微软专利介绍用机器学习为HoloLens用户提供完整面部显示效果

计算补充完整用户面部图像
(映维网 2021年12月20日)在进行视频通话时,任何头戴式显示器系统都必须克服的一个基本问题是:如何呈现用户的完整面部。挑战在于,头显遮蔽面部,尤其是眼睛;用户通常是可以移动;以及用户不在合适的捕获设备的视场范围内。
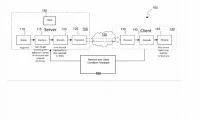
在名为“Computing images of head mounted display wearer”的专利申请中,微软介绍了一种利用机器学习装置来计算补充完整用户面部图像的方法和系统。
图1是佩戴头显102并参与视频会议呼叫的人员100的示意图,其中远程方112将所述人员感知成没有佩戴头显时的形象。
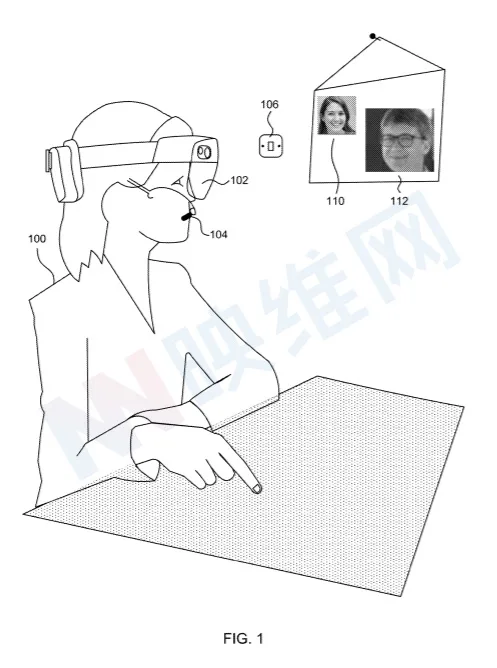
在一个实现中,图1中的示例涉及非对称头显视频呼叫,其中远程方112可以使用传统显示器,例如带有集成网络摄像头的笔记本电脑。远程方112从本地用户接收虚拟网络摄像头流,其中用户100可以描述为没有佩戴头显时的形象,并且其面部表情与用户100的真实面部表情匹配。虚拟网络摄像头的视点是根据用户偏好预先配置或设置。
在图1的示例中,存在两个额外的面向面部的捕获设备,但由于它们被HMD主体遮挡,因此不可见。两个附加的面部面向捕获设备包括第一眼睛面向捕获设备和第二眼睛面向捕获设备。第一和第二眼睛面向捕获设备可以分别是面向右眼的捕获设备和面向左眼的捕获设备,并且可以是红外捕获设备。第一和第二眼睛面向捕获设备的视场布置成包括眼睛本身、鼻子的一部分以及眼睛周围的脸颊区域。
......(全文 2606 字,剩余 2098 字)