Meta研究将头部运动数据作为监控信号进行AR/VR用户行为识别

将头部运动数据作为自我监控信号来进行自中心行为识别
(映维网 2021年12月14日)随着Oculus和HoloLens等头戴设备的出现,AR/VR技术正在开始蓬勃发展。就像过去几十年的电脑智能手机一样,AR/VR设备有望从根本上改变我们的日常生活和社会。为了实现这个未来,需要解决的一个基本挑战是以自中心(egocentric)动作识别,亦即通过头戴式摄像头实现对用户活动的机器理解。
随着现代计算机视觉技术的进步,现在人们熟悉的动作识别方法是使用数百万手动分类为自中心动作的视频片段,并以有监督的方式训练卷积神经网络(CNN)。然而,这种方法至少有两个局限性。第一,注释足够大的视频剪辑来训练CNN非常昂贵;第二,即使拥有无限的预算,我们都无法涵盖人类所有的潜在动作。
要解决所述限制,一个富有前景方法是使用自监督学习(SSL)来训练CNN,而所述领域已经取得了快速的进展。SSL不依赖人工注释,而是利用数据中存在的固有属性来训练各种下游任务的表示,例如对数据增强的不变性、数据的多模态等等。受其启发,Meta和印第安纳大学的团队在名为《How You Move Your Head Tells What You Do: Self-supervised Video Representation Learning with Egocentric Cameras and IMU Sensors》的论文中尝试将头部运动数据作为自我监控信号来进行自中心行为识别。
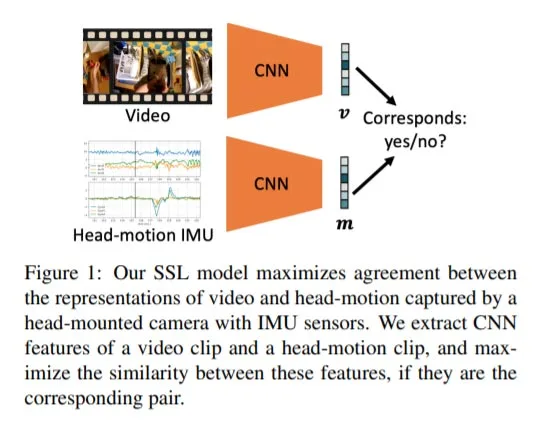
为了利用头部运动数据的潜力并实现自中心视频表示的SSL,团队需要回答几个基本问题:头部运动数据是否具有自中心视频表示无法捕获的唯一信息?如果是这样,利用头部运动中的有用信号进行自中心视频表征学习的有效方法是什么?最后,学习到的表示是否比在仅视频数据上使用SSL进行训练的表示更有效?
在研究中,Meta和印第安纳大学的团队系统地回答了所述研究问题。实验表明,头部运动可以提供额外的优势,即使是完全监督学习都是如此。
然后,研究人员设计了一种简单但有效的SSL方法,通过根据视频对和头部运动数据的对应关系进行分类来学习以自中心的视频表示。团队使用这种方法在EPIC-KITCHENS数据集训练了相关模型,并展示了对厨房任务操作进行分类的结果表示的有效性。另外,研究人员同时利用相同的表征来识别由狗狗头部运动引起的自中心动作,从而证明学习到的表征可以泛化到训练领域之外。
......(全文 2854 字,剩余 2064 字)