研发实战:掌握Meta Quest内存使用情况,优化App运行性能

内存
(映维网Nweon 2022年04月25日)为了创造尽可能最佳的虚拟现实体验,为Meta Quest平台优化应用或游戏非常重要。但这是重大的挑战,因为移动GPU只能填充有限的像素和着色有限的顶点,而且其搭载的CPU在算力方面同样存在制约。在Quest同时存在另一个问题:内存。与大多数PC不同,因为Quest的存储是闪存,所以我们不能将内存交换到磁盘,因为频繁的读写会缩短硬件的使用寿命。另外,设备受到可用RAM数量的限制。与大多数具有16 GB、32 GB甚至更多RAM的现代PC相比,Quest只有4 GB的RAM,而Quest 2则是6 GB。可以想象,围绕Quest优化应用或游戏需要一定的思考和努力,而实现目标的第一步是确定实际使用的内存量。所以,内存是如何分配的呢?
日前,Meta软件工程师特雷弗·达施(Trevor Dasch)撰文介绍了相关的最佳实践,下面是映维网的具体整理:
◐ 1. 内存如何分配
在测量使用的内存量之前,我们需要清楚系统如何使用内存。从编程的角度来看,只需使用类似“malloc()”的调用向系统请求内存。这将给你提供可以读写的一定字节数,然后你调用’free()”。你或许会认为只需将所有的“malloc()”调用相加,就可以得到应用程序的总内存使用量,但实际情况不没有这么简单。
为了解释原因,我们首先假设一个按顺序分配你请求的确切内存量的系统。我们未初始化的内存可能如下所示:

现在我们假设第一个分配(A)是5字节:

然后我们再分配两个字节,一个是7字节(B),一个是4字节(C):

现在我们释放B,分配一个大小为5(D)的新缓冲区。我们的系统尝试将数据打包到尽可能小的空间中,并将B替换为D,但正如你所看到的一样,我们留下了一个2字节的空缺,并且只能用1或2字节的分配来填充:

如果我们继续这样做,最终会留下一堆大小不一的未使用内存空缺,跟踪所有的空缺及其大小将是一项艰巨的任务。这种状态称为碎片化,并且是一个非常难解决的问题。不过,现代系统可以通过更智能地进行内存分配来最可能避免所述情况。
实际上,当调用malloc时,我们的系统不会返回顺序block。相反,它将按照分配器确定的预定义block大小返回内存。Android libc的默认分配器是jemalloc。jemalloc的分配模式是在大小为2次方的block中分配内存,从最小分配大小64位(8字节)开始。当你向jemalloc请求从1到8字节的任何分配时,它将保留一个8字节的插槽,从9到16字节,它将保留16字节,从17到32字节,它将保留32字节,依此类推。在分配期间,插槽的未使用部分将保持未使用状态。这意味着当你释放一个分配时,分配程序将知道它现在有一个给定大小的完整可用插槽,这使得它更容易重用。
我们下面来看看前面的分配示例。从空的初始状态开始:
分配A(5)字节后,我们的第一个插槽将填充一个:

然后在分配了B(7字节)和C(4字节)之后,我们的第二个插槽将有B,第三个插槽将有C:

如果我们取消分配B,我们的第二个插槽将再次打开,允许我们用新的分配D填充它:

