为助力AR/VR元宇宙愿景,Meta发布人工智能超级计算机RSC

在2022年年中实现完全建成的RSC会成为世界最快的人工智能超级计算机
(映维网Nweon 2022年01月25日)为了助力AR/VR元宇宙的愿景,Meta日前发布了名为“AI Research SuperCluster(人工智能研究超级集群;RSC)”的人工智能超级计算机。

Meta表示,尚未建成的RSC依然是目前世界运行速度最快的人工智能超级计算机之一,而将在2022年年中实现完全建成的RSC会成为世界最快的人工智能超级计算机。
自2013年以来,Meta在人工智能领域已经取得了长足的进展,包括算法可以从大量未标记示例和transformer中学习的自监督学习。但视觉、语音、语言等各个领域都需要越来越多的训练和越来越复杂的模型,特别是对于识别有害内容等关键用例。为了充分实现高阶人工智能的潜能,并帮助实现公司的元宇宙愿景,Meta认为加快进展的最佳方式是设计一个全新的计算基础设施——RSC。
团队的研究人员已经开始就自然语言处理(NLP)和计算机视觉使用RSC训练模型,目标是在一天内训练具有数万亿参数的模型。
RSC将帮助Meta的人工智能研究人员建立可以从数万亿个示例中学习、支持数百种不同语言、无缝分析文本、图像和视频、开发全新的增强现实工具的优秀人工智能模型。
Meta表示:“我们希望RSC能够帮助构建全新的人工智能系统,例如为使用不同语言的人群提供实时语音翻译,这样大家就可以就研究项目无缝协作,或者一起畅玩AR增强现实游戏。最终,基于RSC的研究将为下一个主要计算平台的建设铺平道路,亦即元宇宙。人工智能驱动的应用和产品将在元宇宙中发挥重要作用。”

◐ 1. 为什么需要这样规模的人工智能超级计算机?
自2013年创建Facebook AI Research lab以来,Meta一直致力于对人工智能的长期投资。如上面所述,2013年以来,Meta在人工智能领域已经取得了长足的进展,包括算法可以从大量未标记示例和transformer中学习的自监督学习。但视觉、语音、语言等各个领域都需要越来越多的训练和越来越复杂的模型,特别是对于识别有害内容等关键用例。
例如,计算机视觉需要以更高的数据采样率处理更大、更长的视频。即使是派对或音乐会等存在大量背景噪音的挑战性场景中,语音识别都需要出色地完成工作。另一方面,NLP需要理解更多的语言、方言和口音。
机器人技术、具身化人工智能和多模态人工智能等领域地进步将能帮助人们在现实世界中完成有用的任务。
高性能计算基础设施是训练这种大型模型的关键组成要素,而Meta的人工智能研究团队多年来一直在努力构建高性能系统。
第一代设计于2017年落成,一个集群拥有22000个NVIDIA V100 Tensor Core GPU,每天执行35000个训练任务。
2020年初,团队认为加快进展的最佳方式是从零开始设计全新的计算基础设施,从而利用新的GPU和network fabric技术。他们希望所述基础设施能够在一个EB大小的数据集中训练拥有超过一万亿个参数的模型。作为对比,这相当于36000年的高质量视频。
Meta表示,将确保所有必要的安全和隐私控制,以保护其使用的任何训练数据。与之前只利用开源和其他公开可用数据集的人工智能研究基础设施不同,RSC同时能够帮助研究有效地转化为实践,允许研究人员在模型训练中包括Meta生产系统的真实示例。以这种方式,团队可以帮助推进执行下游任务的研究,例如识别平台的有害内容,以及探索具身化人工智能和多模态人工智能以帮助改善应用的用户体验。这家公司表示:“我们相信这是第一次有人以这等规模解决性能、可靠性、安全性和隐私问题。”
◐ 2. RSC
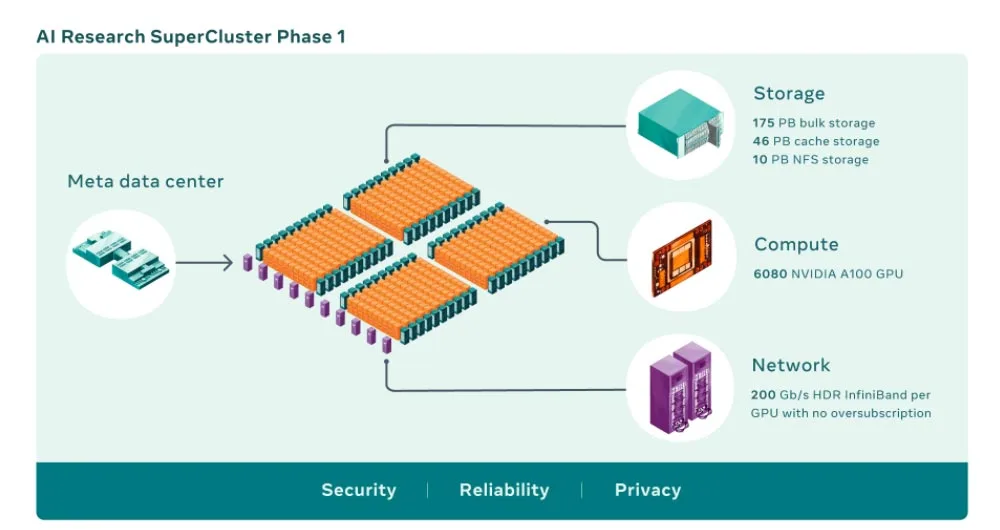
人工智能超级计算机将多个GPU组合成计算节点,然后再通过高性能network fabric连接起来,以允许GPU之间的快速通信。如今,RSC共有760个NVIDIA DGX A100系统作为计算节点,总计6080个GPU,而每个A100 GPU的功能都比之前系统中的V100强大。GPU通过NVIDIA Quantum 200 Gb/s InfiniBand two-level Clos fabric进行通信。RSC的存储层拥有175 PB的Pure Storage FlashArray、46 PB的Penguin Computing Altus系统缓存和10 PB的Pure Storage FlashBlade。
RSC的早期基准表明,与Meta的传统生产和研究基础设施相比,它运行计算机视觉工作流的速度要高出20倍,运行VIDIA Collective Communication Library(NCL)高出9倍,并且训练NLP模型的速度高出3倍。这意味着一个拥有数百亿个参数的模型可以在三周内完成训练,而之前则是九周。
◐ 3. 建造人工智能超级计算机…
设计和建造类似RSC的产品不仅仅是性能问题,而是要使用当今最先进的技术,并且以尽可能大的规模实现性能。RSC完成后,InfiniBand network fabric将连接16000个GPU作为端点,使其成为迄今为止部署的最大同类网络之一。另外,团队设计了一个可以服务16 TB/s训练数据的缓存和存储系统。同时,他们计划将其扩展到1 EB。
所述基础设施必须非常可靠,因为可能出现需要运行数周,需要数千个GPU的实验。最后,使用RSC的整个体验必须对研究人员友好,这样团队就可以轻松探索各种人工智能模型。
实现这一目标并不容易,所以Meta与一系列厂商进行了长期合作,例如架构和托管服务合作伙伴Penguin Computing与Meta运营团队合作进行硬件集成;Pure Storage为Meta提供了一个稳健且可扩展的存储解决方案;英伟达则带来了一系列的人工智能计算技术,包括尖端系统、GPU和InfiniBand fabric,以及NCLL等用于集群的软件堆栈组件。
◐ 4. …在疫情期间远程执行
但在RSC的发展过程中出现了其他意想不到的挑战:新冠疫情。RSC最初是一个完全远程的项目。团队在大约一年半的时间里将它从一个简单的共享文档变成了一个功能正常的集群。疫情及晶圆供应限制产生了供应链问题,使得从芯片到光学器件和GPU等各种组件变得难以获取,甚至建筑材料都必须按照新的安全协议进行运输。

