谷歌用MediaPipe实现手机高效实时3D对象检测

基于2D图像的3D对象检测依然是一个十分具有挑战性的课题。
(映维网 2020年03月12日)对象检测是一个广泛研究的计算机视觉问题,但大多数研究都集中在2D对象预测方面。2D预测仅提供2D边界框,但通过将预测扩展到3D,我们可以捕获对象的现实世界大小,位置和方向,从而在机器人技术,自动驾驶汽车,图像检索和增强现实等领域实现一系列的用例。尽管2D对象检测相对成熟并已在行业中广泛应用,但由于缺乏数据,以及对象外观和形状的多样性,基于2D图像的3D对象检测依然是一个十分具有挑战性的课题。
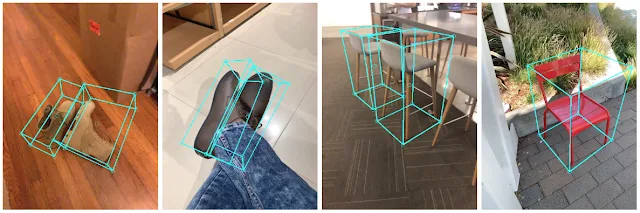
针对这个问题,谷歌日前发布了用于日常对象的实时3D对象检测管道MediaPipe Objectron。所述工具可以检测2D图像中的对象,并利用由新建3D数据集进行训练的机器学习模型来估计其姿态和大小。MediaPipe是一个开源代码跨平台框架,主要用于构建用于处理不同形式的感知数据的管道,而Objectron在MediaPipe中实现,并能够在移动设备中实时计算面向对象的3D边界框。
根据单张图像进行3D对象检测。MediaPipe Objectron可以支持确定移动设备实时确定日常对象的位置,方向和大小。
1. 获取真实世界3D训练数据
由于依赖于3D传感器(如LIDAR)的自动驾驶汽车研究日益普及,业界存在用于街景的大量3D数据,但包含面向日常对象的ground truth 3D注释的数据集依然非常有限。为了克服这个问题,谷歌团队利用移动增强现实会话数据开发了一种全新的数据管道。随着ARCore和ARKit的到来,数亿智能手机现在已经具有AR功能,并且能够在AR会话中捕获更多信息,包括camera姿态,稀疏3D点云,估计照明和平面。
为了标记ground truth数据,团队构建了一个新颖的注释工具以搭配AR会话数据,从而允许Annotator可以快速标记对象的3D边界框。工具利用分屏视图来显示2D视频帧,在左侧叠加3D边界框,并在右侧显示3D点云,camera位置和检测平面。Annotator在3D视图中绘制3D边界框,并通过查看2D视频帧中的投影来验证其位置。对于静态对象,我们只需要在单帧中注释对象,并使用来自AR会话数据的ground truth camera姿态信息将位置传播到所有帧。这可以大大提高过程的效率。
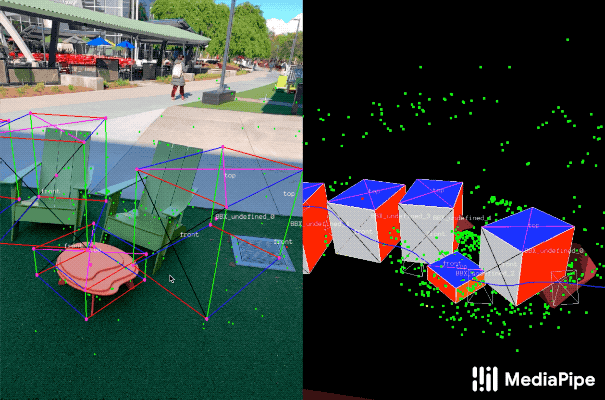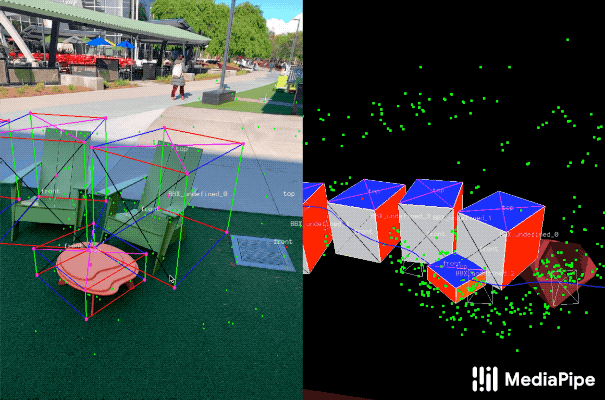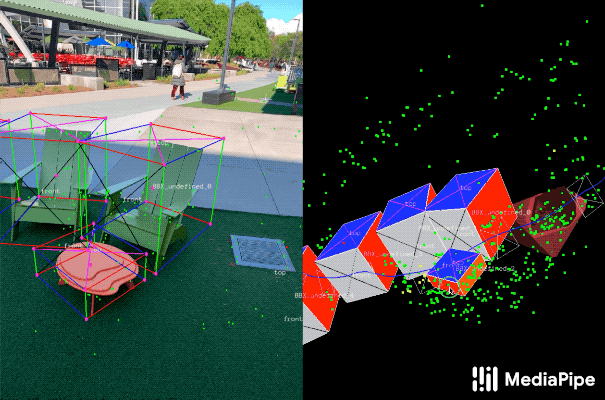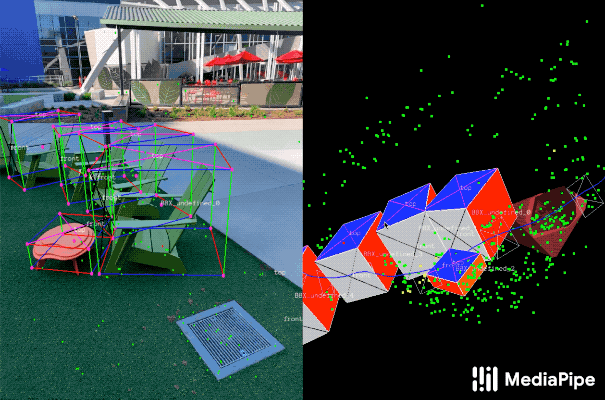
用于3D对象检测的真实数据注释。右:在3D世界中检测表面和点云标注3D边界框。左:带注释3D边界框的投影叠加于视频帧,从而便以验证注释。
2. 增强现实合成数据生成
为提高预测的精度,一种流行的方法是用合成数据补充现实世界的数据。但这种方式做通常会带来糟糕的,不真实的数据,或者在图像真实感渲染时需要大量的精力和计算量。所以谷歌提出了一种名为AR Synthetic Data Generation(增强现实合成数据生成)的新颖方法。它可以将虚拟对象放置到具有AR会话数据的场景中,允许你利用camera姿态,检测平面和估计照明来生成物理可能的位置,以及具有与场景匹配的照明。这种方法可生成高质量的合成数据,其包含的渲染对象能够尊重场景的几何形状并无缝地适配实际背景。通过结合现实世界数据和增强现实合成数据,谷歌表示精度提高了约10%。

