告别“手指粘连”和“模糊脸”,中山大学提出高保真3D人体重建方法

高保真3D人体重建方法
(映维网Nweon 2026年05月04日)随着虚拟现实等应用的普及,如何从普通视频或照片中快速、逼真地重建出可活动的3D数字人,正成为计算机视觉领域的一项关键挑战。日前,中山大学研究团队提出了一种名为“基于区域感知初始化与几何先验的高保真3D高斯人体重建”的新方法,有效解决了现有技术中手指粘连、面部细节丢失等常见问题,同时保持了高渲染速度。
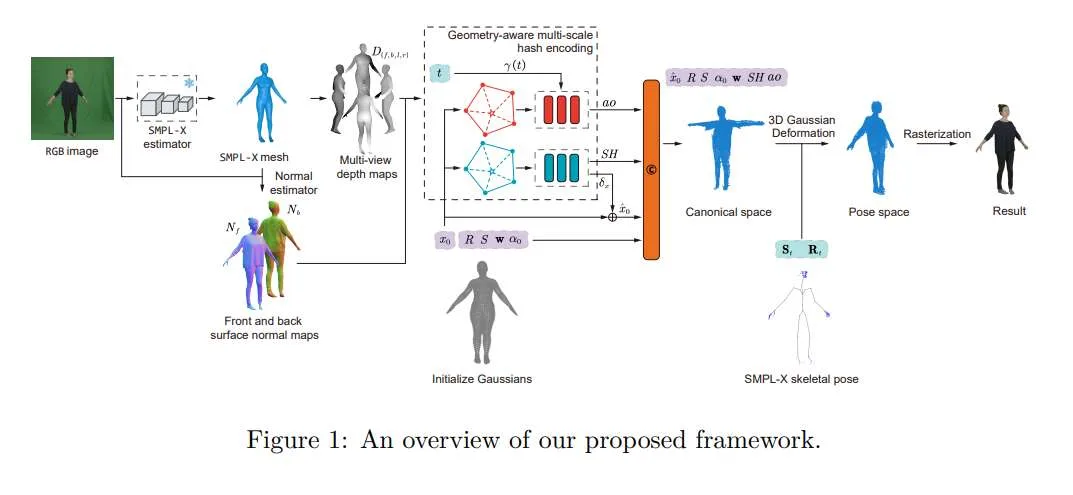
当前主流的3DGS技术在静态场景重建方面表现出色,但用于动态人体时,往往难以捕获到面部、手部等关键区域的高频几何细节,导致渲染结果中出现手指粘连、五官模糊或几何扭曲。另外,传统方法要么依赖粗略的模型初始化导致优化困难,要么为了追求细节而消耗大量GPU内存,两者难以兼顾。
针对这个问题,中山大学研究团队提出的新框架从三个方面进行了改进:首先,利用高表达性的SMPL-X参数化人体模型作为先验,取代常用的SMPL模型。SMPL-X对脸部表情和手部关节提供了更精细的控制,为高斯点云的初始分布奠定了更优的几何基础。
......(全文 756 字,剩余 371 字)