Meta为AR/VR宣布实时语音语言翻译计划:基于AI的通用语言翻译器

“用任何语言来与任何人交流的能力是一种梦寐以求的超能力,而人工智能将在我们的有生之年实现这一点。”
(映维网Nweon 2022年02月24日)Facebook、Instagram、WhatsApp和VR社交平台Horizon的母公司Meta日前宣布了一个雄心勃勃的全新AI研究项目:创建一个适用于“世界每个人”的通用语言翻译器。Meta首席执行官马克·扎克伯格表示:“用任何语言来与任何人交流的能力是一种梦寐以求的超能力,而人工智能将在我们的有生之年实现这一点。”
Meta日前举办了一个名为“Meta AI: Inside the Lab”的人工智能实验室揭秘活动。除了演示人工智能团队所取得的最新突破外,Meta同时希望进一步说明人工智能将如何赋能公司的元宇宙未来。
对于前述的通用语言翻译器计划,Meta撰文进行了详细的介绍,下面是映维网的具体整理:

对于母语为英文、中文或西班牙文等的不同人士,今天的应用程序和网络工具似乎已经提供了我们所需要的翻译技术。但目前依然数十亿人排除在外,他们无法轻松访问互联网的信息,同时无法用母语与大多数网络世界联系。今天的机器翻译(Machine Translation;MT)系统正在迅速进化,但它们严重依赖于从大量文本数据中学习,所以通常不适用于低资源语言(即缺乏训练数据的语言),以及没有标准化写作系统的语言。
消除语言障碍将是一项意义深远的工作:它将能帮助数十亿人以自己的母语或首选语言获取网络海洋的信息。机器翻译的进步不仅会帮助不懂当今主导互联网的语言的人士,它们将从根本上改变人们联系和分享想法的方式。
请想象一下,操着不同语言的人士能够通过电话、手表或眼镜实时相互交流,或者能够自由以自己喜欢的语言访问网络的多媒体内容。在不久的将来,当虚拟现实和增强现实等新兴技术将数字世界和物理世界结合在一起时,翻译工具将能帮助你与任何人交流,并在任何地方进行日常活动,例如举办读书俱乐部或合作开展工作项目等等。
所以,Meta AI日前宣布了一项旨在构建支持世界大多数语言的机器翻译工具的长期努力。这包括两个新项目:
- 第一个是No Language Left Behind(不落下任何语言)。团队正在构建一个可以从较少示例语言中学习的全新高级人工智能模型,并将其用于实现数百种语言的专家级翻译,例如阿斯图里安语,卢甘达语和乌尔都语。
- 第二个是Universal Speech Translator(通用语言翻译)。团队正在设计新的方法来实时将一种语言的语音翻译成另一种语言,从而支持没有标准书写系统的语言,以及既有书面语言又有口头语言的语言。
要为全世界所有人提供真正通用的翻译工具需要大量的努力。但Meta认为,这里描述的一切是向前迈出的重要一步。团队进一步指出,未来将分享开源相关的代码和模型细节。通过借助社区的力量,我们将能更接近实现这一重要目标。
