微软专利为VR头显MR透视提出机器学习选择性叠加图像内容解决方案

呈现透视合成图像
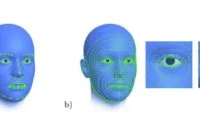
(映维网Nweon 2022年05月31日)对于当前VR头显支持的MR透视功能,其性能大多存在限制,用户体验不佳。另外,今天的技术需要多个摄像头,但这会导致额外的重量、成本和能耗。针对这个问题,行业正在积极探索各种解决方案。例如在名为“Using machine learning to selectively overlay image content”的专利申请中,微软就提出了一种利用机器学习来选择性叠加图像内容的方式。
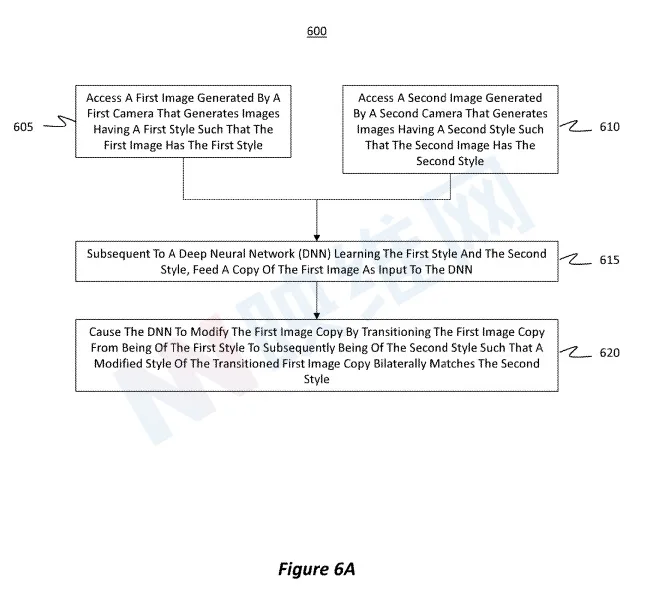
概括来说,系统可以访问具有第一样式的第一图像,并访问具有第二样式的第二图像。在对样式进行深度神经网络(DNN)学习之后,将第一图像的副本作为输入馈送给DNN。DNN通过将第一图像副本从第一样式转换为随后的第二样式来修改第一图像副本。
结果,转换后的第一图像副本的修改样式双边匹配第二样式。通过这种方式,头显可以从一个图像中选择性地提取一个或多个部分,进行匹配的翘曲,并将所述部分叠加到另一个图像,从而呈现质量提升的透视合成图像。
......(全文 3763 字,剩余 3417 字)