苹果专利为AR/VR用户提出个性化显著性模型系统,更准确识别用户差异

显著性模型
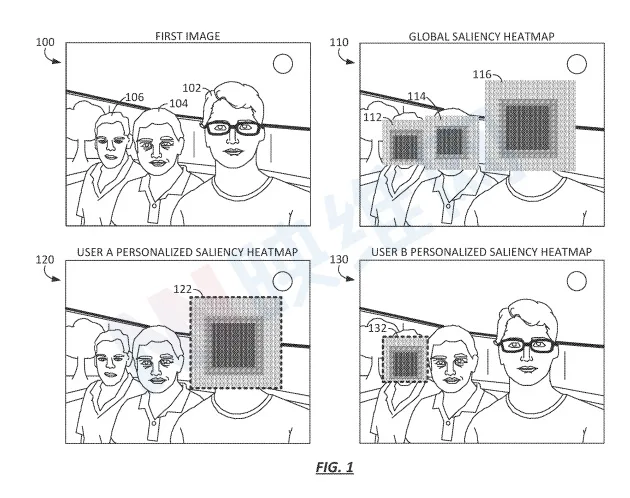
(映维网Nweon 2022年04月06日)显著性模型是指确定图像哪部分对用户而言属于重要的或“显著的”,而这种确定对于特定场景非常有用,例如摄影和混合现实。迄今为止,大多数显著性模型都是基于大型训练集进行训练,例如从代表不同背景、年龄、文化、地理位置等的大量用户收集的数据。但这种显著性模型可能无法准确反映特定用户的差异。
所以,为用户提供生成、训练、更新和/或与用户社区共享其“个性化”显著性模型的能力将十分有益。随着支持摄像头的设备数量激增,现在用户可以在一系列不同的环境和地理位置捕获任意数量的照片、视频和/或音频,并在设备存储数百张照片和其他媒体项目。另外,通过允许多名用户同时训练并与更大的用户群体分享其个性化显著性模型,这或能帮助开发出更准确、更复杂的全球显著性模型。
在名为“Systems and methods for providing personalized saliency models”的专利申请中,苹果就介绍了一种提供个性化显著性模型的系统和方法。简单来说,苹果可以向用户发送一个全球模型,然后利用用户自己拍摄的图像和视频,以众包方式由用户端设备训练模型。然后,经过训练的个性化又可以反哺全球模型。
......(全文 2829 字,剩余 2403 字)