Meta研究员探索用posed RGB video进行对象检测、关联和映射

对象检测,关联和映射的方法
(映维网 2021年12月08日)赋予机器感知推断3D对象映射的能力能够帮助人工智能系统更接近对世界的语义理解。所述任务需要构建场景的一致3D对象映射。在名为《ODAM: Object Detection, Association, and Mapping using Posed RGB Video》的论文中,Meta和阿德莱德大学的研究人员探索了一种利用posed RGB video来进行对象检测,关联和映射的方法。
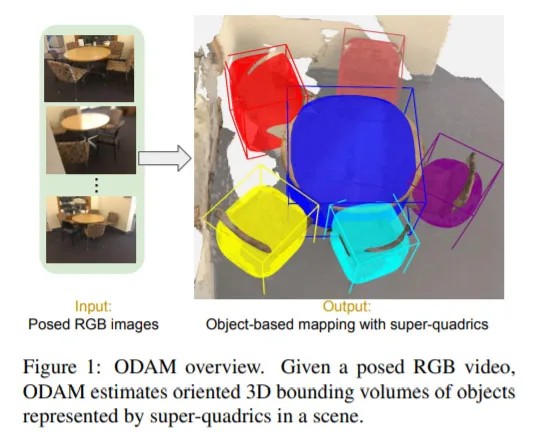
研究人员关注类别级语义重建和对象映射之间的空间,并通过来自姿态RGB帧的3D bounding volume来表示对象。与在图像中使用2D bounding boxs(BBs)类似,3D bounding volume提供了位置和空间的抽象,例如可用于在对象实例锚定信息。
通过诸如NeRF和GRAF等先进方法来可靠地推断场景中单个对象的bounding volume和相关视图是重建、嵌入和描述对象的垫脚石。然而,使用RGB-only视频在3D中定位对象并估计其范围的任务带来了众多挑战。
首先,尽管2D对象检测器的深度学习方法取得了令人印象深刻的成功,但由于透视投影中的深度比例模糊性,其精度受到了影响;其次,关于如何将多视图约束用于3D bounding volume位置和范围的研究和共识很少。
具体而言,3D volume的表示以及如何制定合适的能量函数依然是一个开放的问题;第三,在多视图优化之前需要解决的关键问题是,从不同角度检测单个3D对象实例的关联。与SfM或SLAM不同,不正确的关联会显著地影响3D对象定位。不过,这一问题在杂乱的室内环境中尚未得到充分的研究。在所述环境中,诸如具有几乎相同视觉外观和严重遮挡的多个对象是常见的具体问题。深度模糊和局部观测使数据关联问题复杂化。
......(全文 1758 字,剩余 1214 字)








