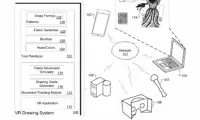
基于3D视频重建虚实场景交互,Meta提出3D mask volume

输入视频来自静态的双目摄像头,并且新视图大多是从输入视频中推断出来
(映维网 2021年11月04日)视图合成的最新进展显示了从图像创建沉浸式虚拟体验的出色结果。尽管如此,为了重建与虚拟场景的忠实交互,我们非常需要结合时间信息的能力。
在名为《Deep 3D Mask Volume for View Synthesis of Dynamic Scenes》的论文中,已改名为Meta的Facebook和加利福尼亚大学研究了一种特定的设置,其中输入视频来自静态的双目摄像头,并且新视图大多是从输入视频中推断出来。团队相信,随着双摄像头和多摄像头智能手机越来越受欢迎,这种情况将非常有用,而且可能会对3D电话会议、监控或虚拟现实头显带来非常有趣的影响。另外,研究人员可以从静态摄像头装置中获取数据集。

尽管可以在每个单独的视频帧应用最先进的图像视图合成算法,但结果缺乏时间一致性,并且经常显示闪烁伪影。问题主要来自于看不见的遮挡区域,因为算法在每帧基础上预测它们。由此产生的估计在整个时间维度上不一致,并且在视频中显示时会导致某些区域变得不稳定。
......(全文 1878 字,剩余 1491 字)