增强现实合成数据生成的一个示例:虚拟白褐色谷物盒渲染到真实场景中,紧邻真实蓝皮书。
3. 用于3D对象检测的机器学习管道
为了从单个RGB图像预测对象的姿态和物理尺寸,谷歌构建了一个单阶段模型。所述模型主干具有基于MobileNetv2构建的编码器-解码器架构。团队采用多任务学习方法,通过检测和回归来共同预测对象的形状。形状任务根据可用的ground truth注释来预测对象形状信号。这属于可选选项,可用于训练数据中缺乏形状注释的情况。对于检测任务,团队使用带注释的边界框并将高斯拟合到框,中心位于框质心,标准偏差与框大小成正比。回归任务估计八个边界框顶点的2D投影。为了获得边界框的最终3D坐标,团队利用了完善的姿态估计算法(EPnP)。它可以恢复对象的3D边界框,无需事先知晓对象的尺寸。给定3D边界框,团队可以轻松计算对象的姿态和大小。下图是具体的网络架构和后处理。所述模型非常轻巧,可以支持移动设备实时运行(在Adreno 650移动GPU为26 FPS)。
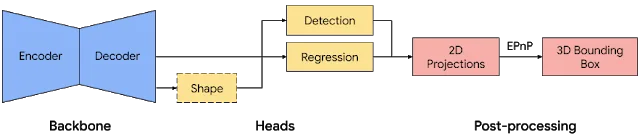
用于3D对象检测的网络架构和后处理。

网络的样本结果:左边是带有估计边界框的原始2D图像;中间是高斯分布的对象检测;右边是预测的分割蒙版。
4. MediaPipe中的检测和跟踪
当将模型应用于移动设备捕获的每个帧时,由于每帧中估计的3D边界框的歧义性,模型可能会遭受抖动影响。为了缓解这种情况,谷歌采用了最近发布在2D object detection and tracking(2D对象检测和跟踪)解决方案中的检测+跟踪框架。所述框架能够减轻在每帧运行网络的需求,从而支持计算量更大但因而更为准确的模型,同时在移动设备保持管道实时进行。它同时可以跨帧保留对象身份,并确保预测在时间方面维持一致,从而减少抖动。

为了进一步提高移动管道的效率,团队只是每隔几帧运行一次模型推断。接下来,谷歌利用以前介绍过的方法进行预测并随时间进行跟踪。当做出新的预测时,他们将根据重叠区域把检测结果与跟踪结果合并。
鼓励开发者和研究人员根据其管道进行实验和原型设计,谷歌将在MediaPipe中发布所述的机器学习管道,包括端到端的移动演示应用,以及针对鞋子和椅子这两个类别的训练模型。谷歌表示:“我们希望通过与广泛的研究和开发社区共享我们的解决方案,这将能够刺激新的用例,新的应用和新的研究工作。我们计划在未来将模型扩展到更多类别,并进一步提高设备性能。”










