微软AR专利探索多源摄像头捕获图像生成场景叠加图

选择特定图像以便生成叠加图像
(映维网Nweon 2023年04月19日)如果大家有关注微软的专利探索,这家公司曾多次提出一种集成式摄像头/系统摄像头+分离式摄像头/外部摄像头的系统理念。其中,集成式摄像头/系统摄像头是指物理集成到头显的摄像;分离式摄像头/外部摄像头则是指与头显分离的摄像头。
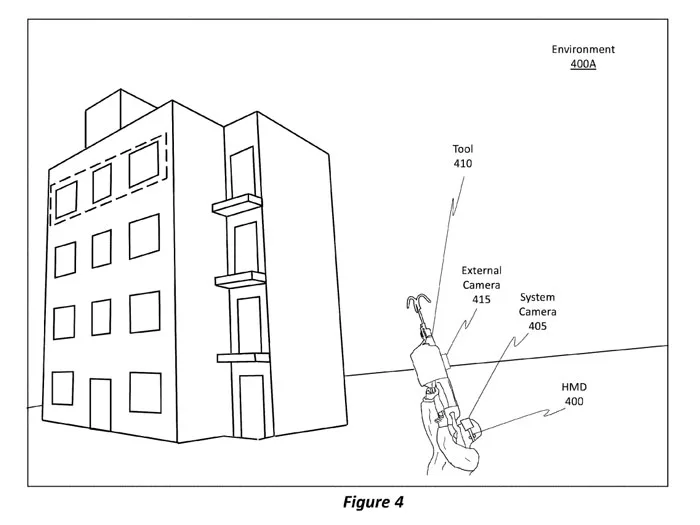
例如在一个场景中,可以将分离式摄像头捆绑或以其他方式放置在用户的胸部。在另一个场景中,分离式摄像头可以不放置在用户的身体上,而是由用户握持的工具上,如上面的图4所示。
在名为“Frame selection for image matching in rapid target acquisition”的专利申请中,微软介绍了评估来自多个不同源的多个图像,以及用于选择特定图像以便生成叠加图像的方法。
概括来说,系统获得第一组系统摄像头图像(如基于第一FPS速率)和第二组外部摄像头图像(如基于第二FPS速率)。访问一组规则以管理用于选择特定系统摄像头图像和特定外部摄像头图像的选择过程。
所选择的图像指定用于生成叠加图像。其中,选择过程是使用所访问的一组规则来执行的。实施例然后通过叠加和对准从所选图像获得的内容来生成叠加图像。然后,可以在头戴式设备中显示叠加图像。
如前所述,微软构思的系统包括两个摄像头,而两个摄像头的至少一部分视场彼此重叠,所以有必要进行校准。因此,可以识别对应的内容,然后可以基于类似的对应内容生成合并、融合或叠加的图像。通过生成叠加图像,实施例能够向用户提供增强的图像内容。
......(全文 4101 字,剩余 3561 字)











