Facebook详细分享:用精确HRTF可扩展解决方案构建AR空间音频未来

根据耳朵照片生成精确HRTF的可扩展解决方案
(映维网 2020年09月09日)FRLR日前分享了关于沉浸式音频研究方面的最新进展,并表示所述研究“与Facebook实现AR眼镜的工作直接相关”。概括而言,团队的目标是将相关技术应用到AR头显中,并允许你在嘈杂的环境中轻松地隔离人声,同时再现虚拟声音,使其听起来像是来自周围的真实世界。一个定制的头相关传输函数(HRTF)是提供这种体验的关键,但涉及过程耗时且昂贵。所以,FRLR团队正在研究一种能够根据耳朵照片生成精确HRTF的可扩展解决方案。
对于这项研究,Facebook德技术通讯经理丽莎·布朗·贾洛萨(Lisa Brown Jaloza)在一篇名为“音频的未来”的博文对其进行了详细介绍。下面是映维网的具体整理:

正如著名科幻作家阿瑟·克拉克所言:“任何卓越的先进技术都和魔法相差无几。”我最近有幸见证了Facebook施展的最神奇魔术,而下面我将与大家一起分享个中的神奇。
但首先,我们先进行一定的背景介绍。
无论是甜美的爱人言语,抑或是激昂澎湃的歌曲乐章,声音都包含着不同于其他感官体验的丰富情感。然而,这种体验常常会遭到噪音淹没,因距离而减损,或因我们自身听力的局限而丧失。
世界不需要是这样。请想象这样一个未来:穿戴一副VR头显或AR眼镜后你将能运送到千里之外的地点,然后上课、上班或参加亲戚的生日聚会,而一切仿佛就好像是现实生活一样。这种体验称为“社交临场”。今天的技术尚未实现这一承诺,部分原因是声音不够逼真。有多少次你因为嘈杂的背景而不得不重复自己的话语,或是因为分不清谁在说什么而感到糊里糊涂?
即便是身处同一地理位置,环境的类型同样会影响人际关系的质量。嘈杂的背景会妨碍我们,令我们感到沮丧,或者最终不得不大喊大叫。现在想象一下,同样的一副AR眼镜能够将你的听力提升到全新的水平,允许你在诸如餐馆、咖啡店和音乐会等嘈杂的空间里清晰地听到你希望听到的声音。对于你的面对面交流,这将会产生什么影响呢?
Facebook Reality Labs Research(FRLR)正在构建增强现实和虚拟现实的未来。FRLR汇集了一支由研究科学家、工程师、设计师等组成的跨学科音频团队,并致力于通过激进的音频创新来改善人类交流。这个小组的任务包括两个:创造在感知方面无法与现实区分的虚拟音效;重新定义人类的听觉能力。为了做到这一点,研究人员致力于提供两种新功能:第一,音频临场感,亦即虚拟音效的来源仿佛是与听者存在于同一空间,其保真度之高以至于你无法将真实世界的声源区分开来;第二,感知超能力,亦即即便是在嘈杂的环境中,你将能够将交流对方的音量调大,并对不需要的背景噪音调低,从而提升我们的交流体验。

这支世界最大的音频研究团队之一正在探索各种相互关联的研究问题。在短短六年的时间里,原本只有一个人的队伍已经成长为世界级的专家团队。由拉维什·梅赫拉(Ravish Mehra)领导的FRLR音频研究团队致力于解决新颖的研究问题,提出解决方案,并通过令人信服的体验来证明它们。我有幸体验了其中的一些体验,而它们对未来音频通信的影响十分惊人。这是一个关于未来通信的故事,并需要发明一套全新的硬件和软件技术,从而提供逼真的具现体验。
◐ 1. 耳听为实:音频临场感
尽管小时候希望长大后能够成为一名摇滚明星,但研究科学家帕布罗·霍夫曼(Pablo Hoffman)如今更接近于一名魔术师。他成功地开发了一个始终在线的音频校准系统,并且可以有效地允许你通过一对耳机听到超高保真度的声音。这个演示采用了FRLR的全新算法和软件处理技术,以及现成的硬件来展示个性化音频和重现房间的声学效果。
