微软CVPR 2023论文汇总:涵盖AR/VR,3D重建、人工智能等

微软共有40份论文在CVPR 2023进行了发表
(映维网Nweon 2023年06月29日)计算机视觉是使用计算机及相关设备对生物视觉的一种模拟,是人工智能领域的一个重要组成,并且在AR/VR,3D重建,工业检测,无人机和自动驾驶汽车等领域具有重要应用。
作为重要的计算机视觉和模式识别大会,每年的CVPR都将吸引学界的广泛参与,而来自世界各地的计算机视觉研究者和工程师都会在这里分享了相关研究的最新进展。对于今年在加拿大温哥华举行的CVPR 2023,微软共发表了40份论文。
下面是具体的整理,包括论文链接和摘要介绍(点击小标题即可访问论文的PDF完整版本或项目页面):
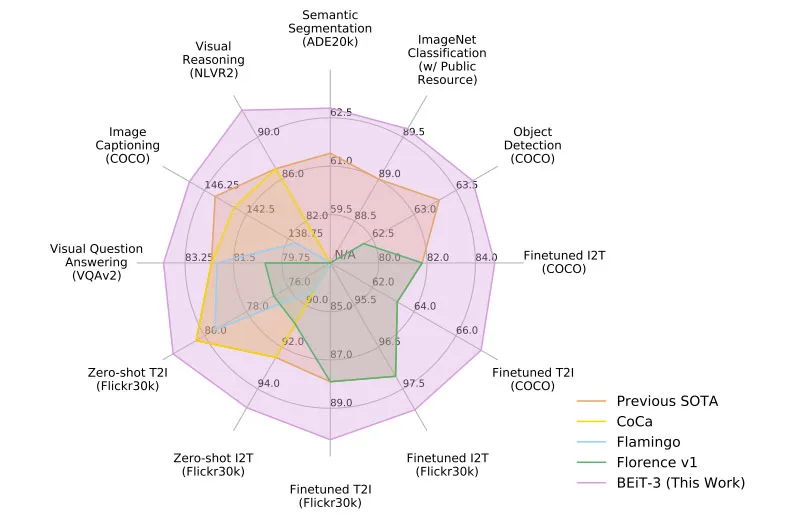
◐ 1. Image as a Foreign Language: BEiT Pretraining for Vision and Vision-Language Tasks
语言、视觉和多模式预训练的大一统正在出现。在这项研究中,团队介绍了一个通用的多模态基础模型BEiT-3,而它在视觉和视觉语言任务方面都取得了优异的transfer表现。具体来说,我们从骨干架构、预训练任务和模型扩展三个方面推进了大一统。团队使用Multiway Transformers进行通用建模,其中模块化架构实现了深度融合和模态特定编码。基于共享的主干,团队以统一的方式对图像(英语)、文本(英语)和图像-文本对(“平行句”)进行掩码的“语言”建模。实验结果表明,BEiT-3在对象检测(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图像字幕(COCO)等任务都取得的取得了SOTA表现。
◐ 2. On Data Scaling in Masked Image Modeling
自监督学习的一个重要目标是令模型预训练能够从几乎无限的数据中受益。但业界质疑最近流行的一种方法MIM无法从更大的数据中受益。在这项研究中,团队通过广泛的实验打破了这种误解,数据规模从ImageNet-1K的10%到完整的ImageNet-22K,模型大小从4900万到10亿,训练长度从125K迭代到500K迭代。研究表明:(i)掩码图像建模同样需要更大的数据。团队观察到,非常大的模型与相对较小的数据拟合过度; (ii) 训练时间长短十分重要。用亚麻图像建模训练的大型模型可以受益于更长训练的更多数据;(iii)预训练中的验证损失是衡量模型性能的良好指标。这一观察结果使得团队能够提前预评估预先训练的模型,而不必对下游任务进行昂贵的试错评估。
◐ 3. Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
本文提出了一种3D生成式模型。其中,它使用扩散模型自动生成以神经辐射场表示的3D数字化身。生成这样的化身的一个重大挑战是,3D中的存储器和处理成本对于生成高质量化身所需的丰富细节令人望而却步。为了解决这个问题,团队提出了roll-out diffusion network(Rodin),它将神经辐射场表示为多个2D特征图,并将其展开到单个2D特征平面中,然后在平面内执行3D感知扩散。Rodin模型带来了急需的计算效率,同时通过使用3D感知卷积来保持3D中扩散的完整性。团队同时使用latent conditioning反射来协调特征生成,以实现全局一致性,从而产生高保真化身,并实现基于文本的语义编辑。最后,团队使用hierarchical synthesis来进一步增强细节。与通过现有生成技术生成的3D化身相比,所述方法可以生成具有逼真发型和胡须等面部毛发的高度详细化身。团队同时演示了从图像或文本生成3D化身以及文本引导的可编辑性。
◐ 4. 3D Human Mesh Estimation from Virtual Markers
受体三维三维姿态估计成功的启发,最近许多人类网格估计器提出将三维骨架估计为中间表示,通过利用网格拓扑对密集的三维网格进行回归。然而,在提取骨骼时会丢失体型信息,导致性能平平。先进的动捕系统通过在体表放置密集的物理标记来解决这个问题,从而可以从非刚性运动中提取逼真的网格。但是,它们不能应用于没有标记的wild图像。在这项研究中,团队提出了一种称为虚拟标记的中间表示,它以生成方式并基于大规模动捕数据学习体表的64个landmark关键点,模仿物理标记的效果。虚拟标记可以从wild图像中准确地检测到,并且可以通过简单的插值重建具有真实形状的完整网格。所述方法在三个数据集上都优于最先进的方法。特别是,在具有不同体型的SURREAL数据集,它以显著的优势超过了现有的方法。
◐ 5. LIMAP – Global Mapper 3D Line Mapping Revisited
