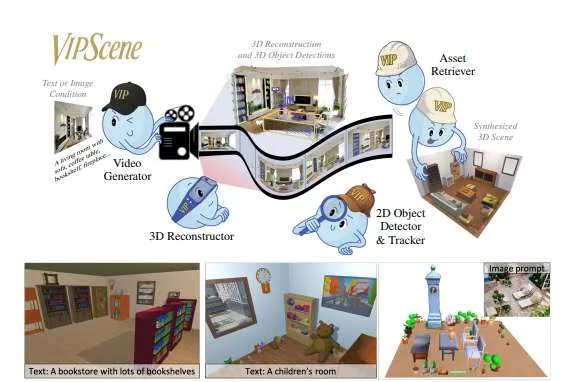
清华等机构联合提出VIPScene框架实现自动化三维场景生成

成功生成了语义准确、布局连贯且物理合理的三维场景
(映维网Nweon 2025年11月14日)长期以来,自动化生成高质量、布局合理的三维场景一直是计算机视觉和图形学领域追求的目标。传统的三维场景创建高度依赖专业人士的手工建模,费时费力。尽管近年来基于大型语言模型或图像生成模型的方法取得了一定进展,但在空间合理性和多视角一致性方面仍存在明显短板。
针对这个问题,清华大学,慕尼黑工业大学,苏黎世联邦理工学院,慕尼黑机器学习中心,微软和斯坦福大学团队发布了一项名为VIPScene的创新研究,并提出了一种全新的解决方案。通过巧妙利用视频生成模型中蕴含的物理世界常识,他们成功生成了语义准确、布局连贯且物理合理的三维场景,为虚拟现实等领域带来了新的可能性。
现有的自动化三维场景生成方法主要依赖于两类技术:
......(全文 2104 字,剩余 1784 字)