我坐在他位于华盛顿州雷德蒙德的办公桌旁。霍夫曼递给我一副耳机,而麦克风专门放到我耳朵的入口处。在接下来的两分钟里,所述麦克风将从我的视觉记录房间的声音。这位研究科学家从不同的地方大声而温柔地说话,他甚至会弹吉他,并且一度把钥匙丢到我的身后。

然后霍夫曼播放了录音。音效非常逼真,和真实几乎没有什么区别。事实上,对于坐在他旁边的我而言,我敢打赌当我瞄到他的时候他一定有在说话。但当我正眼看着他时,我能看到霍夫曼的嘴唇没有动。来自霍夫曼方向的声音完全是人工合成。这是两分钟长的既视感(Deja-vu)。
这正是感知方面与现实无法区分的虚拟音效。当你亲身见证的时候,它就像是一种为善的魔法。研究负责人菲利普·罗宾逊(Philip Robinson)解释说:“‘感知方面无法区分’说起来十分简单。但当你亲耳听到的时候,这会是一种无比神奇的感觉。”
◐ 2. 逼真音频的秘方
当有人在房间里跟你说话时,你的一只耳朵会先于另一只耳朵听到声音。每只耳朵的音量不同。另外,耳朵的形状改变了我们每个人听到声音的方式。所有这些信号都在告诉大脑声音来自哪里。声音与你的环境相互作用,在进入你的耳朵之前从墙壁反弹。这一切都是核心要素。如果能精确再现,虚拟声音就能复制真实声音。
2017年,音频研究团队帮助研发了空间化音频,亦即一种模拟真实声音来源的虚拟音效。团队同时发明了能够提高虚拟环境可信度的高质量声学模拟技术。这些技术推动了空间音频技术的发展,并驱动着当今Quest和Rift平台的众多体验,包括《First Steps》和《Oculus First Contact》。下一个前沿领域是个性化的空间音频,以及模拟声音与真实环境交互的方式。在我参观雷德蒙德实验室的后面两站旅程中,团队向我展示了他们在两个方面的进展。
◐ 3. 个性化空间音频
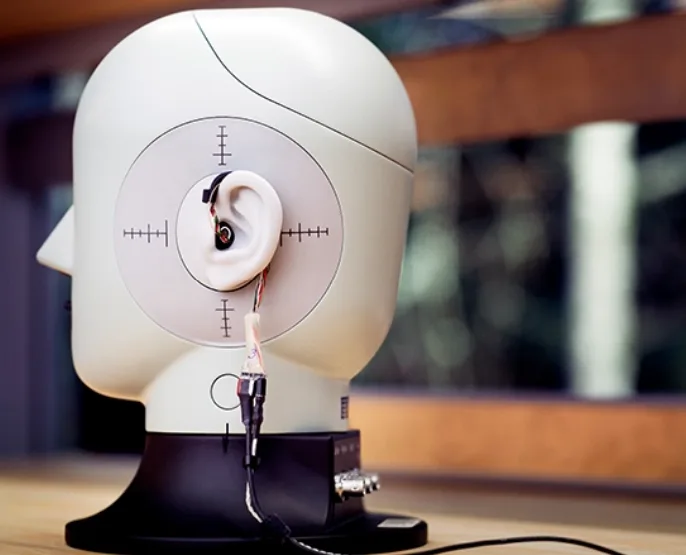
一位研究人员带我进入一个消声室。这是一个价值数百万美元的设施,它与周围的建筑相隔3英尺宽的空气间隙,而四周4英寸厚的钢板可吸收所有回声。房间非常安静,你甚至可以听到自己的心跳。一个包含54个扬声器的机械臂从上到下地进行360度的自由旋转,并且一边播放音调,从而测量声音对我耳朵的独特几何形状的反应。整个过程大约需要半个小时。最后,我可以看到我的个人听觉空间化音频体验的数字表示,亦即头相关传输函数(HRTF)。目前用于游戏和虚拟现实的解决方案属于“通用式”HRTF,它不能为每个人提供完美的空间精度。个性化的HRTF测量克服了这一局限性,并允许每个人真正听到仿佛真实声音一般的虚拟声音。
尽管消声室显然不是捕获个性化HRTF的可扩展解决方案,但音频研究小组正在考虑几种全新的方法。作为一个例子,他们希望有一天能开发出一种可以根据耳朵照片来近似一个可行的个性化HRTF的算法。

◐ 4. 为房间的声学建模
理解声音如何在特定空间中传播,并在到达耳朵之前从相关表面反弹,这是另一个帮助虚拟声音复制真实声音的有力工具。就如同视觉AR使用SLAM技术来获取虚拟对象的几何和光照一样,我们在声音方面同样需要理解房间的声学特性,以便将虚拟声源无缝地放置到真实的空间之中。团队邀请我尝试一款游戏,并确定哪些声音来自房间中的物理扬声器,哪些是来自我所穿戴的耳机。我可以在空间中移动,并感受相应的声音响应。我感觉自己有点像是音频发烧友,但对于我区分哪些声音是真实,哪些声音是虚拟的努力,我只能做到50-50的水平。尽管是来自耳机,但空间化的音频和模拟的声音是如此逼真,我的大脑完全相信我听到的声音是来自于房间的扬声器。我甚至不得不拔下耳机来确认声音的真正来源。