与稀疏关键点相比,少数线段可以简明地对高级场景布局进行编码,因为它们通常描绘主要的结构元素。除了提供强烈的几何线索外,它们同时在城市景观和室内场景中无处不在。尽管有明显的优势,但目前基于线的重建方法远远落后于基于点的重建方法。在本文中,团队旨在通过引入LIMAP来缩小这一差距。LIMAP是一个用于3D线图绘制的库,可以从多视图图像中稳健有效地创建3D线图。这主要是通过重新审视线三角测量的退化问题,以及利用线重合、平行和正交等结构先验来实现。相关代码与现有的基于点的运动结构方法无缝集成,可以利用它们的3D点来进一步改进线重建。另外,作为副产品,所述方法能够恢复线和点/消失点(VP)之间的3D关联图。深入的实验表明LIMAP在3D线映射方面显著优于现有的方法。强大的3D折线图同时开辟了新的研究方向。团队展示了两个示例应用程序:视觉定位和束调整,其中将线与点一起积分会产生最佳结果。
◐ 6. BlendFields: Few-Shot Example-Driven Facial Modeling
生成人脸的忠实可视化需要捕获人脸几何结构和外观的粗略和精细细节。现有的方法要么是数据驱动,需要研究界无法公开访问的大量数据,要么由于依赖于几何人脸模型而无法通过网格离散化和线性变形来表示纹理中的细粒度细节,从而无法捕获精细细节。团队介绍了一种从传统计算机图形学技术中汲取灵感来弥补这一差距的方法。他们通过混合稀疏的一组极端姿势的外观来建模未见表情。这种混合是通过测量表情中的局部体三维变化来执行,并且每当在测试中执行类似的表情时,局部再现它们的外观。团队证明了所述方法可以泛化到未见表情,在面部光滑的体三维之上添加细粒度的效果,并演示了它如何泛化到面部之外。
◐ 7. CiCo: Domain-Aware Sign Language Retrieval via Cross-Lingual Contrastive Learning
这项工作的重点是手语检索,一项最近提出的手语理解任务。手语检索包括两个子任务:文本到手语视频(T2V)检索和手语视频到文本(V2T)检索。与传统的视频文本检索不同,由于手语是一种自然语言,手语视频不仅包含视觉信号,而且本身具有丰富的语义。考虑到这一特点,团队将手语检索定义为跨语言检索问题和视频文本检索任务。具体而言,他们考虑了手语和自然语言的语言特性,同时识别了细粒度的跨语言(即手语到单词)映射,同时在联合嵌入空间中对比文本和手语视频。这个过程称为跨语言对比学习。另一个挑战是数据稀缺问题。手语数据集的规模比语音识别小几个数量级。团队通过pseudo-labeling将在大规模手语视频中预训练的domain-agnostic手语编码器引入目标领域,从而缓解了这一问题。所述框架在各种数据集上以很大的优势优于开创性方法。
◐ 8. Deep Frequency Filtering for Domain Generalization
提高深度神经网络的泛化能力对其实际应用至关重要,而这一直是一个长期的挑战。有理论研究发现,DNN在学习过程中对特定频率component有偏好,并表明这可能会影响学习特征的稳健性。在本文中,团队提出了用于学习domain-generalizable特征的深度频率滤波Deep Frequency Filtering(DFF),这是首次尝试于训练过程中在latent空间中明确调制跨领域不同transfer困难的频率component。为了实现这一点,团队对不同层的特征图进行快速傅立叶变换(FFT),然后采用轻量级模块从FFT后的频率表示中学习attention掩码,以增强transferable component,同时抑制不利于泛化的component。另外,团队实证比较了采用不同类型的attention设计来实现DFF的有效性。大量实验证明了所提出的DFF的有效性。
◐ 9. DeepLSD: Line Segment Detection and Refinement with Deep Image Gradients
线段在我们的人造世界中无处不在,并且越来越多地用于视觉任务。由于它们的空间范围和提供的结构信息,它们与特征点是互补的。传统的基于图像梯度的线检测器非常快速和准确,但在噪点图像和具有挑战性的条件下缺乏鲁棒性。它们的learned counterpart更具可重复性,可以处理具有挑战性的图像,但代价是精度较低,偏向线框线。团队建议将传统方法和学习方法相结合,以两全其美,并实现一种准确而稳健的线检测器,可以在wild训练,无需ground truth线。团队提出的新线段检测器DeepLSD使用深度网络处理图像,以生成线吸引场,然后将其转换为替代图像梯度大小和角度,然后将梯度大小和角提供给任何现有的手工制作的线检测器。另外,团队提出了一种新的优化工具来细化基于吸引场和消失点的线段。这种改进大大提高了当前深度探测器的精度。
◐ 10. DETRs with Hybrid Matching
