谷歌用机器学习实现稳定实时的手部追踪、手势识别

稳定的实时手部感知是一项极具挑战性的计算机视觉任务。
(映维网 2019年08月21日)感知手部形状和手部运动的能力可以改善各个技术领域和平台的用户体验。例如,它可以形成手语理解和手势控制的基础,并且可以在增强现实情景中实现物理世界的数字内容与信息叠加。尽管这对人类而言十分自然,但由于经常出现遮挡情况(如手指/手掌遮挡和手抖)和缺乏高对比图案,稳定的实时手部感知是一项极具挑战性的计算机视觉任务。
谷歌近期发布了一种用于手部感知的全新方法。实际上,谷歌已于六月的CVPR 2019大会进行过预览,而这项技术是在MediaPipe中实现(一个开源的跨平台框架,主要用于构建处理不同模态感知数据的管道,如视频和音频)。这种方法通过机器学习从单帧推断出手部的21个3D关键点,从而提供高保真度的手部和手指追踪。目前最先进的方法主要依靠强大的桌面环境进行推导,但谷歌的方法可以为手机端带来实时性能,甚至可以扩展到多手用例。谷歌表示:“通过为更广泛的研究和开发社区提供这种手部感知功能,我们希望这可以带来更具创造性用例出现,并刺激新的应用程序和新的研究途径。”

◐ 1. 一种用于手部追踪和手势识别的机器学习管道
谷歌的手部追踪解决方案利用了由多个模型组成的机器学习管道:
- 手掌检测器模型(名为BlazePalm):对整个图像进行操作,并返回定向手部边界框。
- 手部界标模型:在由手掌检测器定义的裁剪图像区域操作,并返回高保真度的3D手部关键点。
- 手势识别器:将先前计算的关键点配置分类为一组离散手势。
这个架构类似于谷歌最近发布的面部网格机器学习管道,以及其他已用于姿态估计的架构。将准确裁剪的手掌图像提供给手部界标模型可以大大减少对数据增强(如旋转,平移和缩放)的需要,并允许网络将大部分容量专门用于坐标预测精度。

◐ 2. BlazePalm:实时手部/手掌检测
为了检测初始手部位置,谷歌采用了名为BlazePalm的单摄检测器模型,并以类似于BlazeFace的方式针对移动实时用例进行了优化。检测手部是一项非常复杂的任务:模型必须支持各种手部尺寸,具有相对于图像帧的大范围跨度(约20×),并且能够检测被遮挡的双手和自我遮挡的双手。面部具有高对比图案(如在眼睛和嘴部区域),手部则缺少这一点,所以难以单单根据视觉特征进行可靠地检测。所以,通过提供诸如手臂,身体或人物特征等额外的情景信息有助于实现精确的的手部定位。
谷歌的解决方案采用不同的策略来解决上述挑战。首先,谷歌不是训练手部检测器,而是训练手掌检测器,因为估计诸如手掌和拳头等刚性对象的边界框比具有手指关节的手部要简单得多。另外,由于手掌是较小的对象,非最大抑制算法甚至很好地支持双手自遮挡情况(如握手)。再者,手掌可以使用方形边界框(机器学习用“锚”进行描述)来进行模拟,并忽略其他纵横比,所以能够将锚的数量减少3倍-5倍。其次,编码器 - 解码器特征提取器可用于大型场景情景感知,同时可用于小型对象(类似于RetinaNet方法)。最后,谷歌将训练期间的Focal Loss降至最低,从而能够支持由于大尺度方差导致的大量锚点。
通过上述技术,谷歌在手掌检测中实现了95.7%的平均精度。利用常规Cross Entropy Loss并且没有解码器的情况下只能实现86.22%的基线。
◐ 3. 手部界标模型
在对整个图像进行手掌检测之后,手部界标模型将通过回归(即直接坐标预测)在检测到的手部区域内执行21个3D手关节坐标的精确关键点定位。这个模型学习一致的固有手姿势表现,并且能够稳定支持部分可见的手部和自我遮挡情形。
为了获得ground truth数据,谷歌手动注释了具有21个3D坐标的大约30000张真实世界图像,如下所示(如果存在于每个相应的坐标,谷歌将从图像深度图中获取Z值)。为了更好地覆盖可能的手势,并对手部几何形状的性质提供额外的监督,谷歌同时在各种背景下渲染高质量的合成手部模型,并将其映射到相应的3D坐标。

