Meta专利分享用机器学习模型改进Avatar面部重投影

利用机器学习模型来改进重投影面部的方法
(映维网Nweon 2022年04月21日)由于头显遮挡的原因,系统一般难以映射用户完整的面部并重建被遮挡的面部区域。对于这个问题,行业一直在进行探索。实际上,如果你曾阅读《Meta 50年征途:Codec Avatars,创造逼真虚拟角色》一文,你就会知道这家公司一直在积极探索所述问题。
日前,美国专利商标局又公布了与前面所述相关的又一份的Meta专利申请。简单来说,名为“Camera reprojection for faces”的发明主要描述了利用机器学习模型来改进重投影面部的方法。
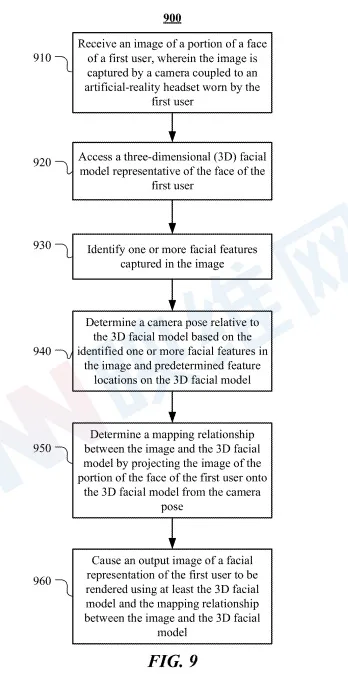
在一个实施例中,人造现实系统可以搭载一个或多个用于捕获用户面部特征的朝内摄像头。图像中的landmark可用于变形面部模型,并且用于为面部模型的相应部分创建纹理。作为一个示例,可以提供一个平均面部模型。当用户穿戴头显时,朝内摄像头可以捕获用户嘴唇区域的图像。可以检测图像中的landmark并与面部模型匹配,以确定摄像头相对于面部模型的姿态(位置和方向)。捕获的图像可以从摄像头重新投影到面部模型,以确定图像与面部模型几何体之间的映射。通过面部模型、用户整体面部的静态纹理和基于捕获的图像生成的动态纹理,人造现实系统可以从期望的视点渲染虚拟化身的完整面部模型。
......(全文 3095 字,剩余 2644 字)