罗宾逊表示:“想象一下,如果你在打电话,你会认为对方就在身边,你会忘记你们实际上是相隔两地。这就是我们正在开发的技术的愿景。”
为了明确这里的利害关系,团队向我展示了一个关于远程临场感的演示,即感觉你仿佛是置身于另一个的位置。我坐在一个房间里并穿戴一个定制的Oculus Rift头显和一副耳机,但我感觉自己是在另一个地方,和众多研究人员和同事围坐在一张桌子旁。我可以通过头显看到会议室。32个麦克风阵列会捕获会议室的声音,并将空间化的音频直接传送到我的耳机中,这样每个人的声音听起来都像是来自桌子旁边的特定位置。我发现自己能够十分自然地转向每一个人。这有助于我跟踪和参与谈话,令我感觉自己就在房间里面(即使我实际上不在那里)。
这可能会颠覆你与远方家人,朋友或同事所进行的视频通话。对于今天的通话,对方的声音听起来像是从电话里传来,所以大脑否定了对方可能和你位于同一位置的想法。空间音频模拟现实生活中的声音和环境声学的方向,所以你可以更为充分地感受社交临场感。
当空间音频与Codec Avatars(可实时动画化的超逼真人类表示),超现实的三维重建,全身追踪,共享虚拟空间等结合在一起时,我们将能够解锁真正的社交临场感。通过允许你和对自己最为重要的家人或朋友置身于同一空间,我们可以从根本上改变你的生活、工作和娱乐方式。
罗宾逊说:“我一直牢记Facebook的总体使命,亦是联结彼此。我们需要令虚拟音效如同现实一般的唯一原因是,我可以令一个虚拟人类出现在面前,并与其进行社交互动,就像对方真的是和你置身于同一空间。对于远程交流或面对面交流,即便只是改善一点点,它都能够真正促成更为深入、更具影响力的社交关系。”
尽管逼真的空间化音频和逼真的室内声学令人感到心旷神怡,但这只是FRLR音频团队任务的第一块拼图。梅赫拉解释道:“当我们开始在虚拟现实中进行这项研究时,随着虚拟现实技术的发展,我们意识到我们在这里构建的所有技术都是致力于实现一个更高的目标:改善人类的听觉能力。”
◐ 5. AR眼镜和感知超能力
对于FRLR音频团队的使命,第二块拼图是重新定义人类听觉能力。当然,这是一个雄心勃勃的目标。不过,这同时与Facebook的AR眼镜努力直接相关。
负责硬件研究的托尼·米勒(Tony Miller)解释道。“人类听觉是一种惊人的感觉,它允许我们通过口头语言和音乐表达进行联系。FRLR正在探索可以扩展、保护和提高听觉能力,加强注意力,同时支持你与你关心的人和信息无缝互动的全新技术。这项研究的核心是致力于构建深深植根于听觉感知,并通过信号处理和人工智能的最新发展加以增强的硬件。”
想象一下,你可以在拥挤的餐厅或酒吧里自由交谈,不必提高嗓门或紧张兮兮地过分关注别人的言语。通过眼镜搭载的多个麦克风,系统可以捕捉到你周围的声音。然后,利用你的头部和眼睛运动模式,系统可以确定你最感兴趣的声音,从而为你增强正确的声音,并衰减其他声音。通过这样的方式,团队希望确保你真正希望听到的声音是清晰明朗,即使周围充斥着吵闹的背景噪音。
◐ 6. 所见即所闻
