比DNR更快更好,Facebook提出ANR铰接神经渲染,让虚拟化身细节更逼真

由美国佐治亚理工学院、德国波恩大学、Facebook Reality Lab和Epic Games组成的团队
(映维网 2021年07月21日)捕捉真实感是计算机视觉的重要目标之一。3D绘制和神经网络的进展带来了具有显著保真度的方法。然而,这通常需要用到昂贵而复杂的捕获设置,从而妨碍了结果模型的简单数字化和传输。最近的Deferred Neural Rendering(DNR)式可以利用不精确的几何体和相对简单的神经着色器来真实地捕捉具有视点相关效果的复杂场景。在第一步中,使用neural latent texture对几何体进行光栅化,然后使用卷积网络将其转换为RGB图像。渲染网络和神经纹理都进行了优化,以产生逼真的结果。
DNR特别适合于刚性对象。它的管道可以以一种自然的方式扩展到可变形对象:可以使用蒙皮网格来捕捉几何体。然后,可以将来自姿态网格的光栅化神经纹理转换为RGB图像。尽管就概念而言十分简单,但神经网络必须学习更复杂的变形相关效果。另外,用于渲染的网格通常不是真实几何体的完美表示,从而导致对齐问题,并限制了DNR在可变形物体场景中的应用。
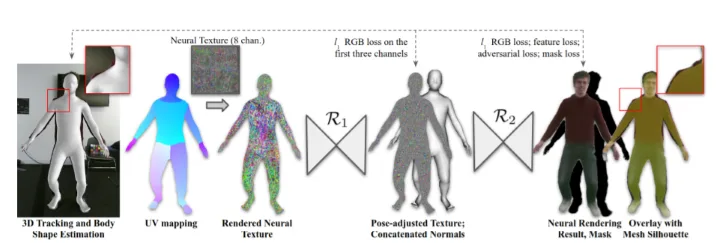
针对这个问题,由美国佐治亚理工学院、德国波恩大学、Facebook Reality Lab和Epic Games组成的团队提出用Articulated Neural Rendering (ANR)来解决所述问题。据介绍,ANR系统地将DNR从神经阴影模型结构重建为优化方案,而团队利用ANR来解决动画中最具挑战性的问题之一:虚拟化身。下图是由ANR渲染的虚拟化身示例。

具体地说,尽管DNR非常强大,但它需要精确的3D几何体来学习与视图相关的外观信息。在实践中很难做出这样的假设,尤其是对于有关节的、穿着衣服的人类外观,而其形状通常由粗略的统计体型模型来表示。ANR采用了一个简单的统计人体模型来捕捉每一帧的体型统计和3D姿势信息。所述身体模型仅表示没有衣服和头发的粗糙身体几何体。所以,直接使用DNR管道会导致失真和模糊的结果。研究人员使用视频中的关键帧来学习神经纹理中编码的静态外观,并使用其他帧来学习外观的动态姿势条件渲染。基于关键帧的训练方案使模型收敛速度比DNR快5倍,并产生了比DNR更好的虚拟化身。团队在一个模型中同时训练多个恒等式的ANR,以致使神经纹理和着色模型的解耦。由于统计体模型具有一致的表面参数化,所述模型可以利用相关语义对应来修改和混合来自多个神经纹理的成分,通过改变神经纹理中的区域来实现虚拟试穿。
尽管研究人员获得的模型只适用于二维,但其通过实验验证,它可以用一个非常小的网络(161M参数)来渲染出接近真实照片效果的持久三维外观。两项用户研究表明,ANR不仅优于DNR管道,而且优于其他多项采用了专门用于创建虚拟化身的方法的管道。在感知上,所述方法具有时间稳定性和良好的外观细节。
ANR可以生成关节对象的高度详细表示。传统的渲染管道使用高分辨率的网格和详细的RGB纹理,而研究人员则使用低分辨率网格和高维神经纹理,并使用一个神经网络从新视图渲染详细的RGB外观。
......(全文 1402 字,剩余 363 字)