微软AR/VR专利分享用于虚拟表示的并行人体姿态估计

用于虚拟表示的并行人体姿态估计
(映维网Nweon 2023年11月13日)关于人类用户姿势的信息可以映射到虚拟铰接表示。例如,当参与虚拟现实环境时,人类用户在虚拟环境中的表现会呈现出与现实世界姿势相似的姿势。用户的真实世界姿态可以通过先前训练的模型转换为虚拟铰接表示的姿态,模型可以训练为输出用于最终渲染的相同虚拟铰接表示姿态。
但有时候,系统可能需要显示远非真实的表示。例如,用户可以选择具有不同身体比例、骨骼和/或其他方面的不同卡通角色。
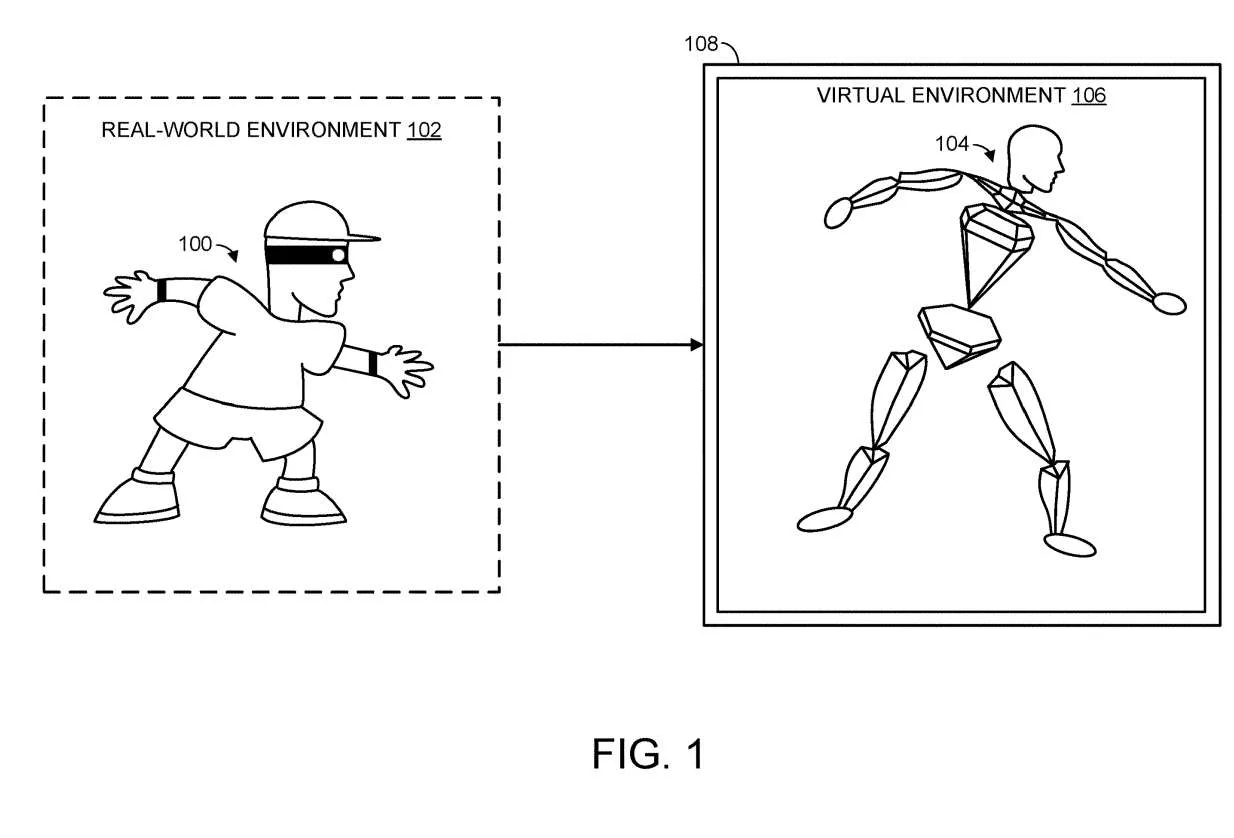
图1显示了真实世界环境102中的人类用户100。如图所示,将人类用户的姿势应用于铰接表示104。换句话说,当人类用户在真实世界环境中活动,相关活动将转换为虚拟环境106中铰接表示104的相应运动。
然而,有时候虚拟铰接表示可能需要与用于训练模型的表示不同。为了解决这个问题,名为“Concurrent human pose estimates for virtual representation”的微软专利介绍了用于同时估计模型铰接表示和目标铰接表示的姿态的技术。
具体地说,计算系统至少部分地基于来自一个或多个传感器的输入接收人类用户的一个或多个身体部位的详细参数的定位数据。这可以包括头显惯性测量单元输出,以及来自合适摄像头(例的输出。
......(全文 2532 字,剩余 2090 字)