融合ToF+NeRF,Meta提出TöRF,实现更优动态场景视图合成

视点合成
(映维网Nweon 2022年03月09日)新视点合成(Novel-View Synthesis;NVS)的目标是从新视点逼真地渲染图像,并且长期以来都是计算机图形学和计算机视觉领域的一个重要挑战。
给定从不同视点拍摄的大量图像,系统可以推断场景的几何结构和外观,并以新camera姿势合成图像。与NVS相关的一个问题是,它需要一组来自不同视角的不同图像以准确地表示场景。这可能涉及在静态环境中移动单个摄像头,或使用大型多摄像头系统从不同角度捕获动态事件。
单目视频序列中的动态NV技术展示了令人信服的结果,但由于具有不适定性,它们出现了各种视觉伪影。这需要在动态场景的深度和运动方面引入先验知识。同时,移动设备现在搭载了带有颜色和深度传感器的摄像系统,例如微软的HoloLens,以及iPhone和iPad Pro中的前后RGBD摄像系统。
深度传感器可以使用立体光或结构光,或者越来越精确的飞行时间测量原理。尽管深度传感技术比以往任何时候都更加普遍,但一系列的NVS技术目前都没有利用这种额外的视觉信息源。为了提高NVS性能,卡内基梅隆大学、布朗大学、康纳尔大学、巴斯大学和Meta的研究人员提出了TöRF。
这是一种利用颜色和飞行时间图像的场景外观隐式神经表示。与仅使用彩色摄像头相比,它可以减少静态NVS问题设置所需的图像数量。另外,附加的深度信息令单目动态NVS问题更容易处理,因为它直接编码有关场景几何体的信息。最重要的是,团队没有直接使用深度,而是使用通常用于推导深度的相量图像形式的“原生”ToF数据。这种方式更为准确,因为它允许优化以正确处理超出传感器明确范围的几何体、反射率低的对象,以及受多径干扰影响的区域,从而实现更好的动态场景视图合成。
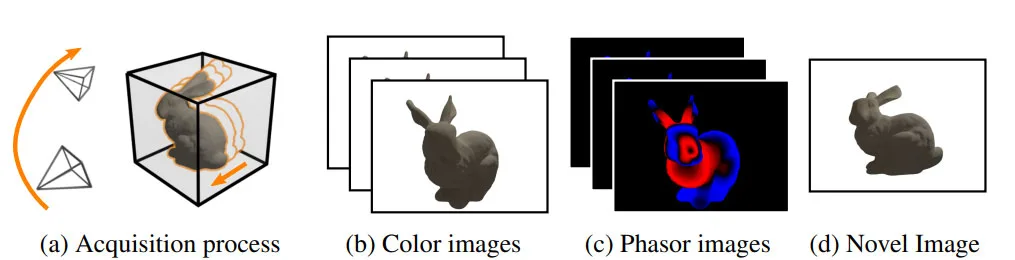
◐ 1. 用于ToF图像的Neural Volumes Rendering
Neural Volumes是一种用于学习、渲染和驱动动态对象的方法(动态对象使用外向内摄影头装备捕获)。由于统一的体素网格是用来模拟场景,这一方法适用于对象,而不是场景。由于场景的大部分都是由空的空间组成,所以Neural Volumes使用一个扭曲场来最大化可用分辨率的效用。然而,这种方法的有效性受到扭曲分辨率和网络以无监督方式学习复杂逆扭曲的能力的限制。
......(全文 3447 字,剩余 2671 字)