研究团队为突破XR边缘计算瓶颈,提出高效DiT模型压缩方案

设计参数和计算效率高的Dit
(映维网Nweon 2025年06月13日)具有数十亿个模型参数的Diffusion Transformer(DiT)构成了DALL.E,Stable-Diffusion和SORA等流行图像和视频生成模型的主干。尽管相关模型在增强现实/虚拟现实等低延迟应用中十分必要,但由于其巨大的计算复杂性,它们无法部署在资源受限的边缘设备,如Apple Vision Pro或Meta Ray-Ban眼镜。
为了克服这个问题,伊利诺伊大学厄巴纳-香槟分校团队转向Knowledge Distillation,并执行彻底的设计空间探索,以实现给定参数大小的最佳DiT。特别是,团队提供了如何选择design knob的原则,如深度,宽度,attention head。
在模型性能、大小和速度之间出现了三方面的权衡,而这对边缘实现扩散至关重要。研究人员同时提出了两种蒸馏方法Teaching Assistant (TA)和Multi-In-One (MI1),以在DiT上下文中执行特征蒸馏。
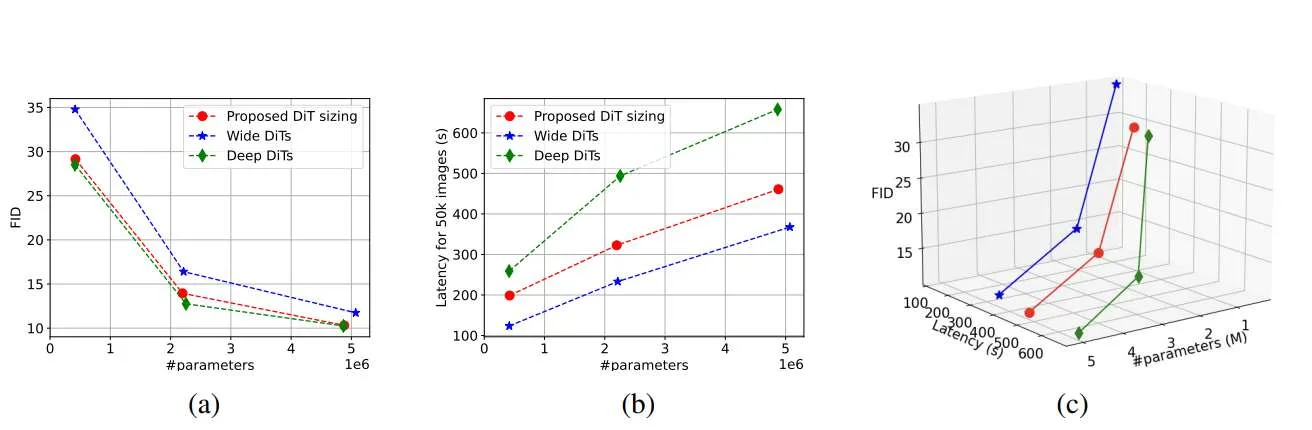
由于其高保真度、可泛化性、易于训练和可扩展性,DiT已经成为生成图像和视频的重要方法。DiT构成了各种实际部署的图像和视频生成模型的支柱,例如DALL.E,Stable-Diffusion和SORA。
出于模型的大参数大小和计算复杂性,必须使用云服务来远程运行它们。从云到边缘的数据传输相关的显著延迟无法为需要在资源受限的边缘设备实现的高帧率应用提供支持,例如增强现实/虚拟现实。
......(全文 1306 字,剩余 874 字)











