英伟达探索AI在XR领域的应用:构建多模态实时交互系统

在XR中利用VLM视觉语言模型
(映维网Nweon 2025年03月13日)英伟达一直有在探索AI在XR方面的应用。日前,团队就发文介绍了如何通过NVIDIA AI Blueprint for Video Search and Summarization*来构建实时多模态XR应用程序:

随着生成式人工智能和视觉基础模型的发展,VLM视觉语言模型掀起了视觉计算的新浪潮。其中模型能够实现高度复杂的感知和深入的情景理解,而这种智能解决方案为增强XR设置中的语义理解提供了一种富有前景的方法。通过集成VLM,开发者可以显著改进XR应用程序解释和与用户操作交互的方式,提高响应性和直观性。
这篇博文将引导你如何利用NVIDIA AI Blueprint进行视频搜索和总结,亦即打造一个视频搜索和总结Agent。从设置环境到无缝集成-实时语音识别和沉浸式交互,团队将解释完整的分步过程。
◐ 使用多模式AI Agent推进XR应用
通过会话AI功能增强XR应用程序,可以为用户创造更加身临其境的体验。通过在XR环境中创建提供问答功能的生成式AI Agent,用户可以更自然地进行交互并获得即时帮助。多模式人工智能代理处理和综合多种输入模式,例如视觉数据(例如XR耳机馈电)、语音、文本或传感器流,以做出上下文感知决策并生成自然的交互式响应。
这种集成可以产生重大影响的用例有:
-
熟练工人培训:在模拟培训比使用真实设备更安全、更实用的行业中,XR应用可以提供沉浸式和受控的环境。通过VLM增强的语义理解可以实现更逼真和更有效的培训体验,从而促进更好的技能转移和安全协议。
-
设计和原型:工程师和设计师可以利用XR环境来可视化和操作3D模型。VLM允许系统理解手势和情景命令,简化设计过程并促进创新。
-
教育和学习:XR应用可以创建跨不同学科的沉浸式教育体验。有了语义理解,系统可以适应学习者的互动,并提供个性化的内容和交互式元素,加深理解。
通过集成VLM并结合增强的语义理解和会话AI等功能,开发者可以扩展XR应用程序的潜在用例。
◐ NVIDIA AI Blueprint for Video Search and Summarization
在XR应用中利用VLM的关键挑战之一在于处理长视频或实时流,同时有效地捕获时间上下文。NVIDIA AI Blueprint for Video Search and Summarization通过支持VLM处理长视频和实时视频馈送来解决所述挑战。
NVIDIA AI Blueprint for Video Search and Summarization有助于简化视频分析AI Agent的开发。它们通过利用VLM和LLM来促进全面的视频分析。其中,VLM为视频片段生成详细的字幕,然后存储在矢量数据库中;LLM则进行总结以生成对用户查询的最终响应。更多信息可参阅这个页面。
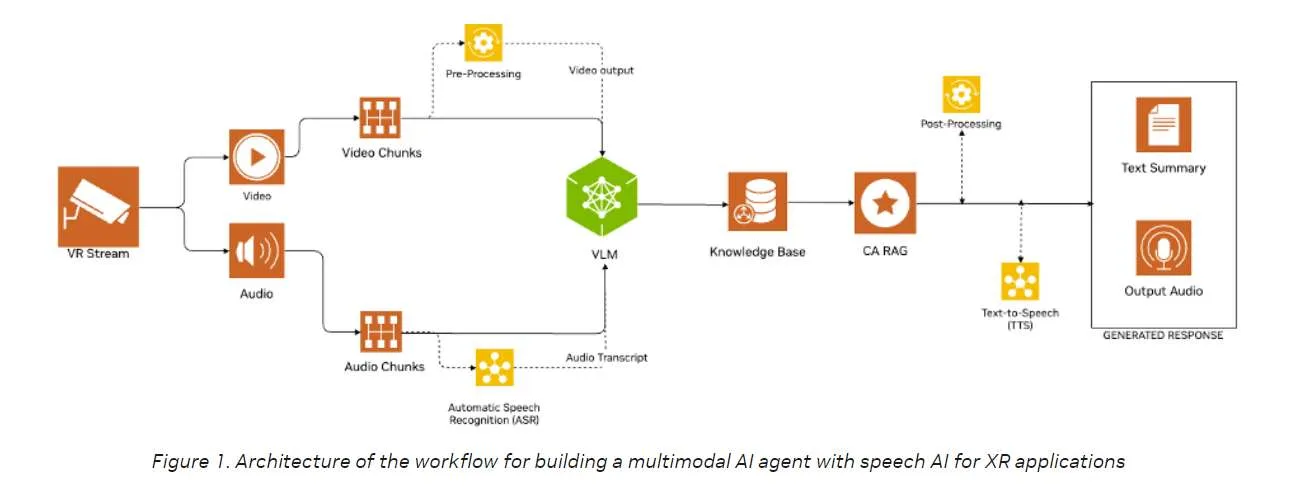
所述AI Blueprint的灵活设计允许用户定制工作流程并适应不同的环境。为了令其适应VR Agent的特定用例,第一步是确保将VR数据流送入管道。例如,你可以使用FFmpeg直接从VR头显的屏幕捕获VR环境。为了给予Agent交互性,英伟达优先启用语音通信。有什么比与VR Agent对话更好的交互方式呢?
有多种方法可以将音频和视觉理解整合到XR环境中。在本教程中,我们修改了AI蓝图,通过以一致的间隔分割音频和视频来合并音频处理,并将它们保存为。mpg和。wav文件。视频文件(.mpg)由VLM处理,而音频文件(.wav)通过API调用发送到NVIDIA Riva NIM ASR进行转录。Riva ASR NIM api可轻松访问最先进的多语言自动语音识别(ASR)模型。然后,转录的文本与相应的视频一起发送到VLM。
