triangles]
-
[Mesh Editor > Details > LOD Settings > Minimum LOD]
-
-
移除几何体:可以使用静态网格编辑器移除UE4编辑器中的部分网格。我们手动从用户看不到的网格中剥离原语,例如建筑物的背面。
-
减少网格粒子:sprite粒子效率更高,因为它们向场景中添加的tri更少。尽量少用网格粒子。更少的网格将减少绘制调用。
◐ 10. 片段
片段密集型应用存在着色器复杂性问题。实际上,计算单个像素花费了太多时间。
概括言之:简化着色器
Material Analyzer:标识项目中的所有材质或材质实例。
◐ 10.1 纹理/材质
-
合并和烘焙:从一种或多种材质创建纹理,以降低着色器的复杂性。
-
合并纹理采样节点:避免多次对同一纹理重新采样。美术可以使用比例和UV偏移多次采样相同的纹理,从而为材质添加变化。这种变化在制作美术方面几乎没有成本,但纹理提取不可能优化,因为UV不同。
-
Fully Rough-尽可能使用。这样可以节省大量材质instruction和一个sampler。
-
[Material Editor > Details > Material > Fully Rough]
-
-
禁用Lightmap Directionality:禁用这个选项可以提供不适用每像素法线的低成本照明
-
[Material Editor > Details > Mobile > Use Lightmap Directionality]
-
-
LOD Bias:诸如汽水罐等小型物品的纹理可以很大。将LOD Bias调整到最低可接受水平将最小化纹理带宽消耗。
-
[Texture Editor > Details > Level Of Detail > LOD Bias]
-
-
替换复杂的材质:例如,我们用成本更低的版本替换了昂贵的弹痕材质。
-
Noise Node Level:减少爆炸材质的level大大减少了instruction计数。在一个案例中,我们将值从7减少到2。
-
[Material Editor > Noise node > Details > Levels]
-
-
纹理sampler:将所有纹理sampler转为使用三线性(或双线性)滤波,而不是aniso。Texture Group允许在配置中进行设置,无需进行美术调整。如果特定视觉看起来更糟(例如道路、人行道、砖墙),你可以轻松将单个纹理sampler更新回aniso。
-
8.1 更新Texture Group的配置:
-
在In Config/DefaultDeviceProfiles.ini, 查找[Oculus_Quest2 DeviceProfile].
-
对于每个“+TextureLodGroup”,将MinMagFilter更改为Linear而不是Aniso。
-
如果将MipFilter设置为point,它将使用双线性。
-
如果不设置MipFilter,它将使用三线性。
-
8.2 更新单个纹理的filter:
-
[Texture Editor > Details > Texture > Filter]
-
-
照明
-
动态照明:我们尝试在《Showdown》中启用动态照明(爆炸和枪声),但由于触发时填充率增加,这导致了卡屏。最后,我们选择只使用静态照明。
-
-
粒子
-
GPU粒子纹理分辨率:尺寸减小到256x256。理想情况下,将粒子移动到CPU并完全避免GPU工作,但更简单的解决方案是将纹理分辨率缩小到最大粒子数的大小。
-
[Project Settings > Engine > Rendering > Optimizations]
-
使用CPU而不是GPU:你可以使用GPU粒子,但是如果是GPU bound,并且CPU存在空间,请尝试把它们移回去。在粒子编辑器中,删除所有“GPU Sprites”模块。要再次将它们移动到GPU,右键单击emitter并选择[TypeData>New GPU Sprites]。剖析两个选项。
-
emitter材质:在《Showdown》中,emitter材质用来降低复杂性。我们预计透明材质的成本会十分高昂。由于屏幕上的粒子尺寸较小,它们接触的像素总数较低。结果证明,它们的成本并不高。特定材质依靠折射。所以,我们创造了新的效果(例如汽车爆炸时的烟雾爆炸效果和弹痕)。
-
-
项目设置
-
最大各向异性:如果使用aniso,限制各向异性采样数会减少纹理带宽,但不会节省纹理内存。在DefaultEngine中设置r.maxObstrophic.ini和DefaultScalabity.ini。
-
像素密度-如果所有其他方法都失败,可以将像素密度从1.0降低到0.9。修改虚拟现实。使用“执行控制台命令”蓝图节点的像素密度。当GPU是碎片绑定的,并且所有其他选项都已用尽时,这是最后的选择。我们建议动态设置像素密度,以便仅在GPU负担过重的区域降低像素密度,并在可管理时恢复到1.0。
-
◐ 11. 更广泛的优化
特定优化为CPU和GPU提供了显著的性能改进。由于它们不完全符合上述类别,我们将在这里进行讨论。
骨架网格剔除:在分析骨架网格的性能时,我们注意到剔除依然在提交视图外网格的绘制调用,而这会降低性能。解决这个问题的步骤是:
-
通过在bound更新中包含组件位置,确保bound根据需要进行更新。
-
[Skeletal Mesh Component > Optimization > Component Use Fixed Skel Bounds = false]
-
这非常必要,因为我们启用了“ Only Tick Pose when Rendered”
-
[Skeletal Mesh Component > Optimization > Visibility Based Anim Tick Option]
-
-
在编辑器中检查infiltrators,因为它们用于frustum culling tests。启用[Show>Advanced>Bounds],然后多选相关骨架网格。
-
物理asset视为骨架的“根”,是游戏内bound的一部分。例如,infiltrator移动得更远的射击动画只会扩展bound,如下图所示。
-
在从骨骼中移除根节点后,我们得到了更紧密的拟合,从而大大改进了frustum culling。
-
要删除根,请执行以下操作:
-
双击asset,打开Skeletal Mesh editor
-
选择右上角的 Physics
-
选择 Skeleton Tree下的toot
-
禁用 [Details > Body Setup > Consider for Bounds]
-
之前: Infiltrator bounding boxes延伸回根。

之后:更紧密的bounding box会导致更有效的对象剔除

◐ 12. 帧卡顿
概括言之:消除运行时着色器编译
PSO缓存——提前收集着色器数据,并将其构建到应用程序中,以便在启动时编译着色器。即时编译可能会对CPU造成负担,并导致暂时的帧速率降低或故障。
第一运行《Showdown》出现了非常明显的卡顿,而在第二次却没有。 Unreal Insights将卡顿显示为PSO Vulkan Creation。你可以在FPS图中看到OVR指标的变化。当使用正确生成的PSO缓存构建时,整个序列第一次运行时没有卡顿。这对VR应用尤其重要,因为即使是小幅卡顿,用户都会非常容易察觉

有关设置的详细信息,请参阅这个Unreal文档。你需要构建一个特殊的build,并在整个应用程序中运行,从而收集PSO数据。所以,请等到项目接近完成后再进行这一操作。一旦配置完成并且如果需要,再次捕获缓存数据就会相当简单。
《Showdown》资源包括GenerateSpocache。bat处理从头显中提取数据文件、构建csv,并将其移动到项目目录进行打包。你可以修改这个脚本的参数,以便在自己的项目中使用。
◐ 13. 结论
以上是我们优化《Showdown》并将其带到Quest 2的过程。希望这个经验分享可以帮助你更好地将PC VR项目移植到Quest 2,找到CPU和GPU瓶颈,以及相应地优化应用程序。相关项目请访问GitHub。另外,如有任何问题,请随时访问Oculus开发者论坛。