为了体验这一点,我和研究科学家欧文·布里米金(Owen Brimijoi)坐在一间模拟餐厅的房间里。我戴着耳机和现成的眼动追踪装置,而眼动追踪是FRLR正在探索的几种解决方案之一。布里米金开始讲话时,研究小组提高了背景噪音水平。令我惊讶的是,我依然可以很容易地听到他的话语,而且交谈十分自然。当我看着角落里的电视时,它正在播放的广告声音会越来越响,而其他声音则变得越来越安静。当布里米金再次开口说话时,我再次转向他,然后我们的谈话又重新开始。与霍夫曼的演示一样,所述演示是将FRLR的软件与现成硬件配对以说明增强听力的体验。

喧闹的餐厅不仅令人讨厌,同时会给员工带来潜在的健康风险。事实上,如果长时间暴露在85分贝以上的噪音环境中(现在不少餐馆和酒吧都超过了这一水平),这会造成我们的听力会下降。通过降低噪音,我们或许可以帮助保护人们的听力。
◐ 7. 新颖的输入:捕捉声音
接下来,团队向我展示了一种叫做近场波束形成技术的创新应用,而它再次令我感觉自己仿佛时在见证一个魔术。但这次他们使用了FRLResearch开发的定制硬件。研究科学家弗拉基米尔·图尔巴宾(Vladimir Tourbabin)戴着一副简单的3D打印眼镜,但其搭载了一个特殊的麦克风阵列,一种输入原型。房间里有几个物理扬声器以最大音量播放音乐。我在另一个房间,图尔巴宾打电话给我。我拿起话筒,他开始用正常的声音诵读一篇在线文章,而嘈杂的房间里的噪音非常容易淹没图尔巴宾的声音。
然后图尔巴宾打开了一个开关,突然之间,我清能够晰地听到他的声音传来,仿佛某人将背景音量调低了一样。就像在摇滚音乐会或地铁站接到一个朋友的电话,但不知怎么回事,我居然可以清晰地、明白地听到对方的声音。这一切都是因为上面提到的麦克风阵列将他的声音与周围的噪音隔离开来。你可以想象未来这项技术可允许我在嘈杂的房间里与人工智能助理清晰地通话,这可以为我提供更多的隐私和安全,并防止我的助手意外地拾取周遭人和物的声音。
◐ 8. 输出:控制音量
音频团队的目标是覆盖人类能听到的所有声音,从20赫兹到20000赫兹。FRLR目前正在开发一种特殊的入耳式监听器(in-ear monitor;IEM)。这种输出原型将允许我们使用主动降噪技术来有效地降低背景噪声的音量,从而帮助人们在嘈杂的环境中更清晰地、更安全地听到声音。当与FRLR的输入原型(包括麦克风阵列)相结合时,这将能够提供听觉超能力的全面体验。
音频体验负责人斯科特·赛尔丰(Scott Selfon)解释说:“我们的IEM同时具有感知透明的听觉功能,仿佛我耳朵里什么都没有,而我能够安全地听到周围的整个世界。”类似于霍夫曼早期的演示,但这次只是使用了一个小小的耳机。
◐ 9. 改善生活
这项研究的潜能十分巨大。尽管大多数感知超能力研究都集中在改变每个人的交流,但团队相信其中一些可以为听力科学领域的新研究提供支持。据约翰斯·霍普金斯大学研究称,美国有大约五分之一的人口存在听力损失问题。他们中的许多人都不使用助听器,原因有很多,包括费用,社会耻辱感,不适和缺乏可靠性。
最近,研究小组迎来了著名的听力科学家托马斯·伦纳(Thomas Lunner)。他早前的研究为1995年世界第一台数字助听器奠定了基础,而他将进一步探索这条研究道路。伦纳表示说:“通过将听力受损人口与听力正常的人员至于平等的地位,我们可以帮助他们更积极地参与社交活动。这与Facebook的使命非常契合,因为失聪常常致使人们远离社交场合。”
技术项目经理阿曼达·巴里(Amanda Barry)补充道:“我从小就戴着助听器。能够在人们变老且听力衰退时帮助他们与家人保持联结的能力令人感到无比兴奋。”

