NeRF技术五年发展梳理综述:从神经辐射场到3D视觉应用的全面演进

研究人员对过去五年(2020-2025)的NeRF论文进行了全面调查
(映维网Nweon 2025年08月19日)2020年3月,神经辐射场NeRF的出现彻底改变了计算机视觉,允许隐式的、基于神经网络的场景表示和新颖的视图合成。如今,NeRF模型已在虚拟现实/增强现实等领域得到了广泛的应用。在一份名为《NeRF: Neural Radiance Field in 3D Vision: A Comprehensive Review》综述论文中,研究人员对过去五年(2020-2025)的NeRF论文进行了全面调查。
团队介绍了NeRF的理论及其通过可微体渲染的训练,同时对经典NeRF、隐式和混合神经表示以及神经场模型的性能和速度进行了基准比较,并概述了关键数据集:
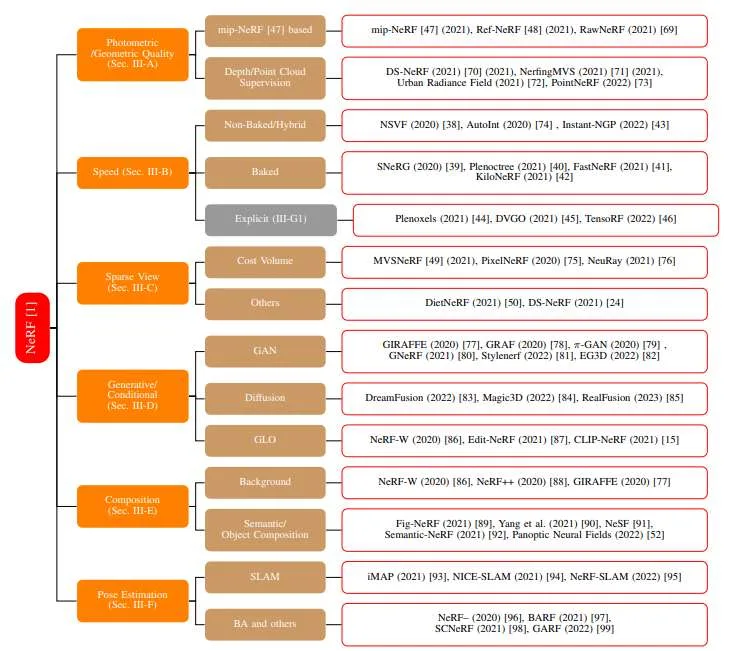
神经辐射场(Neural Radiance Fields/NeRF) 使用可微分体渲染来学习一种隐式的神经场景表示。它使用多层感知器MLP来将3D场景的几何形状和光照作为神经场存储起来。这种学习到的表示随后可用于从用户指定的、新颖的视角生成场景的2D图像。Mildenhall等人于ECCV 2020首次提出了NeRF。自那以后,它在视觉质量方面达到了最先进水平,产生了令人印象深刻的演示,并启发了一系列后续工作。从2020年起,NeRF模型及后续基于神经场的体渲染模型已在照片编辑、3D表面提取、人体化身建模、大型/城市级3D表示与视图合成、以及3D物体生成等领域得到应用。
2023年,高斯飞溅(Gaussian Splatting)作为一种替代性的新视角合成框架,在诸多新视角合成基准测试以及3D视觉应用中超越了NeRF及其相关方法。因此,大量的研究兴趣转向了高斯飞溅。尽管如此,自2023年以来,对NeRF及NeRF相关的神经渲染研究依然在持续。
NeRF模型相对于其他经典的新视角合成和场景表示方法具有重要优势:
- NeRF模型是自监督的。 它们仅需场景的多视图图像即可训练。与许多其他3D场景的神经表示不同,NeRF模型仅需图像和姿态即可学习场景,不需要3D或深度监督。姿态可以使用运动恢复结构工具包(如COLMAP )来估计。
- NeRF模型具有照片级真实感。 与经典技术、早期的新视角合成方法以及神经3D表示方法相比,原始的NeRF模型在视觉质量方面收敛到更好的结果,而更近期的模型表现更佳。
与基于高斯飞溅的方法相比(后者在新视角合成及相关研究中已很大程度上超越基于NeRF的方法),NeRF方法存在以下劣势:
- 高斯飞溅方法比NeRF方法更具照片级真实感,通常能收敛到能生成更高质量图像的表示。
- 高斯飞溅方法训练速度更快。在相同硬件,使用相同的训练图像,完全隐式的NeRF方法收敛所需时间长2到3个数量级。一旦训练完成,高斯飞溅方法的图像渲染速度比基于隐式NeRF的方法快几个数量级。
- 高斯飞溅方法使用基于3D点的表示,可以轻松转换为表示3D场景的常见数据结构——3D点云。另一方面,从典型的NeRF方法中提取显式的3D表示则更为困难。
然而,与高斯飞溅方法相比,NeRF方法具有以下优势:
- 隐式或混合的NeRF方法在训练后存储需求较低,通常在训练期间内存需求较低。
- 基于神经网络3D表示的NeRF方法更适用于需要或偏好隐式表示的3D视觉流程。
在这份综述论文中,研究人员组织撰写了一篇聚焦于NeRF方法和类NeRF神经渲染方法的综述论文。
◐ 1. 背景
2020年12月,Dellaert和Yen-Chen发表了一篇简洁的NeRF综述预印本,包含约50篇NeRF出版物/预印本。然而,它仅有八页,且不包含详细描述。另外,它仅包含2020年和2021年初的预印本,遗漏了2021年下半年及以后发表的多篇有影响力的NeRF论文。受其启发,并以其作为综述的起点,团队撰写了这份综述论文。
......(全文 30633 字,剩余 29484 字)