Facebook提出无需空间标注的3D空间识别方法WyPR

mIOU比以前的技术高出6%
(映维网 2021年05月24日)在计算机视觉中,理解场景中的对象及其位置是一项标准任务。训练三维空间识别系统通常涉及使用传感器捕捉场景,然后用3D box手动标记场景中对象的空间范围,包括标记它们的位置。尽管人工标注是训练人工智能模型的一种流行且强大的方法,但它非常耗时。在一个小型室内3D场景中,标注和绘制box平均需要20多分钟。如果没有box,而有场景级别标签的集合(如场景中存在的对象列表),为三维场景添加标签会更快更容易。
所以,Facebook人工智能研究院和伊利诺伊大学厄巴纳-香槟分校的研究人员提出,不用空间标注的3D来进行空间识别。
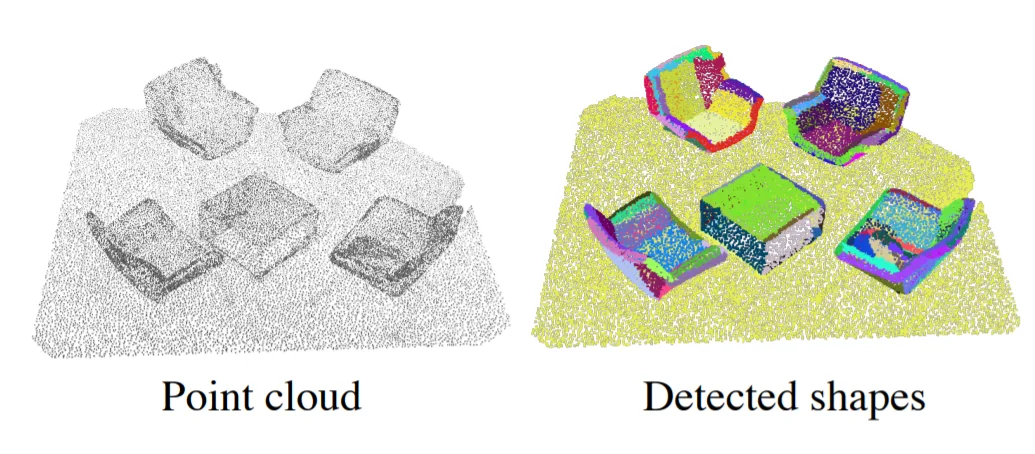
在名为《Recognizing 3D spaces without spatial labels》的论文中,团队主要提出了以下问题:是否可以学习在训练期间仅使用场景级标记(如场景中存在的对象列表)作为监督,然后在三维数据(如点云)中执行空间识别呢,如检测和分割对象?
对于论文提出的WyPR方法,团队证明了通过联合处理分割和检测这两个自然相互约束的任务,其能够学习这种弱监督问题的有效表示。WyPR可以将二维弱监督学习的进展与三维点云数据的独特特性相结合。实验显示,对于具有挑战性的数据集(ScanNet),它的mIOU比以前的技术高出6%。研究人员指出,这为未来的研究建立了新的基准和基线。
◐ 为何重要
空间三维场景理解对于各种下游任务非常重要,如通过AR设备投影坐在餐桌旁的同事。WyPR为模型提供了空间三维理解能力,同时无需在点级标记训练场景(这是一个非常耗时的过程)。通过降低训练数据的障碍,在大量的类中实现更细粒度的理解,WyPR可以帮助系统更容易理解空间3D场景。
三维对象的识别(即分割和检测)是实现场景理解的关键步骤。随着消费者水平深度传感器的发展和计算机视觉算法的进步,三维数据采集变得更加方便和便宜。然而,现有的三维识别系统往往无法扩展,因为它们依赖于强大的监督,例如点级语义标签或三维bounding box(都需要耗时获得)。例如,尽管热门的大型室内3D数据集ScanNet仅由20人收集,但注释工作涉及500多名注释者,每次扫描花费近22.3分钟。另外,由于标注成本高,现有的三维目标检测数据集仅限于少量的目标类。这个耗时的标记过程是阻碍社区扩展3D识别的一个主要瓶颈。
......(全文 1272 字,剩余 477 字)