新泽西理工学院等研发RevAvatar框架实现VR头显反向透视

反向透视
(映维网Nweon 2025年09月15日)VR头显作为数字生态演进的核心组成,它存在一个关键挑战:遮挡用户眼睛及部分面部区域的特征会阻碍视觉交流,并可能加剧社交隔离。为应对这一问题,新泽西理工学院和中佛罗里达大学团队提出了RevAvatar。这种创新框架通过运用人工智能方法实现反向透视技术,从而重塑VR头显的设计与交互范式。
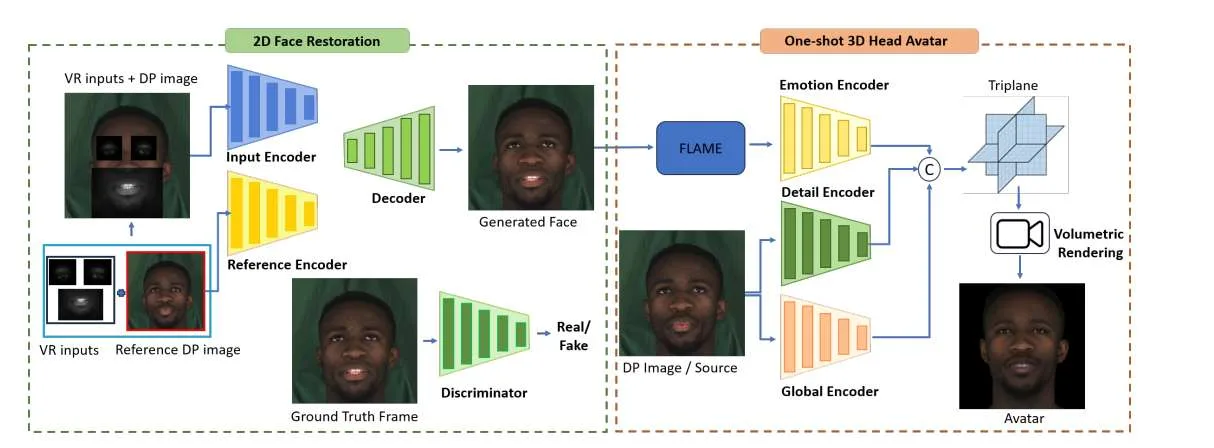
框架集成尖端生成模型与多模态AI技术,能够根据部分可见的眼部及下半面部区域重建高保真度2D面部图像,并生成精确的3D头部虚拟化身。这一突破性进展旨在打通虚拟与物理环境的无缝交互,为VR会议及社交活动等沉浸式体验奠定基础。另外,研究人员发布了VR-Face数据集,这个数据集包含20万个模拟多样化VR特定条件(如遮挡、光照变化和畸变)的样本。通过攻克当前VR系统的根本性局限,RevAvatar诠释了人工智能与新一代技术间的变革性协同效应,为增强虚拟环境中的人际连接与交互提供了强大平台。
AR与VR已成为改变游戏、远程协作、教育和医疗等行业的关键技术进展。作为沉浸式技术,它们重塑人机界面与数字体验,开启新型交互与参与模式。尽管VR头显已成为主流消费科技产品,其固有特性却将用户与周围环境隔离,限制了其在共享环境与公共空间中的融合。
......(全文 2249 字,剩余 1784 字)