根据单张图像重建人体模型,Meta提出ARCH++

根据单张图像重建人体模型
(映维网 2021年11月17日)数字人类已经成为众多AR/VR应用的重要组成一环,如游戏和社交。为了获得真正的沉浸式体验,虚拟化身要实现超越恐怖谷效应的更高层次真实感。建立一个照片级真实感的虚拟化身需要美术的大量手工劳动或置于受控环境中的昂贵捕获系统,而这限制了普及性并增加了成本。所以,在未来的数字人体应用中,以最小的先决条件(如自拍)革新重建技术至关重要。
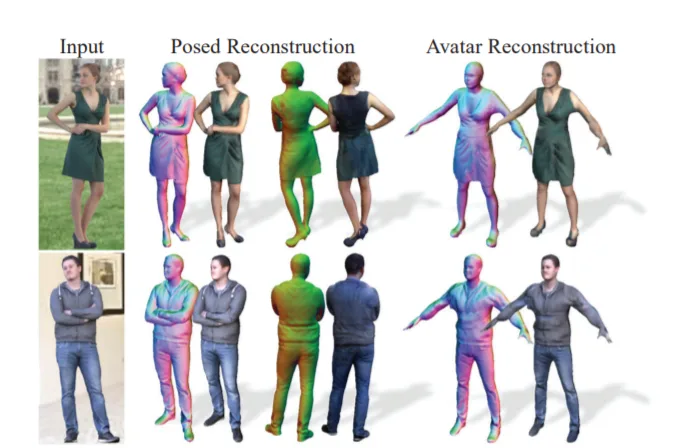
最近根据单张图像重建的人体模型结合了之前的特定类别数据和图像观察。其中,基于模板的方法依然缺乏保真度,难以支持服装变化。尽管非参数重建方法逼真度令人印象深刻,但无法提供直观的方法来为重建的虚拟化身制作动画。在最近的研究ARCH中,研究人员建议在canonical空间中使用像素对齐的隐式函数来重建非参数人体模型,其中所有重建的虚拟化身都转换为公共姿势。为此,利用参数化人体模型确定变换。通过转移蒙皮权重,重建结果可以设置动画。但是,参数化身体模型和像素对齐隐式函数的优势没有得到充分利用。
在名为《ARCH++: Animation-Ready Clothed Human Reconstruction Revisited》的论文中,Facebook和加利福尼亚大学提出了ARCH++。它回顾了从图像重建可动画虚拟化身的主要步骤,并解决了先前研究在公式和表示方面的局限性。首先,当前基于隐式函数的方法主要使用手动制作的特征作为三维空间表示,其存在深度模糊和缺乏人体语义信息的问题。
......(全文 1715 字,剩余 1197 字)