NVIDIA AI Blueprint for Video Search and Summarization可以理解长视频或实时流。然而,当用户提出问题时,只需要理解视频的部分内容。管道检查是否存在音频记录。如果副本可用,则调用VLM。如果不是,管道等待音频输入,而不是连续处理所有视频帧。
一旦检测到转录,管道将继续进行VLM和LLM调用,并使用Riva NIM TTS文本到语音模型将生成的响应转换回音频,然后返回给用户。下图显示了过程的详细步骤:
◐ 步骤一:创建VR环境
首先,通过Oculus Link桌面应用接入Meta Quest 3,从而在模拟一个VR环境。NVIDIA Omniverse是一个开发OpenUSD应用的平台,专注于工业数字化和物理人工智能仿真。NVIDIA Isaac Sim则是基于Omniverse构建的参考应用,用于在物理精确的虚拟环境中设计、模拟、测试和训练基于人工智能的机器人和自主机器。本教程使用来自预构建Isaac Sim模拟的Cortex UR10 Bin Stacking。
随着模拟运行,下一个任务是将Isaac Sim与任务对接起来。这是通过在Isaac Sim中启用英伟达提供的一组Create XR插件来实现。激活的插件如下:
-
Omniverse XR Telemetry
-
OpenXR Input/Output
-
Playback Extension for XR
-
Simulator for XR
-
UI Scene View Utilities
-
VR Experience
-
XR Core Infrastructure
-
XR Profile Common
-
XR UI Code for Building Profile UIs
-
XR UI Code for the Viewport
-
XR UI Common
一旦插件激活,使用OpenXR点击启动VR模式按钮进入VR环境。
接下来,按照以下步骤在Windows系统设置RTSP stream以捕获VR环境:
-
下载mediamtx-v1.8.4的Windows版本。
-
解压缩下载的文件夹,并导航到cd mediamtx_v1.8.4_windows_amd64.所在的目录。
-
创建mediamtx.yml配置文件,并将其放在相同的目录中。
-
运行 .\mediamtx.exe以启动RTSP服务器。
-
根据你的设置执行以下命令之一。请注意,你可能需要调整特定参数以获得兼容性和最佳流性能。
运行以下命令设置FFmpeg,以便捕获屏幕和麦克风:
ffmpeg -f gdigrab -framerate 10 -i desktop -f dshow -i audio="Microphone <br />(Realtek(R) Audio)" -vf scale=640:480 -c:v h264_nvenc -preset fast -b:v 1M<br />-maxrate 1M -bufsize 2M -rtbufsize 100M -c:a aac -ac 1 -b:a 16k -map 0:v -map<br />1:a -f rtsp -rtsp_transport tcp rtsp://localhost:8554/stream<br />运行以下命令,以在播放预录制音频文件时设置用于屏幕捕获的FFmpeg。所述命令无限循环播放音频。若只播放一次音频,请删除–stream_loop参数:
ffmpeg -f gdigrab -framerate 10 -i desktop -stream_loop -1 -i fourth_audio.wav <br />-vf scale=640:480 -c:v h264_nvenc -qp 0 -c:a aac -b:a 16k -f rtsp <br />-rtsp_transport tcp rtsp://localhost:8554/stream<br />◐ 步骤二:向管道添加音频
