Meta专利分享如何减少AR/VR设备眼动追踪功耗

本地计算设备+头显的分布式设置
(映维网Nweon 2022年03月07日)眼动追踪越发成为头显的标准配置,各家厂商都在积极探索精确、轻型、紧凑和高成本效益的眼动追踪系统。早前映维网已经分享了一系列与所述主题相关的厂商发明,而美国专利商标局日前又公布了一份名为“Distributed sensor module for eye-tracking”的Meta专利申请。
对于眼动追踪,其中一个挑战是需要将功耗降到最低,从而优化可穿戴设备的形状参数设计和续航能力。一种降低功耗的方法是利用机器学习来执行目标追踪,但所述方式需要一个大型网络,而这不可避免地会产生功耗,并且不能提供足够精确的结果。
为了解决上述问题,Meta希望通过一个分布式设置来减少功耗,并提供足够精确的结果。简单来说,可以由头显搭载一个传感器模块,并由在与头戴式设备分离的本地计算设备中实现一个中央模块。然后,传感器模块来检测来自下采样图像的特征,从而执行对象追踪,而中央模块可处理传感器模块的任何潜在请求/服务。
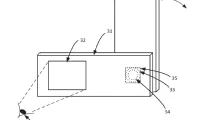
所述分布式传感器模块包括摄像头、存储单元、检测单元和计算单元,并用于通过机器学习模型从下采样的图像中有效地检测特定特征。以所述方式,传感器模块可以生成/计算特定于特征的图像,无需过度读取图像中的片段并降低功耗。
......(全文 3831 字,剩余 3366 字)