一对一集匹配是DETR建立端到端能力的关键设计,因此对象检测不需要手工制作的NMS(非最大抑制)来消除重复检测。这种端到端签名对于DETR的多功能性很重要,并且它已泛化到更广泛的愿景任务中。但团队注意到,很少有查询指定为正样本,并且一对一的集合匹配显著降低了正样本的训练效果。他们提出了一种基于混合匹配方案的简单而有效的方法,它可以在训练期间将原始的一对一匹配分支与辅助的一对多匹配分支相结合。混合策略已证明可以显著提高准确性。在推理中,只使用原始的一对一匹配分支,从而保持了DETR的端到端优点和相同的推理效率。所述方法被命名为H-DETR,它表明可以在广泛的视觉任务中持续改进广泛的代表性DETR方法,包括Deformable-DETR、PETRv2、PETR和TransTrack等。
◐ 11. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
vision transformer由于其高建模能力而取得了巨大成功。然而,它们显著的性能伴随着沉重的计算成本,这使得它们不适合实时应用。在本文中,团队提出了一个名为EfficientViT的高速vision transformer。团队发现,现有transformer模型的速度通常受到内存低效操作的限制,特别是MHSA中的张量整形和element-wise函数。因此,团队设计了一种具有三明治布局的新构建块,即在有效的FFN层之间使用单个memory-bound MHSA,这在增强信道通信的同时提高了存储器效率。另外,团队发现attention map具有高度相似性,导致计算冗余。为了解决这一问题,团队提出了一种级联的group attention模块,为具有不同全特征分割的attention head提供反馈,这不仅节省了计算成本,而且提高了attention的多样性。综合实验表明,EfficientViT优于现有的高效模型,在速度和准确性之间取得了良好的平衡。
◐ 12. Four-View Geometry with Unknown Radial Distortion
为了解决从未知校准参数(即焦距和径向失真)的图像中进行相对姿态估计的问题,团队提出了一个新的解决方案。所述方法能够在不建模所述参数的情况下进行度量重建。重建至少需要校准和未校准camera的4个视图中的13个点。在校准的情况下,这可以建模为具有3584个解的多项式方程组。尽管表面上很难解决,但这个问题却以惊人的方式分解了。每个解都属于大小为16的欧几里得对称类,可以通过用28、2和4个解求解一系列三个子问题来估计224个类的代表。团队强调了径向四焦点张量的内部约束与4×4矩阵的主辅之间的关系。最后,团队在模拟和真实数据上评估了所述方法,并将其与以前的无校准解决方案进行了比较。
◐ 13. High-Fidelity and Freely Controllable Talking Head Video Generation
说话人头生成是基于给定的源身份和目标运动来生成视频。然而,当前的方法面临一定的挑战,并限制了生成视频的质量和可控性。首先,生成的面孔通常会出现意外变形和严重扭曲。其次,图像没有显式解开运动相关信息,如姿势和表情,这限制了在生成过程中对不同属性的操作。第三,由于相邻帧之间提取的landmark的不一致性,生成的视频往往具有闪烁的伪影。在本文中,团队提出的新模型可以生成高保真的说话人头视频,并可以自由控制头部姿势和表情。所述方法利用自监督学习的landmark和基于3D人脸模型的landmark来对运动进行建模。团队同时引入了一种新的运动感知多尺度特征对齐模块,以在没有人脸失真的情况下有效地传递运动。另外,通过特征情景自适应和传播模块来增强合成的头部视频的平滑度。他们在具有挑战性的数据集上评估了模型,并展示了其最先进的性能。
◐ 14. Human Pose As Compositional Tokens
人体姿势通常由身体关节或其热图嵌入的坐标向量表示。尽管数据处理很容易,但由于身体关节之间缺乏依赖性建模,不现实的姿态估计都会接受。在本文中,团队提出了一种结构化表示Pose as Compositional Tokens(PCT),以探索联合依赖。它由M个离散的令牌表示姿势,每个令牌表征具有几个相互依赖的关节的子结构。这使得它能够以低成本实现小的重建误差。然后,将姿态估计视为一项分类任务。特别地,学习了一个分类器来预测图像中M个标记的类别。使用预先学习的解码器网络来从令牌中恢复姿势,而无需进一步的后处理。实验表明,在一般情况下,它可以获得与现有方法更好或可比的姿态估计结果。
◐ 15. iCLIP: Bridging Image Classification and Contrastive Language-Image Pre-training for Visual Recognition
本文提出的方法有效地结合了两种流行的视觉识别方法,即图像分类和对比语言图像预训练,而团队将其称为iCLIP。他们不是对每个任务使用两个单独的head进行多任务学习,而是以一种深度的方式将这两个任务融合在一起,使图像分类与语言图像预训练共享相同的公式和相同的模型权重。为了进一步连接这两个任务,团队建议使用external knowledge来增强图像分类任务中的类别名称。大量实验表明,所述方法很好地结合了两个任务的优点:类别标签清晰清晰,在图像分类任务中具有较强的辨别能力;文本描述中语义丰富,在CLIP任务中具有良好的零样本能力。特别是,它在In-1K上达到了82.9%的top-1准确率,在Kornblith 12-dataset benchmark的零样本识别上,在模型大小相似的情况下,超过CLIP 1.8%。