然而,纯粹的合成数据难以扩展至in-the-wild领域。为了克服这个问题,谷歌采用了混合训练模式。下图是一个High-Level模型训练图例。

下表总结了回归准确性,具体取决于训练数据的性质。利用合成数据和现实世界数据可显著提升性能表现。
| Dataset | Mean regression error normalized by palm size |
| field1 | field2 |
| Only real-world | 16.1 % |
| Only rendered synthetic | 25.7 % |
| Mixed real-world + synthetic | 13.4 % |
4. 手势识别
紧接着预测的手部骨骼,谷歌应用了一个简单的算法来推导手势。首先,预计每个手指的状态,如弯曲或笔直,而这由关节的累积角度决定。然后,谷歌将手指状态集映射到一组预定义的手势。这种简单而有效的技术使得研究人员能够以合理的质量估计基本的静态手势。现有的管道支持计算来自多种文化的手势,如美国,欧洲和中国,包括“竖起大拇指”,握拳,“OK”,“金属礼”和“蜘蛛侠”。

◐ 5. MediaPipe示例
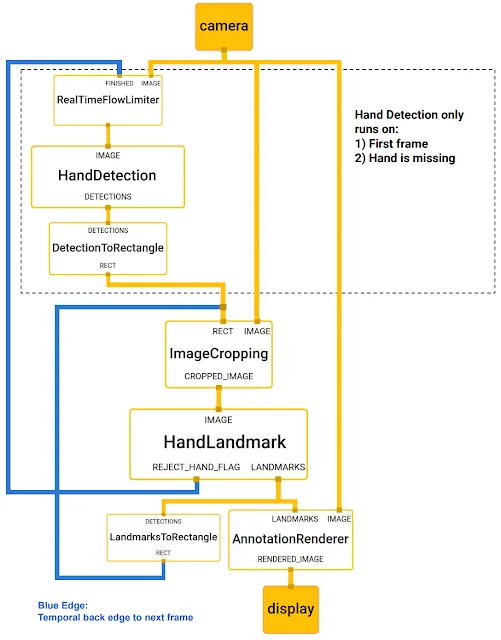
利用MediaPipe,这个感知管道可以构建为模块化组件的有向图:Calculators。Mediapipe附带一组可扩展的Calculators,可应对各种设备和平台的模型推理,媒体内容处理算法和数据转换等任务。诸如裁剪,渲染和神经网络计算等单独的Calculator可专由GPU执行。例如,谷歌为大多数现代手机应用TFLite GPU推理。
谷歌用于手部追踪的MediaPipe图如下所示。这个MediaPipe图由两个子图组成:一个用于手部检测,一个用于手部关键点计算。MediaPipe提供的一个关键优化是,手掌检测器仅在必要时(相当不频繁)运行,从而节省了大量的计算时间。谷歌是根据当前帧计算的手部关键点推断后续视频帧中的手部位置,从而消除了在每个帧运行手掌检测器的需要。为了实现鲁棒性,手部追踪器模型输出一个额外的标量,所述的标量捕获手部在输入裁剪中存在并合理对齐的置信度。只有当置信度低于某个阈值时,手部检测模型才会重新应用于整个帧。
高效的机器学习解决方案可以实时运行,并且可以支持各种不同的平台和形状参数。所以,谷歌将通过MediaPipe框架开源上述手部追踪和手势识别管道,并附带相关的端到端使用场景和源代码。这可以为研究人员和开发者提供完整的堆栈,并根据谷歌的模型对新想法进行实验和原型设计。
◐ 6. 未来计划
谷歌计划通过更强大和更稳定的追踪来扩展这项技术,扩大能够可靠检测的手势量,并支持动态手势及时展开等等。这家公司表示:“我们相信,开源这项技术可以推动研究社区和开发者社区实现新的创意和应用,而我们非常期待看到你的作品成果。”