Facebook提出Neural-GIF模型,为AR/VR模拟复杂衣服穿着效果

动画化穿衣人物
(映维网 2021年10月26日)人类虚拟化身能够实现与增强现实和虚拟现实相关的众多应用,例如用于增强通信和娱乐的远程临场感。人体形状根据关节、软组织和非刚性服装动力学变形,这使得真实动画极具挑战性。最先进的人体模型通常学习变形固定拓扑模板,使用线性混合蒙皮来建模关节,及通过混合形状来建模非刚性效果,这甚至包括软组织和衣服。使用固定模板会限制可建模的衣服类型和动力学。例如,使用一个或多个预定义模板对对象建模将十分困难。
另外,每种类型的变形(软组织或衣服)都需要不同的模型公式。然后,为了训练模型,3D/4D扫描需要与之对应,而这是一项具有挑战性的任务,尤其是对于服装。最近的研究利用隐式函数表示从图像或三维点云重建人体形状。但是,所述重建都为静态,不可设置动画。
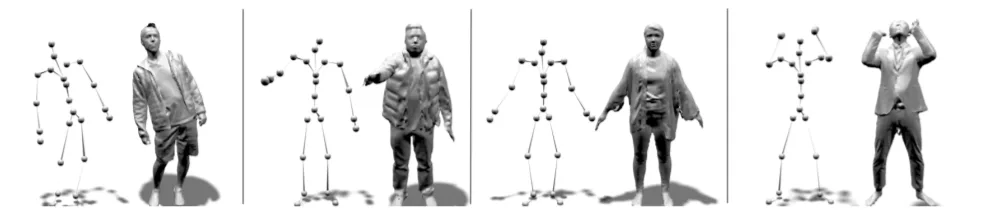
在名为《Neural-GIF: Neural Generalized Implicit Functions for Animating People in Clothing》的论文中,图宾根大学、马克斯-普朗克研究所和Facebook组成的团队提出了一个名为Neural Generalized Implicit Functions (Neural-GIF) 的全新模型来动画化穿衣人物。团队证明,可以以传统方法所难以实现的质量来对复杂的服装和身体变形进行建模。与大多数以前的研究相比,研究人员提出的模型学习姿势相关的变形,无需注册任何预定义模板,因为这会降低观测的分辨率,并且是一个众所周知的复杂步骤。相反,这一模型只需要输入扫描的姿态以及SMPL形状参数(β)。所述方法的另一个关键优势是,它可以使用完全相同的公式表示不同的拓扑结构。在研究中,团队同时展示了如何为未穿衣服的人物制作夹克、外套、裙子和软组织的动画。
......(全文 1268 字,剩余 697 字)