Facebook探索为AR/VR构建高保真服饰效果的全身化身模型

通过可轻松访问的驱动信号来动画化照片级真实感的穿衣化身
(映维网 2021年08月04日)可动画的照片级真实感数字人类是实现社交临场感的关键能力,并可以为远程联系开辟一条全新途径。长期以来,计算机图形学界一直在研究数字人类化身的构建问题。人体建模的早期研究是用最低限度的衣物来构建人体表面的低维几何表示。不过,过往的研究大多只关注于几何体的建模,不能直接产生真实感的渲染输出。即使采用了基于神经网络的数据驱动方法,为照片级真实感衣物人体制作动画依然是一个远未解决的问题。
在名为《Explicit Clothing Modeling for an Animatable Full-Body Avatar》的论文中,卡内基梅隆大学和Facebook Reality Labs Reaserch的研究人员尝试通过可轻松访问的驱动信号来动画化照片级真实感的穿衣化身,例如三维身体姿势和面部关键点。

利用诸如Variational Autoencoders(VAE)这样的深度生成模型来同时建模几何体和纹理已证明是创建照片级真实感人脸化身的有效方法。最近业界已经扩展了这种方法,以身体姿势和面部关键点为条件,通过VAE对全身化身进行建模。由于所述条件信号不能唯一地描述所有的身体状态,如头发和注视点,VAE隐代码用于区分多个可能的身体阶段。另外,为了减少驱动信号和隐码之间的伪相关,必须对驱动信号和隐码进行分离。
尽管先前的研究已经取得了进展,但在构建高保真的可动画全身化身方面依然存在挑战,团队将衣物建模确定为一个主要困难。可以观察到的伪影包括身体姿势和衣物状态之间的不完全相关性、衣物和皮肤边界的重影效果、以及严重的皱纹细节和动态损失等等。当捕获到的衣物松散且表现出高动态性时,这种伪影会变得更加明显。一方面,由于配准的挑战,网络可能会对数据拟合不足,无法再现高频衣物细节;另一方面,尽管有解耦,但网络依然可能会过度拟合,捕获驱动信号和衣物状态之间不必要的机会相关性。
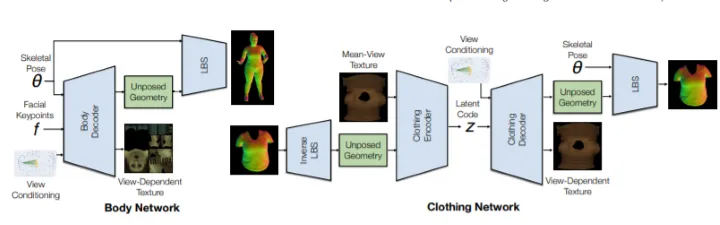
为构建一个可用于穿衣人体的动画化身,团队提出了一种两层网格表示方法。结果表明,显式衣物建模不仅提高了衣物的渲染质量,而且实现了衣物纹理的可编辑性,从而为编解码化身开辟了全新的可能性。穿衣人体的两层配准不成功,就无法获得两层化身模型。所以,团队提出了一种新的穿衣人体配准函数和纹理对齐函数,利用逆渲染来提高光度学对应性。
在这项研究中,研究人员显式地表示身体和衣物作为一个编解码器化身中的单独网格层。这带来了数个好处。首先,能够准确地配准身体和衣物,特别是对于团队新开发的光度追踪方法(使用反向渲染将衣服纹理与参考对齐);第二,在单独层中建模身体和衣物减轻了上述单层化身的机会相关性问题,因为单独层自然地彼此分离。在团队提出的两层VAE中,关节角度的单个帧可以很好地描述身体状态,而衣物动态可以通过Temporal Convolutional Network(TCN)从姿势序列中推断;第三,由于衣物的显式建模,动画输出可以进一步编辑,例如,通过改变衣物纹理。这带来了改变全身化身外观的可能性。
......(全文 2066 字,剩余 1004 字)