为了高效地构建这个集群,Meta必须从零开始设计。团队必须围绕数据中心的设计制定新的规则,包括冷却、电源、机架布局、布线和网络、以及其他重要考虑因素。另外,这家公司必须确保从施工到硬件,再到软件和人工智能的所有团队都与合作伙伴协调一致地工作。
除了核心系统本身,RSC同时需要一个功能强大的存储解决方案,一个能够从一个EB级存储系统提供TB带宽的解决方案。为了满足人工智能培训不断增长的带宽和容量需求,团队从零开发了一种存储服务:AI Research Store(AIRStore)。为了优化人工智能模型,AIRStore利用了一个全新的数据准备阶段来对用于训练的数据集进行预处理。一旦完成,准备好的数据集就可以用于多次训练,直到到期。AIRStore同时优化了数据传输,从而将Meta数据中心主干的跨区域流量降至最低。
◐ 5. 保护RSC中的数据
RSC的设计从一开始就考虑到了隐私和安全性,这样Meta的研究人员就可以通过加密的用户生成数据来安全地训练模型。数据在训练前都不会解密。例如,RSC与互联网隔离,没有直接的入站或出站连接,流量只能从Meta的数据中心流出。
为了满足相关隐私和安全要求,从存储系统到GPU的整个数据路径都是端到端加密,并且提供了必要的工具和流程来验证相关要求是否始终得到满足。在将数据导入RSC之前,它必须经过隐私审查流程,以确认其已正确匿名。然后,对数据进行加密,并定期删除解密密钥,以确保旧数据无法访问。而且,由于数据只在内存中的一个端点解密,所以即便是出现设施物理破坏事件,数据都能得到保护。
◐ 6. 第二阶段及以后
RSC目前已投入运行,但尚未完全建成。Meta表示,一旦完成RSC的第二阶段建设,它将成为世界速度最快的人工智能超级计算机,其混合精度计算的执行速度将达到近5 exaflops。到2022年,团队将努力把GPU的数量从6080增加到16000,从而令人工智能训练性能提高2.5倍以上。同时,InfiniBand fabric将扩展成在两层拓扑中支持16000个端口。为满足不断增长的需求,存储系统的目标传输带宽则为16 TB/s,容量为EB。
Meta表示:“我们希望计算能力的跃阶变化不仅能帮助我们为现有服务创建更精确的人工智能模型,同时能够实现全新的用户体验,尤其是在元宇宙之中。我们在自我监督学习和利用RSC构建下一代人工智能基础设施方面的长期投资正在帮助我们创造为元宇宙提供动力,并推动更广泛的人工智能社区前进的基础技术。”