◐ 1. 翻译每一种语言的挑战
当今的人工智能翻译系统并不是为了服务于世界各地使用的数千种语言,同时不是为了提供实时的语音到语音翻译。为了真正服务于每一个人,机器翻译研究业界需要克服三个重要挑战:
- 我们需要获取更多语言的更多训练数据,并找到利用现有数据的新方法,从而克服数据匮乏的问题。
- 我们需要克服随着模型向服务更多语言的方向发展而出现的建模挑战。
- 我们需要找到新的方法来评估和改进结果。
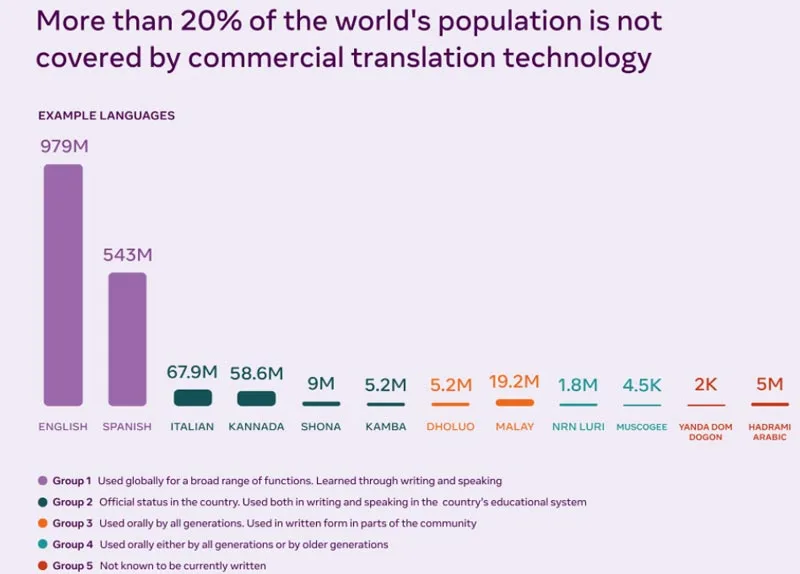
数据匮乏依然是跨更多语言扩展翻译工具的最大障碍之一。文本翻译的机器翻译系统通常依赖于从数百万个句子的注释数据中学习。所以,能够进行高质量翻译的机器翻译系统目前只为少数主导网络的语言开发。扩展到其他语言意味着为缺少网络存在感的语言寻找一种获取和使用训练示例的方法。
对于直接的语音到语音翻译,获取数据的挑战更为严峻。大多数语音机器翻译系统使用文本作为中间步骤,这意味着语音首先转换为文本,然后翻译为目标语言中的文本,最后再将其输入到文本到语音系统以生成音频。所以语音对语音的翻译依赖于文本,从而限制了其效率,使其难以扩展到主要是口语的语言。
直接语音到语音翻译模型可以为没有标准化写作系统的语言进行翻译。这种基于语音的方法可以带来更快速、更高效的翻译系统,因为它们不需要额外的步骤。
除了需要数千种语言的合适训练数据外,今天的机器翻译系统设计根本不能满足全球所有人的需求。大多数机器翻译系统都是双语,这意味着每个语言对都是一个单独的模式,例如日英语-俄语或日语-西班牙语。这种方法很难扩展到几十个语言对,更不用说全世界范围内的所有语言。想象一下,从泰语言,老挝语,再到尼泊尔语,每种组合都需要创建和维护数千种不同的模型。
一系列的专家建议多语言系统会有所帮助。但要将多种语言整合到一个高效、高性能、能够代表所有语言的多语言模型中非常困难。
实时语音对语音机器翻译模型面临一系列与基于文本的模型相同的挑战,并且需要克服延迟问题,然后才能有效地用于实现实时翻译。
主要的挑战基于这样一个事实:一个句子可以在不同的语言中以不同的语序表达。即便是专业的同声传译员都会落后于原始演讲约三秒中。例如,德语“Ich möchte alle Sprachen übersetzen”和对等的西班牙语“Quisiera traducir todos los idiomas”。两者的英文都是“I would like to translate all languages(我想翻译所有的语言)。”相较于西班牙语和英语(词序相似),从德语到英语的实时翻译将更具挑战性,因为对应于英语动词“translate(翻译)”的德语动词“übersetzen(翻译)”出现在句子的末尾。
最后,随着扩展到越来越多的语言,我们需要开发新的方法来评估机器翻译模型产生的结果。业界已经有资源来评估从英语到俄语的翻译质量,但从阿姆哈拉语到哈萨克语呢?