◐ 16. Iterative Proposal Refinement for Weakly-Supervised Video Grounding
Weakly-Supervised Video Grounding(WSVG)旨在仅使用视频级注释将感兴趣事件定位在未修剪的视频中。到目前为止,大多数最先进的WSVG方法都遵循两阶段流程,即首先生成潜在的临时提案,然后以候选提案为基础。尽管取得了进展,但现有的提案生成方法存在两个缺点:1)缺乏明确的对应模型;以及2)复杂事件的部分覆盖。为此,团队提出了一种新的IteRative prOposal refiNement网络(称为IRON),以逐步将先验提取到每个提案中,并鼓励具有更完整覆盖范围的提案。具体来说,他们建立了两个轻量级的蒸馏分支,以揭示语义和概念层面上的跨模态对应关系。然后,设计了一种迭代标签传播(LP)策略,以防止网络过度关注最具歧视性的事件,而不是整个句子的内容。准确地说,在每次迭代过程中,具有最小蒸馏损失的提案及其相邻提案被视为正样本,这以级联的方式细化提案置信度得分。在两个具有挑战性的WSVG数据集上进行的大量实验和消融研究已经证明了IRON的有效性。
◐ 17. LayoutFormer++: Conditional Graphic Layout Generation via Constraint Serialization and Decoding Space Restriction
根据用户约束生成逼真布局的条件图形布局生成一项尚未得到充分研究的挑战性任务。首先,关于如何灵活统一地处理不同的用户约束,相关讨论有限。其次,为了使布局符合用户约束,现有的研究往往会显著牺牲生成质量。在这项研究中,团队提出LayoutFormer++来解决上述问题。首先,为了灵活处理不同的约束,他们提出了一种约束序列化方案,将不同的用户约束表示为具有预定义格式的令牌序列。然后,将条件布局生成公式化为序列到序列的转换,并利用以Transformer为基本架构的编码器-解码器框架。另外,为了在不影响质量的情况下更好地满足用户需求,他们提出了一种解码空间限制策略。具体来说,通过忽略肯定违反用户约束并可能导致低质量布局的选项来修剪预测分布,并从受限分布中制作模型样本。实验表明,LayoutFormer++在所有任务上都优于现有的方法,它具有更好的生成质量和更少的约束违反。
◐ 18. Learning to Exploit Temporal Structure for Biomedical Vision-Language Processing
视觉语言处理中的自监督学习利用了图像和文本模态之间的语义对齐。尽管临床注释通常指先前的图像,生物医学VLP的先前研究主要依赖于单个图像和报告对的对齐。这不仅导致模式之间的一致性较差,而且错过了通过数据中现有的时间内容来利用丰富的自监督的机会。在这项研究中,团队明确说明了在训练和微调期间可用的先前图像和报告。所述方法名为BioViL-T,使用与文本模型联合训练的CNN Transformer混合多图像编码器。它设计为多功能,以应对各种挑战,如随时间变化的姿势变化和丢失的输入图像。由此产生的模型在单图像和多图像设置中都优于下游任务。团队发布了一个新的多模态时间基准数据集MS-CXR-T,以从时间语义的角度量化视觉语言表示的质量。
◐ 19. Look Before You Match: Instance Understanding Matters in Video Object Segmentation
最近,基于内存的方法在视频对象分割(VOS)中取得了令人印象深刻的结果。然而,由于缺乏实例理解能力,上述方法往往容易受到物体和camera移动所引起的大外观变化或视点变化的影响。在本文中,团队认为实例理解在VOS中很重要,而将其与基于内存的匹配相结合可以享受协同效应。为了实现这一目标,团队提出了一个用于VOS的两分支网络,其中基于查询的实例分割(IS)分支深入研究当前帧的实例细节,而VOS分支执行与内存库的时空匹配。团队使用来自IS分支的学习对象查询来将特定于实例的信息注入到查询关键字中,从而进一步执行实例增强匹配。另外,团队引入了一种多路径融合块,以有效地将存储器读出与来自实例分割解码器的多尺度特征相结合。所述方法在DAVIS 2016/2017 val(92.6%和87.1%)、DAVIS 2017 test dev(82.8%)和YouTube VOS 2018/2019 val(86.3%和86.3%)实现了最先进的性能,明显优于其他方法。
◐ 20. MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