听力科学是Facebook独立于AR研究所探索的一个领域。它具有独特的挑战,而团队希望能够帮助推动科学前进。FRL计划在日后分享更多的研究成果进步。
◐ 10. 我们十分关注隐私
要帮助智能AR眼镜取得成功,我们需要深思熟虑地、负责任地开发技术。尽管依然处于研究的早期阶段,但FRLR已经开始探索确保用户隐私和安全的方法。当我们努力提高人们的声音体验时,我们必须保持对社会规范的认识和尊重。

梅赫拉指出:“我们的目标是在我们的创新周围设置护栏,以负责任的方式进行创新,所以我们已经在考虑我们可以采取的潜在保障措施。例如,在我提高某人的声音之前,我的眼镜可能需要遵循一个协议并请求对方眼镜的允许。”
研究小组强烈意识到的另一个问题是,敏感耳朵数据的捕获,包括研究阶段及以外。今天,在我们将收集到的任何数据提供给研究人员之前,所有数据都会经过加密,研究参与者的身份与数据分离。一旦收集,数据将存储在安全的内部服务器中,只有少数拥有明确权限的研究人员能够访问相关服务器。团队同时定期与隐私、安全和IT专家进行审查,以确保遵守协议并实施适当的保护措施。
“Deepfake”是我们正在思考的另一个问题。这种技术可以使用人工智能和预先存在的镜头来编造一个场景,比如一个人会说出实际上从未说过的话语。例如,我们正在讨论在耳机和眼镜中构建强大的身份验证技术(如面部分析),从而确保只有你本人可以通过你的设备访问与你的声音绑定的虚拟化身。”
梅赫拉说道:“显然,我们离在眼镜和耳机中实现这类技术尚有一段距离,但我们希望思考这些技术的影响,以及与更广泛社会相关的潜在解决方案。这同时是我们现在讨论这项研究的原因之一。我们致力于将其公开化,并就这项技术的可接受用途进行公开讨论。”
假如你可以忽视背景噪音或距离并轻松地听到对方说话,假如你不必因为差旅问题而错过特殊活动,假如你能用一个可穿戴设备取代你的高端立体声系统、电视、手机……
这是我们相信的未来,我们正在努力使之成为现实。
◐ 11. 下一个前沿:听觉机器感知
最终,我们的主要目标之一是提供一款时尚的AR眼镜。它不仅可以理解周围的视觉世界,同时可以理解周围的声学世界,并利用相关知识和背景帮助你在世界各地导航。为此,我们将使用一个包含共享和私有组件的虚拟地图LiveMaps。对声学声景的理解可以为地图添加信息,这样人工智能就可以改善你的音频体验,同时能以其他方式帮助你。例如,当你走进一家餐馆时,你的AR眼镜能够识别出发生在你周围的不同类型的事件:人们在交谈,空调的噪音,盘子和银器的叮当声。然后利用情境化的人工智能,你的AR眼镜将能够做出明智的决定,比如消除分散注意力的背景噪音。
赛尔丰补充说:“我们的AR眼镜的另一个机遇是,它不仅可以帮助我们更好地听到,而且可以帮助我们更好地理解。如果我因为背景噪音或语言障碍而无法跟踪对话,我们可以使用情境化人工智能和语音识别来帮助我进行实时的视觉转录或翻译。而且,与家里柜台的语音助手不同,随身携带的AI助手将具有完整的情景意识。因此,当你身处嘈杂的环境中时,它可以自动提高声音,或者在图书馆等需要安静的地方轻声说话。”
这是我们刚刚开始探索的另一个领域,而我们将在日后分享更多的消息。
梅赫拉表示:“我们现在正处于AR/VR技术发展史上的关键时刻。如果是5年或10年后加入这个领域,他们只是跟在我们屁股后面。对于这一刻,我们实际上正在定义未来。我们可以提高体验的真实感,以至于你不必为了参加会议或与你所爱的人联系而旅行数百或数千英里。我们可以制造出用来改善人类听力的技术。如果你对这一点充满激情,我们就是你要加入的团队,而且现在是时候让它成为现实了。”