致力逼真角色,Meta为Codec Avatar解码提出硬件加速器框架F-CAD

Codec Avatar
(映维网 2021年12月23日)Meta一直致力于名为Codec Avatar的虚拟化身项目,从而帮助克服人与人之间,以及人与机会之间的物理距离挑战。借助突破性的3D捕获技术和人工智能系统,Codec Avatar可以帮助人们在未来快速轻松地创建逼真的虚拟化身,令虚拟现实中的社交联系变得如同现实世界般自然和常见。尽管虚拟角色多年来一直是游戏和应用的主要元素,但这家公司相信逼真的虚拟表现将会改变一切。
对于这个项目,团队早前已经多次分享过相关的研究进展。日前,Meta又通过名为《F-CAD: A Framework to Explore Hardware Accelerators for Codec Avatar Decoding》的论文介绍了用于为Codec Avatar解码探索硬件加速器的框架F-CAD。
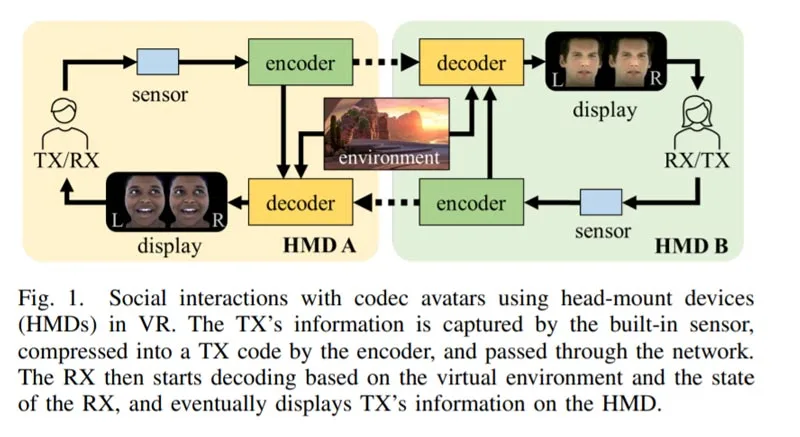
整个系统如图1所示,其中发射机(TX)的所有信息(例如扭曲的微笑和皱眉)将在到达接收机(RX)后进行编码、发送和解码,以生成用于高保真社交临场感的Codec Avatar。其中,解码器是最复杂的模块,占整个系统所需计算量的90%。如果没有有效的优化,它将轻易成为瓶颈,阻碍虚拟现实临场感的顺利实现。随着VR/AR耳机的普及,社会需求不断增加,对实时和高质量编解码器-化身解码的要求也越来越高。然而,在虚拟现实耳机上部署编解码器-化身解码器带来了重大挑战。
......(全文 3482 字,剩余 3055 字)