本文提出了一个简单而有效的框架MaskCLIP,它将新提出的掩码自蒸馏引入对比语言图像预训练中。掩码自蒸馏的核心思想是将完整图像的表示提取为掩码图像预测的表示。这种合并有两个重要的好处。首先,掩码自蒸馏以局部patch表示学习为目标,这是对专注于文本相关表示的视觉语言对比的补充。其次,从训练目标的角度来看,掩码自蒸馏也与视觉语言对比一致,因为两者都利用视觉编码器进行特征对齐,从而能够从语言中获得间接监督来学习局部语义。
◐ 21. MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
在这项研究中,团队提出了一个保留ID的谈话人头生成框架。与从稀疏流进行插值相反,密集landmark对于实现精确的几何感知流场至关重要。其次,受人脸交换方法的启发,对tu’a在合成过程中自适应地融合源身份,使网络更好地保留了图像肖像的关键特征。尽管所提出的模型在已建立的基准上超过了前一代的保真度,但依然需要个性化的微调,从而进一步确保说话人头生成符合实际使用条件。然而,这个过程在计算方面要求很高,标准用户负担不起。为了缓解这种情况,团队提出了一种使用元学习方法的快速适应模型。所学习的模型可以最快30秒地适应于高质量的个性化模型。最后,团队提出了一种时空增强模块以提高精细细节,同时确保时间相关性。大量的实验证明了所述方法在一次性和个性化设置方面都优于现有技术。
◐ 22. MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
团队提出了一个联合音视频生成框架,它可以同时带来引人入胜的浏览和聆听体验,以实现高质量的逼真视频。为了生成联合音频-视频对,他们提出了一种新的多模扩散模型,而它具有两个耦合的去噪自动编码器。与现有的单模态扩散模型相比,多模扩散模型由一个顺序的多模态U-Net组成。音频和视频的两个子网学习从高斯噪点中逐渐生成对齐的音频-视频对。为了确保模态之间的语义一致性,团队提出了一种新的基于随机移位的attention block桥接两个子网,并实现了有效的跨模态对齐,从而增强了彼此的音频-视频保真度。
◐ 23. Motion Information Propagation for Neural Video Compression
在大多数现有的神经视频编解码器中,其中的信息流是单向的,只有运动编码提供用于帧编码的运动矢量。在本文中,团队认为通过信息交互,可以实现运动编码和帧编码之间的协同作用。他们通过运动信息传播有效地引入了运动编码和帧编码之间的双向信息交互。当生成用于帧编码的时间情景时,来自运动解码器的高维运动特征用作运动引导以减轻对准误差。同时,除了在当前时间步长辅助帧编码外,在对后续运动潜像进行编码时,来自情景生成的特征将作为运动条件进行传播。通过这种相互作用的循环,可以建立运动编码的特征传播,并增强利用长程时间相关性的能力。另外,团队提出了混合情景生成,以利用多尺度情景特征并提供更好的运动条件。实验表明,所述方法可以比以前的SOTA神经视频编解码器节省12.9%的比特率。
◐ 24. Natural Language-Assisted Sign Language Recognition
手语是通过手势、面部表情、肢体动作等传递信息的视觉语言。由于视觉组合的固有限制,其存在大量视觉上不可区分的手语姿势,这限制了视觉神经网络的识别能力。为了缓解这个问题,团队提出了自然语言辅助手语识别NLA-SLR架。所述框架利用了注释中包含的语义信息。首先,对于具有相似语义的视觉符号,通过为每个训练手语生成软件标签来提出语言感知标签平滑。其次,对于具有不同语义的视觉符号,提出了一种模态间混合技术,融合视觉和光泽特征以在混合标签的监督下进一步最大化不同手语姿势的可分性。另外,团队同时介绍了一种新的骨干:视频关键点网络。它不仅对RGB视频和人体关键点进行建模,而且从不同时间感受野的手势视频中获取knowledge。所述方法在三个广泛采用的基准上实现了最先进的性能:MSSL、WLASL和NMFs-CSL。
◐ 25. Neural Video Compression with Diverse Contexts
对于任何视频编解码器,编码效率高度依赖于要编码的当前信号是否能够从先前重构的信号中找到相关情景。传统的编解码器已经验证了更多的情景带来了可观的编码增益,但这是以一种耗时的方式实现。然而,对于新兴的神经视频编解码器(NVC)来说,其情景依然有限,导致压缩比较低。为了提高NVC,本文提出在时间和空间维度上增加情景多样性。首先,指导模型跨帧学习层次质量模式,这丰富了长期但高质量的时间情景。另外,为了挖掘基于光流的编码框架的潜力,团队引入了一种基于组的偏移分集,提出了跨组交互以更好地挖掘情景。同时,在对latent表示进行并行编码时,本文采用了基于四叉树的划分来增加空间情景的多样性。实验表明,编解码器比以前的SOTA NVC节省了23.5%的比特率。不仅只是这样,在PSNR方面,所提出的编解码器在RGB和YUV420颜色空间中都超过了正在开发中的下一代编解码器/ECM。
◐ 26.