尽管使用所述系统分配了更多的内存,但分配器更容易找到要分配的位置。它只需要跟踪某个插槽是否已使用,而不是跟踪每个分配的大小、初始偏移量等。这使得分配更快速、更高效。
在系统层面上,跟踪所有分配依然相当复杂,并会导致碎片化,所以操作系统会将内存划分为更大的且固定大小的block,亦即“page”。Quest的page大小为4096字节,这同时是大多数现代操作系统的典型特征。在系统级别,始终会为一个流程分配完整数量的page。在应用程序级别,page的利用方式由分配器决定。这意味着分配器负责确定如何将page划分为单独的block插槽,插槽何时可供使用或重用,以及何时从操作系统请求新page。决定分配是否需要一个新page的条件不太透明,这意味着几乎不可能准确预测一组给定的“malloc()”调用将分配多少page。
同样重要的是理解,当系统向应用程序提供page时,它们会提供一个虚拟地址,而不是物理地址。这允许系统管理进程之间共享的物理RAM,并且在允许交换到磁盘的系统上,这将支持从RAM中删除对进程完全不可见的page。这避免了物理内存碎片化的问题。如果应用程序需要一个大的连续内存block,只要虚拟地址是连续的,系统就可以从物理内存中的任何位置为其提供所需的任意多个page。应该注意的是,虚拟地址空间很有可能被分割,尤其是在32位应用程序上,其中总地址空间只有4GB。这就是为什么Quest平台需要64位应用程序。
◐ 2. PSS, RSS, USS, VSS
一旦明确内存是如何分配,计算一个进程使用了多少内存似乎就足够简单了:只需把page加起来。但这存在一个非常复杂的问题。如果多个进程共享一个公共库,而不是将同一库的多个副本加载到内存中,则只会加载一次,从而节省内存。不过,它确实改变了每个应用程序实际使用的内存量。假设进程A已加载,并且有一个名为“sharedlib.so”且需要100MB的共享库,并且进程A作为一个整体需要1.1GB。
假设另外有一个进程B,总共需要1.5GB,包括“sharedlib.so”。现在,如果同时加载进程A和进程B,系统的总内存使用量只有2.5GB,而不是2.6GB,因为两个进程只加载一次“sharedlib.so”。所以,每个进程使用多少内存呢?你可以说进程A使用的是1.1GB,进程B使用的是1.5GB,因为这是每个进程各自占用的空间。或者你可以说进程A占用了1.1GB,而进程B占用了1.4GB。这准确地表示了系统的总内存使用量。如果进程A退出,进程B将占用1.5GB。
为了提供一致的方法来测量每个进程的内存使用情况,以便所有进程的内存加起来等于整个系统内存,我们使用了一种称为“Proportional Set Size(PPS)”的方法。PSS是一个基于公式的数字,其中取进程的所有唯一内存,然后取所有共享内存,除以共享所述内存的进程数。在我们的例子中,进程A的PSS是1.05GB,进程B的PSS是1.45GB,这加起来就是真正的总内存2.5GB。尽管PSS数字并不能反映进程A和进程B的实际内存使用情况,但它在累加系统使用的所有内存时非常有用。这同时是Android判断应用程序是否使用了太多内存的方式,并且必须通过测量其PSS来终止。
有其他方法可以测量系统报告的应用内存使用情况。Resident Set Size(RSS)是进程正在使用的物理内存的总数,包括共享内存。Unique Set Size(USS)是进程正在使用的唯一内存量(不计算任何共享内存)。最后,Virtual Set Size(VSS)是所有虚拟分配内存的总和(无论是否映射到物理内存)。
尽管系统使用PSS来确定是否应该终止应用,但它对调试和调优没有多大用处。RSS虽然不能代表应用程序的独占内存使用情况,但可以很好地跟踪应用程序的总内存使用情况以及进行额外分配的时间。USS同样是一个可以跟踪的有用指标,因为它是一种仅由应用分配的内存度量。VSS是最不有用的内存指标,因为它与应用即将耗尽空间的程度几乎没有关联。
我们以上面的流程A和流程B为例进行说明:

剩下的问题是,如何访问PSS、RSS、USS和VSS?对于Quest,PSS在logcat中每秒记录一次。它另外可以通过OVR Metrics Tool获取。同样,VSS和RSS可以通过OVR Metrics Tool获取。你同时可以通过“dumpsys procstats”检索PSS、RSS和USS的汇总值,它将返回一段时间内的最小值、最大值和平均值。“dumpsys procstats”的输出格式如下所示:

其中,内存量表示:

另外,你可以通过Android Java API ActivityManager.getProcessMemoryInfo查询PSS、RSS和USS。这个应用将填充MemoryInfo对象,它具有检索总PSS,以及private dirty, private clean, shared dirty和shared clean的函数。USS是private clean内存和private dirty内存的总和,但分开跟踪private clean内存和private dirty内存可能非常有用,因为private clean内存更容易回收(在本例中,clean意味着它在从磁盘读取时未被修改)。RSS是所有private和shared、clean和dirty内存的总和。
◐ 3. GPU内存
Meta Quest和Quest 2都有一个组合的片上系统架构,它在CPU和GPU之间共享RAM。这意味着,当通过GLES或Vulkan创建纹理和图形资源时,它们不会放在专用的GPU RAM中,而是放在与代码分配相同的主内存中,比如调用malloc()。这意味着应用程序内存的所有度量同时包括GPU内存。尽管CPU分配的内存通常容易跟踪(只需在调用malloc时进行标记),但GPU分配可能更难跟踪,因为它们发生在图形驱动程序中。它们的大小同样不太可以预测,因为纹理可能(而且经常)需要比预期更多的内存来与page偏移对齐。
幸运的是,有方法可以查询应用的GPU内存使用情况。对于high level视图,可以使用gpumeminfo。这个工具每秒轮询一次,并汇总每种GPU资源类型的内存使用情况。具体来说,这个工具正在读取和处理“/d/kgsl/proc//mem”,其中包含所有分配GPU资源的列表,涉及资源类型和每个使用的内存量。根据应用使用的是GLES还是Vulkan,列表中将包含以下类型:
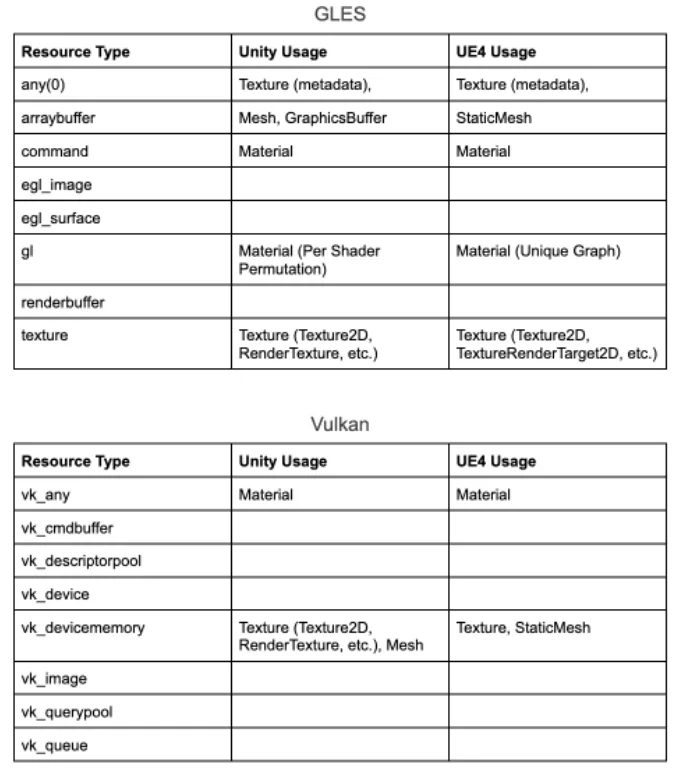
◐ 4. 引擎分配
如果你已经计算了总内存使用量和GPU内存使用量,跟踪游戏和游戏引擎直接分配的内存量通常非常有用。幸运的是,Unity和Unreal都提供了工具来帮助你分析内存在任何给定时间中的内容。
- Unity Memory Profiler:Unity的Memory Profiler既可以作为内存图实时跟踪分配,又可以提供内存当前状态的快照,并实际确定使对象驻留在内存中的引用。有关快照使用情况的更多信息,我建议使用本教程。
- Unreal Engine Memory Profiler:UE4同样包含一个用于跟踪实时内存使用情况的Profiler工具。
5. 减少内存使用的提示和技巧
既然你可以计算应用程序使用的所有内存,所以你应该可以采取措施减少所需的内存量,使其始终保持在限制之下。以下是仅供参考的意见:
◐ 5.1 压缩你的纹理
将未压缩变成到压缩可能是节省内存的最简单方法。未压缩的ARGB纹理需要每像素32位,这意味着单个4k纹理需要67MB(甚至不包括mips)。使用比如ASTC或ETC2等硬件支持的压缩可以将每像素的字节数降低到0.89字节,这意味着相同的4k纹理可以收缩到1.87 MB。当然,更高的压缩将意味着丢失更多细节,所以选择压缩级别的过程是寻找将质量保持在可接受水平的最高压缩级别。就确定使用哪种压缩而言,ASTC通常在给定的压缩级别方面提供最高的视觉质量,但ETC2在GPU的采样性能稍好一些,所以对于性能关键的情况,它可能是首选。请注意,在2019.1.0之前的Unity版本中,ASTC纹理不遵守质量设置,导致其外观比质量设置为“高”时更差。
◐ 5.2 确保纹理和网格仅存在于GPU内存中
在Unity中,纹理和网格有一个标记为“Read/Write Enabled”的复选框。这个复选框将它们标记为可从代码中读取(可在运行时通过“isReadable”属性查询可读状态)。当纹理或网格标记为可读时,资源的一个副本保存在主内存中,而另一个副本则上载到GPU。这样做的效果是,对于渲染始终驻留在内存中,纹理或网格所需的内存量需要增加两倍。同样,在运行时创建纹理或网格时,你可以通过调用纹理Apply(true)或网格UploadMeshData(true)来删除主内存副本,这将使它们不再从代码中可读。
在Unreal引擎中,默认情况下纹理将仅将其数据上载到GPU。网格可以用“Allow CPUAccess”标记,这将在内存中保留一个副本。确保只检查运行时需要操纵的网格。
◐ 5.3 压缩网格顶点
尽管压缩网格顶点听起来和压缩纹理一样,但它们实际上是非常不同的过程。纹理压缩使用基于视觉的算法将纹理转换为最佳格式,而网格压缩只是将较大的数据类型替换为较小的顶点缓冲区属性。例如,顶点位置可以使用半精度,UV可以使用固定精度,而不是全浮点精度。理想情况下,这将在你选择的网格编辑器中按每个网格进行,但将一组预设的顶点属性精度应用于所有网格会更方便。
Unity允许你在设置的顶点压缩下拉列表中选择要压缩的属性来实现这一点。需要注意的是,在导入器为网格/模型启用网格压缩会禁用顶点压缩。网格压缩压缩磁盘的网格,但在内存中加载时,它将是全尺寸。在GPU内存有限的情况下,压缩顶点可能存在加快渲染时间的额外优势。
默认情况下,Unreal Engine将对特定通道使用精度较低的数据。通过为网格各个LOD级别勾选“Use High Precision Tangent Basis”或“Use Full Precision UVs复选框,你可以禁用这个行为。
◐ 5.4 使用Texture Streaming