随着我们扩大机器翻译模型可以翻译的语言数量,我们同时必须开发新的方法来训练数据和测量结果。除了评估机器翻译系统的准确性外,确保负责人地翻译负责任同样重要。我们需要确保机器翻译系统保持文化敏感性,不制造或加剧偏见。
◐ 2. 训练低资源和直接语音翻译系统
为了实现低资源语言的翻译,并为未来更多语言的翻译创建构建模块,Meta正在扩展自动数据集创建技术。其中一种技术是开源工具包LASER,它现在包含了用28种不同脚本编写的125多种语言。
LASER可以将各种语言的句子转换成单一的多语言表达。然后,团队使用大规模多语言相似性搜索来识别具有相似表示的句子,即在不同语言中可能具有相同含义的句子。Meta已经利用LASET开发了在互联网中寻找平行文本的ccMatrix和ccAligned。由于低资源语言几乎没有可用的数据,团队创建了一种新的teacher-student训练方法,以便LASER能够专注于特定的语言亚组,并用更小的数据集进行学习。这使得LASER能够跨语言大规模有效运行。随着团队不断改进和扩展语言,并最终支持每种具有书写系统的语言,任何进步都将能帮助我们覆盖更多的语言。
Meta最近已经将LASER扩展成支持语音。:通过在同一个多语言空间中构建语音和文本的表示,其能够在一种语言的语音和另一种语言的文本之间提取翻译,甚至可以直接进行语音到语音的翻译。通过这种方法,团队已经识别了近1400小时的法语、德语、西班牙语和英语对齐语音。
文本数据非常重要,但不足以构建满足所有人需求的翻译工具。语音翻译基准数据以前可用于少数几种语言,所以团队创建了:
- CoVoST 2:涵盖22种语言和36个不同资源条件的语言方向
- VoxPopuli:包含23种语言的40万小时语音,可用于语音识别和语音翻译等语音应用的大规模半监督和自监督学习。
3. 构建跨多种语言和不同模式的模型
除了为机器翻译系统的训练提供更多数据,并将其提供给其他研究人员之外,Meta同时在努力提高模型的能力,从而能够处理更广泛语言之间的翻译。如今,机器翻译系统通常在单一模态中工作。如果模型太小,无法代表多种语言,其性能可能会受到影响,从而导致文本和语音翻译的不准确。建模方面的创新将帮助我们创造这样一个未来:翻译将能快速、无缝地支持多种语言的不同模式,例如语音到文本,文本到语音,文本到文本或语音到语音。
为了提高机器翻译模型的性能,Meta投入巨资创建了能够在大容量情况下高效训练的模型。为了将基于文本的机器翻译扩展到101种语言,团队创建了第一个非以英语为中心的多语言文本翻译系统。
双语系统通常是先从源语言翻译成英语,然后再从英语翻译成目标语言。为了令系统更高效、更高质量,团队取消了英语作为媒介,这样语言就可以直接翻译成其他语言,无需通过英语。当然,尽管消除英语提高了模型的容量,但多语言模型无法达到定制双语系统的质量水平。然而,随着性能的提升,Meta的多语言翻译系统赢得了Workshop on Machine Translation competition,甚至超过最好的双语模特。
Meta的目标是提高技术的包容性:它应该支持书面语言和没有标准书写系统的语言。考虑到这一点,团队正在开发一个语音到语音,不依赖于在推理过程中生成中间文本表示的翻译系统。这种方法已证明比传统的级联系统更快。凭借更高的效率和更简单的架构,直接语音翻译可以为未来的设备开启实时翻译。最后,为了创建能够保留每个人讲话中的表达能力和特点的口语翻译,团队正在努力在生成的音频翻译中包括输入音频的特定方面,例如语调。
◐ 4. 衡量数百种语言的成功
开发能够在多种语言之间转换的模型带来了一个重要的问题:如何确定是否开发出了一个更好的模型呢?评估一个大规模、多语言模型的性能是一件棘手的事情,尤其是因为它要求我们具备模型所涵盖的所有语言的专业知识。这是一项耗时、资源密集且往往不切实际的挑战。
针对这一点,Meta开发了第一个涵盖101种语言的多语言翻译评估数据集 FLORES-101,以便研究人员能够快速测试和改进多语言翻译模型。与现有的数据集不同,FLORES-101允许研究人员通过任何语言方向量化系统的性能,不仅仅只是翻译成英语和从英语翻译成其他语言。对于操着几十种官方语言的全球范围而言,这将能够创建满足重要现实世界需求的翻译系统。
利用FLORES-101,Meta正在与人工智能研究业界合作,并期待着继续将FLORES扩展到数百种语言。
Meta进一步指出,未来将致力于负责任地开展这项工作。团队正在与语言学家合作,以理解创造准确数据集所面临的挑战。团队同时与评估人员网络合作,以确保翻译的准确性。这家公司表示,实现长期的翻译目标不仅需要人工智能方面的专业知识,同时需要来自世界各地的众多专家、研究人员和个人的持续投入。
◐ 5. 未来
如果No Language Left Behind(不落下任何语言)和Universal Speech Translator能够成功,再加上机器翻译研究业界的努力,这将能以前所未有的方式融合数字世界和物理世界。
Meta最后总结道:“在我们努力建设一个更包容、更互联的世界时,更重要的是要打破现有的信息和机会障碍,允许人们能够使用自己所选择的语言。”