近年来,以语言为导向的图像编辑取得了巨大成功。在本文中,团队研究了样本引导的图像编辑,以实现更精确的控制。他们通过利用自监督训练来解开和重新组织源图像和样本来实现这一目标。然而,naive方法会导致明显的融合伪影。研究人员仔细分析了它,并提出了一个信息瓶颈和强augmentations来避免直接复制和粘贴示例图像的解决方案。同时,为了确保编辑过程的可控性,他们为样本图像设计了一个任意形状的掩码,并利用无分类器引导来增加与样本图像的相似性。整个框架涉及扩散模型的单一正向,没有任何迭代优化。实验证明,所述方法实现了令人印象深刻的性能,并能够以高保真度对wild图像进行可控编辑。
◐ 27. ReCo: Region-Controlled Text-to-Image Generation
最近,大规模文本到图像(T2I)模型在生成高保真图像方面表现出了令人印象深刻的性能,但可控性有限。在本文中,团队提出了一种有效的T2I生成区域控制技术。他们用一组额外的位置标记来增加T2I模型的输入,其中位置标记表示量化的空间坐标。每个区域由四个位置标记指定,以表示左上角和右下角,然后是开放式自然语言区域描述。然后,用这种新的输入接口对预先训练的T2I模型进行微调。所述模型称为ReCo,而它能够对由开放的区域文本而不是由约束类别集的对象标签描述的任意对象进行区域控制。与通过位置词增强的T2I模型相比,ReCo实现了更好的图像质量,并且对象被更准确地放置。另外,团队证明了ReCo可以通过自由形式的区域描述更好地控制对象数量、空间关系和区域属性,如颜色/大小。
◐ 28. ResFormer: Scaling ViTs with Multi-Resolution Training
Vision Transformers(ViTs)已经取得了巨大的成功,但它们的分辨率可扩展性很差,即当使用训练中看不到的输入分辨率时,性能会急剧下降。本文介绍了ResFormer。它对不同分辨率的复制图像进行操作,并强制执行规模一致性损失,以参与不同规模的交互式信息。更重要的是,为了有效地在不同的分辨率之间交替,特别是在测试中的新分辨率之间,团队提出了一种全局局部位置嵌入策略,在输入大小的条件下平滑变化。在ImageNet上进行了大量的图像分类实验。而结果提供的强有力定量证据表明,ResFormer在大范围的分辨率方面具有很好的缩放能力。例如,当在相对较低和较高的分辨率(即96和640)进行评估时,ResFormer-B-MR分别达到75.86%和81.72%的Top-1准确率,这比DeiT-B好48%和7.49%。另外,团队证明ResFormer是灵活的,可以很容易地扩展到语义分割、对象检测和视频动作识别。
◐ 29. Revealing the Dark Secrets of Masked Image Modeling
作为预训练的掩码图像建模MIM已证明对许多视觉下游任务有效。在本文中,团队从可视化和实验两个角度将MIM与长期主导的监督预训练模型进行了比较,以揭示它们的关键代表性差异。从可视化中,他们发现MIM给训练模型的所有层带来了局部诱导偏差,但监督模型倾向于局部关注较低层,而更全局地关注较高层。这可能是MIM帮助具有非常大的感受野的Vision Transformer进行优化的原因。使用MIM,模型可以在所有层的attention head上保持很大的多样性。但对于监督模型,attention head的多样性几乎从最后三层消失,较少的多样性损害了微调性能。从实验中,团队发现MIM模型在弱语义的几何和运动任务或细粒度分类任务上的性能明显优于监督模型。对于监督预训练充分覆盖类别的语义理解数据集,MIM模型依然可以实现具有高度竞争力的迁移性能。
◐ 30. SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
在本文中,团队提出了一种新的用于视觉追踪的序列到序列学习框架SeqTrack。它将视觉追踪视为一个序列生成问题,以自回归的方式预测对象边界框。SeqTrack仅采用简单的编码器-解码器transformer架构。编码器使用双向transformer提取视觉特征,而解码器使用因果transformer自回归生成边界框值序列。损失函数是一个简单的交叉熵。这样的序列学习范式不仅简化了追踪框架,而且在基准测试上实现了有竞争力的性能。例如,SeqTrack在LaSOT上获得72.5%的AUC,建立了最先进的新性能。
◐ 31. Side Adapter Network for Open-Vocabulary Semantic Segmentation