Texture Streaming是Unity和Unreal Engine提供的系统,它用于尝试仅加载当前camera视图实际需要的纹理的mipmap级别,从而节省内存。所述系统同时允许你设置总纹理预算,这有助于防止超出系统的总内存限制。
这个系统的缺点是纹理pop-in,因为mip是异步加载,它们的质量可能会突然提高。使用Texture Streaming同时很难优化总内存,因为系统的行为有时是不可预测的,毕竟它是基于camera视图,而camera视图可以快速变化,尤其是虚拟现实。如果游戏具有任何其他动态加载功能,它可能与其他IO操作冲突。然而,它可能是一个根据应用减少总内存使用量的优秀解决方案,因此值得测试。
◐ 5.5 根据GPU对齐优化纹理大小
创建纹理时,GPU将分配内存block以保持纹理对齐,这样在采样时page更容易进入缓存。所以对于给定大小的纹理,GPU可能会将内存四舍五入,使其略大于纹理实际需要的大小。如下面的图表所示,在特定大小下,分配的大小与纹理大小完全匹配,但一个大于一个像素的纹理需要更高的分配。这意味着,为了最大限度地提高内存利用率,你应该始终调整纹理的大小,使其与GPU分配一致,从而避免浪费空间。
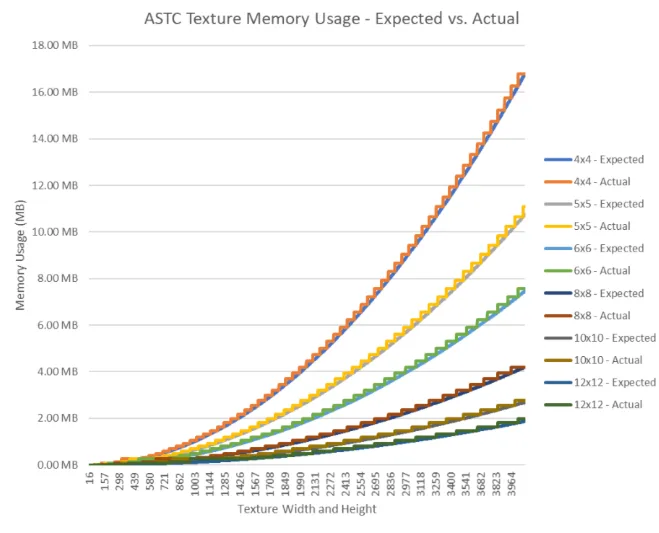
对于Square Block Sizes的Square ASTC Texture,以下大小可实现最有效的分配:
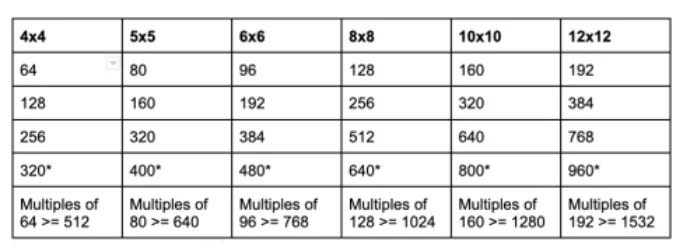
这种大小的纹理无法充分利用分配的131072字节,但再增加一个像素将使分配的大小加倍,达到262144字节。
对于Non-Square Block Sizes的Square ASTC Texture,以下大小最有效:

ASTC 10x5更接近于quare Block Sizes(这十分合理,因为它的比例为2:1):

◐ 5.6 最小化Unity“屏幕”大小
尽管VR应用不会直接渲染到屏幕,但Unity的默认行为是分配一个屏幕大小的纹理,并在每一帧中进行渲染。除了可能导致性能下降之外,这个屏幕大小的缓冲区同时占用了大量内存。你可以通过调用Screen.SetResolution(16, 16, true)将屏幕缓冲区的大小更改为最小,从而避免浪费空间。因为屏幕从来都都不可见,所以这一变化是一个纯粹的性能和内存优势。
◐ 5.7 利用本机Vulkan应用中“偷懒”分配的缓冲区
如果应用本机使用Vulkan,你可以使用VK_MEMORY_PROPERTY_LAZILY_ALLOCATED_BIT创建缓冲区,从而完全避免为只能在GPU tiled内存(如MSAA attachment)中访问的缓冲区分配内存。这个flag防止在需要缓冲区之前分配缓冲区内存。然而,对于只存在于tiled内存中的缓冲区,主内存中不需要空间,因此不会发生分配。
如果你有任何问题,请随时访问开发者论坛。










