苏黎世联邦理工学院提出gDNA,生成有详细皱纹和明确姿势控制的虚拟人

苏黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所
(映维网Nweon 2022年04月27日)轻松创建各种高质量的数字人并完全控制其姿势的能力,这在电影制作、游戏、VR/AR、建筑和计算机视觉中存在大量的应用。尽管现代计算机图形技术实现了照片真实感,但它们通常需要大量的专业知识和大量的手动操作。
在日前公布的论文《gDNA: Towards Generative Detailed Neural Avatars》中,由黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所组成的研究人员希望能够轻松创建详细的虚拟数字人。
团队的目标是通过学习一个generative model of people模型,从而帮助社区广泛访问3D虚拟数字人。为了实现这一目标,研究人员提出了一种方法,而且它可以:
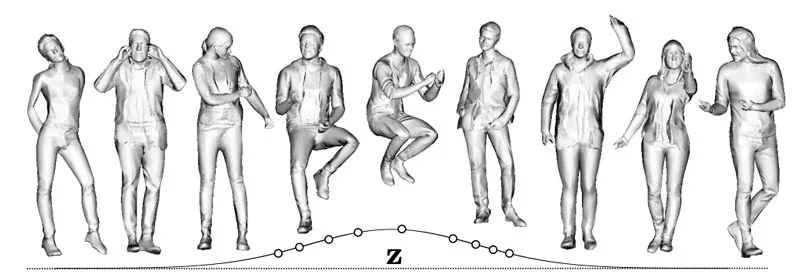
- 生成不同的3D数字人
- 具有不同的身份和形状
- 以不同的服装风格和姿势出现
- 逼真且随机的高频细节,例如服装褶皱。
三维刚体对象的Generative Modeling正在快速发展,但由于服装、其拓扑结构和姿势驱动的变形之间的复杂交互,为穿衣人及其关节建模非常困难。有研究利用神经内隐曲面为single subject学习高质量的关节数字人,但它们并非生成性,即无法合成新的人类特征和形状。现有的服装生成模型通过预测人体网格的位移(CAPE),或通过在T-posed身体拖动隐式服装表示(SMPLicit),并依靠SMPL学习的蒙皮进行重摆来增强SMPL。
团队表明,特征、形状、清晰度和服装的整体建模可以提高数字人的逼真度和动画效果,并提高3D扫描的准确度。为了实现详细神经数字人的完全Generative Modeling,由黎世联邦理工学院,图宾根大学和马克斯·普朗克智能系统研究所组成的研究人员提出了gDNA。
......(全文 3277 字,剩余 2705 字)