本文提出了一种新的基于预先训练的视觉语言模型的开放词汇语义分割框架SAN。所述方法把语义分割任务建模为区域识别问题。将侧网络连接到具有两个分支的冻结CLIP模型:一个用于预测掩码建议,另一个用于在CLIP模型中应用于识别掩码类别的attention偏差。这种解耦的设计有利于CLIP识别掩模建议的类别。由于连接的侧网络可以重用CLIP功能,因此它可以非常轻。另外,可以端到端地训练整个网络,允许侧网络适应冻结CLIP模型。所述方法快速、准确,并且只添加了额外的可训练参数。团队在多个语义分割基准上评估所述方法,并证明它显著优于其他方法:可训练参数减少了18倍,推理速度快了19倍。
◐ 32. Streaming Video Model
传统上,视频理解任务由两个独立的架构建模。基于序列的视频任务使用视频主干直接提取时空特征,而基于帧的视频任务则依赖于单个固定的图像主干来提取空间特征。相反,团队建议将视频理解任务统一到一个新的流式视频架构中,亦即S-ViT。S-ViT首先使用存储器启用的时间感知空间编码器来产生帧级特征,以服务于基于帧的视频任务。然后将帧特征输入到与任务相关的时间解码器中,以获得基于序列的任务的时空特征。S-ViT的效率和功效体现在基于序列的动作识别任务中的最先进准确性,以及在基于帧的MOT任务中相对于传统架构的竞争优势上。
◐ 33. Structural Multiplane Image: Bridging Neural View Synthesis and 3D Reconstruction
多平面图像MPI包含一组前向平行的RGBA层,并且是从稀疏输入进行视图合成的有效表示。然而,它的固定结构限制了性能,尤其是对于以斜角成像的表面。本文介绍了S-MPI,其中平面结构简明地近似于3D场景。S-MPI通过几何忠实的结构传递RGBA情景,直接连接视图合成和3D重建。它不仅可以克服MPI的关键限制,即倾斜表面的离散化伪影和冗余层的滥用,同时可以获得平面三维重建。尽管应用S-MPI具有直觉和需求,但依然面临着巨大的挑战,例如,RGBA层和平面姿态的高保真近似、多视图一致性、非平面区域建模以及使用相交平面的高效渲染。因此,团队提出了一种基于分段模型的transformer-based网络。它预测了紧凑而富有表现力的S-MPI层及其相应的掩码、姿势和RGBA情景。大量实验表明,所述方法优于以前最先进的基于MPI的视图合成方法和平面重建方法。
◐ 34. SVFormer: Semi-supervised Video Transformer for Action Recognition
由于视频注释的高成本,半监督动作识别是一项具有挑战性但至关重要的任务。现有的方法主要使用卷积神经网络,但目前革命性的vision transformer模型很少有进行探索。在本文中,团队研究了在SSL设置下使用transformer模型进行动作识别。为此,他们介绍了SVFormer。其中,它采用了一个稳定的伪标记框架(即EMA-Tacher)来处理未标记的视频样本。尽管广泛的数据增强已被证明对半监督图像分类有效,但它们通常对视频识别产生有限的结果。因此,团队引入了一种新的增强策略Tube TokenMix,所述策略专为视频数据量身定制,其中视频片段通过掩码与时间轴上一致的掩码令牌混合。另外,团队提出了一种时间扭曲增强来覆盖视频中复杂的时间变化,它将选定的帧拉伸到剪辑中的不同时间持续时间。在Kinetics-400、UCF-101和HMDB-51三个数据集上进行的大量实验验证了SVFormer的优势。
◐ 35. TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models
掩码图像建模MIM在预训练大型vision transformers(ViTs)中表现强劲。然而,对于现实世界的应用至关重要的小型模型不能或只能从这种预训练方法中获得少量好处。在本文中,团队探索了蒸馏技术,以将基于大型MIM的预训练模型的成功转移到较小的模型。他们系统地研究了提取框架中的不同选项,包括提取目标、损失、输入、网络正则化、顺序提取等,并揭示了以下三点:1)提取令牌关系比基于CLS令牌和特征的提取更有效;2) 当student的深度与teacher的深度不匹配时,作为目标的teacher网络的中间层比使用最后一层的表现更好;3) 弱正则化是优选的。团队实现了显著的微调精度改进。他们的TinyMIM基本大小模型在AE20K语义分割中实现了52.2mIoU,比MAE基线高+4.1。
◐ 36. Two-Shot Video Object Segmentation