为了支持输入和输出音频处理,英伟达团队修改了NVIDIA AI Blueprint for Video Search and Summarization,以便它可以在视频输入之外合并音频。这个功能将在未来的版本中由VSS本地支持。
在本教程中,使用GStreamer的splitmuxsink来修改管道。团队建立了一个音频处理管道,对传入的音频流进行解码,并将其转换为标准格式。然后,使用splitmuxsink将音频数据写入分段的.wav文件,以便于管理和播放。这种集成确保在AI Agent的管道中同时处理音频和视频流,从而实现全面的媒体处理。
下面的代码展示了一个增加音频工作流的示例方法:
caps = srcbin_src_pad.query_caps()<p>if "audio" in caps.to_string():<br /> decodebin = Gst.ElementFactory.make("decodebin", "decoder")<br /> audioconvert = Gst.ElementFactory.make("audioconvert", "audioconvert")<br /> decodebin.connect("pad-added", on_pad_added_audio, audioconvert)</p><p>wavenc = Gst.ElementFactory.make("wavenc", "wav_encoder")<br /> splitmuxsink = Gst.ElementFactory.make("splitmuxsink", "splitmuxsink")<br /> splitmuxsink.set_property("location", self._output_file_prefix + "_%05d.wav")<br /> splitmuxsink.set_property("muxer", wavenc)<br /> splitmuxsink.set_property("max-size-time", 10000000000)<br /> splitmuxsink.connect("format-location-full", cb_format_location_audio, self)</p><p>pipeline.add(decodebin)<br /> pipeline.add(audioconvert)<br /> pipeline.add(splitmuxsink)</p><p>srcbin.link(decodebin)<br /> audioconvert.link(splitmuxsink)</p><p>pipeline.set_state(Gst.State.PLAYING)<br />◐ *步骤三:集成
Blueprint管道使用一个队列来处理从实时RTSP sream生成的视频块。视频块与预定义的文本提示一起传递给VLM。另外,同样的队列用于处理音频块,并发送到Riva NIM ASR API进行转录。然后,将结果转录用作VLM的输入文本提示。
管道目前在所有视频块中使用相同的输入提示符。团队对管道进行了修改,以使用从转录生成问题的提示。当提问时,这一过程从总结任务转变为针对特定视频片段的VQA任务。英伟达同时提高了管道更的效率,如果没有相应的音频转录,它会跳过视频块的VLM推理。
VLM推理输出随后附加来自知识库的信息,然后将其发送给LLM以生成最终答案。在VLM和LLM推理之后,文本将发送到Riva TTS API以创建一个audio .mp3文件,而不是在web UI显示生成的响应。这个文件然后发送到本地Windows系统,并在VR设置中为用户播放。
◐ 申请抢先体验计划
准备好使用NVIDIA AI Blueprint for Video Search and Summarization创建自己的AI Agent了吗?请点击申请抢先体验计划。