先前关于视频对象分割VOS的研究是在密集注释的视频上进行训练。然而,获取像素级别的注释昂贵且耗时的。在这项研究中,团队证明了在稀疏注释的视频上训练令人满意的VOS模型的可行性。团队将这种新颖的训练范式称为Two-Shot视频对象分割。其基本思想是在训练期间为未标记的帧生成伪标签,并根据标记数据和伪标记数据的组合优化模型。所述方法非常简单,可以应用于大多数现有框架。他们首先以半监督的方式在稀疏注释的视频上预训练VOS模型,第一帧始终是标记的帧。然后,采用预先训练的VOS模型为所有未标记的帧生成伪标签,然后将其存储在伪标签库中。最后,在标记和伪标记数据上重新训练VOS模型,而对第一帧没有任何限制。
◐ 37. Unifying Layout Generation with a Decoupled Diffusion Model
布局生成旨在合成由具有不同属性的元素组成的逼真的图形场景,包括类别、大小、位置和元素之间的关系。这是一项关键任务,可以减轻格式化场景的重型图形设计工作的负担。多样化的应用场景给统一各种布局生成子任务(包括有条件和无条件生成)带来了巨大挑战。在本文中,团队提出了一个布局扩散生成模型LDGM来实现与单个解耦扩散模型的统一。LDGM将任意缺失或粗略元素属性的布局视为已完成布局的中间扩散状态。由于不同的属性有其各自的语义和特征,团队对它们的扩散过程进行解耦,以提高训练样本的多样性,并联合学习反向过程,以利用全局范围的情景来促进生成。因此,LDGM可以从零开始或以任意可用属性为条件生成布局。大量的定性和定量实验表明,LDGM在功能和性能方面都优于现有的布局生成模型。
◐ 38. VideoTrack: Learning to Track Objects via Video Transformer
现有的 Siamese追踪方法建立在两个单帧之间的成对匹配基础上,严重依赖于额外的复杂机制来利用连续视频帧之间的时间信息,阻碍了它们的高效和工业部署。在这项研究中,团队采用了序列级目标匹配,从而可以通过整洁的前馈视频模型将时间情景编码为空间特征。具体而言,团队通过直接从帧级patch序列中实现时空特征学习,使标准video transformer架构适应视觉追踪。为了更好地适应追踪任务,通过顺序的多分支三元组block仔细地混合视频片段中的时空信息,以形成video transformer主干。然后,团队提出了一种解纠缠的双模板机制,将静态和动态外观随时间的变化解耦,并减少视频帧中的时间冗余。大量实验表明,所述在实时运行的同时取得了最先进的结果。
◐ 39. VolRecon: Volume Rendering of Signed Ray Distance Functions for Generalizable Multi-View Reconstruction
神经辐射场NeRF在新视图合成中的成功启发了研究人员提出神经隐式场景重建。然而,大多数现有的神经隐式重建方法都会优化每个场景的参数,因此缺乏对新场景的可泛化性。团队介绍了一种新的具有Signed Ray Distance Function (SRDF)的可泛化隐式重建方法VolRecon。为了重建具有精细细节和少量噪低点的场景,VolRecon结合了从多视图特征聚合的投影特征和从coarse global feature volume插值的体三维特征。使用ray transformer,团队计算光线上采样点的SRDF值,然后渲染颜色和深度。在DTU数据集上,VolRecon在稀疏视图重建方面比SparseNeuS高出约30%,在全视图重建方面实现了与MVSNet相当的精度。另外,所述方法在large-scale ETH3D基准测试上表现出良好的泛化性能。
◐ 40. X-Avatar: Expressive Human Avatars
X-Avatar是一种新颖的化身模型,它可以捕获数字人类的全部表现力。所述方法以整体的方式对身体、手、面部表情和外表进行建模,并能够从全3D扫描或RGB-D数据中学习。为了实现这一点,团队提出了一个可以由SMPL-X的参数空间驱动的part-aware学习的前向蒙皮模块。为了有效地学习神经形状和变形场,团队提出了新的part-aware采样和初始化策略。这带来了更高的逼真度结果,尤其是对于较小的身体部位。尽管关节骨骼的数量增加了,但依然能保持有效的训练。为了用高频细节捕获化身的外观,团队用纹理网络扩展了几何和变形场。实验表明,所述方法在动画任务的数量和质量上都优于强基线。为了促进未来对化身的研究,团队贡献了一个名为X-Humans的新数据集,其中包含来自20名参与者的233个高质量纹理扫描序列,总计35500个数据帧。










