苏黎世联邦理工学院研究通过12个小型无线电磁传感器追踪人体姿态

通过12个小型无线电磁传感器来追踪人体姿态
(映维网 2021年10月12日)苏黎世联邦理工学院的先进交互技术实验室(Advanced Interactive Technologies;AIT)专注于而研究机器学习、计算机视觉和人机交互的交叉融合。团队的主要任务是开发人类与复杂交互系统互的新方法,比如说计算机、可穿戴设备和机器人。
日前,AIT实验室撰文介绍了一个面向AR/VR的定制电磁传感系统,通过12个小型无线电磁传感器来追踪人体姿态。下面是映维网的整理:
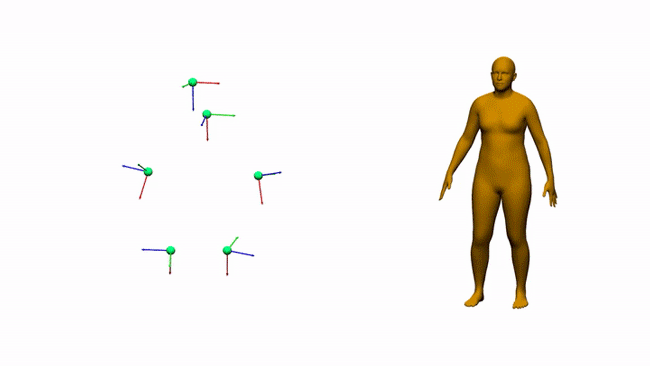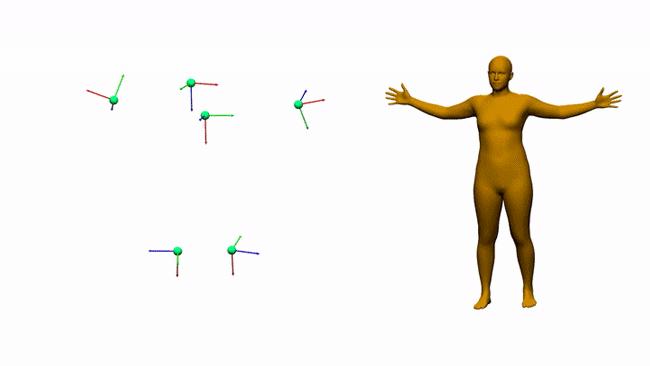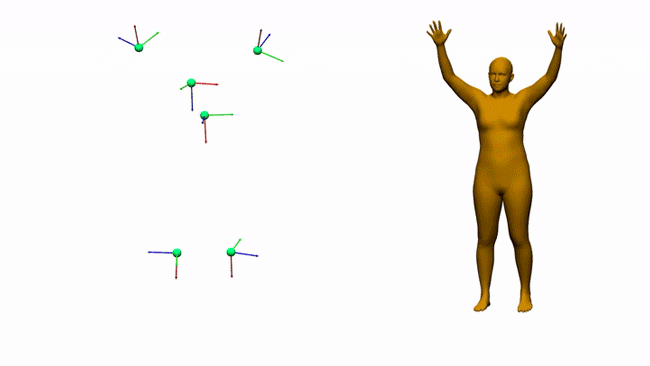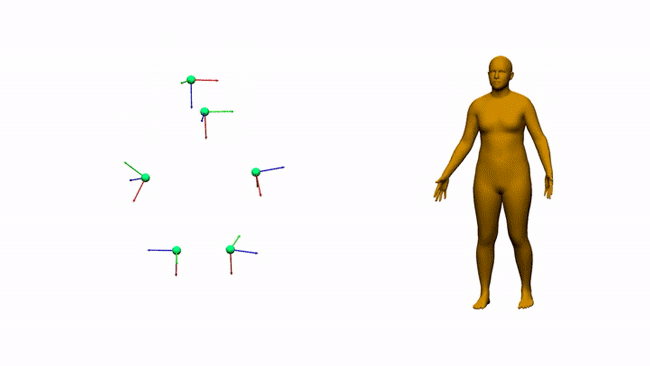
AIT实验室通过6个电磁测量估计三维人体姿态和形状
对于娱乐、通信、医疗和远程显示等领域,AR和VR是一个富有前景的计算平台。沉浸式AR/VR体验的一个重要组成环节是精确重建用户全身姿态的方法。尽管消费者传感器的姿态估计在近几年取得了令人印象深刻的进展,但对外部摄像头的需求固有地限制了用户的移动性。身戴式传感器(附接到身体/由身体穿戴的传感器)则有望避免这一限制,但它同时存在自身的挑战。我们在这个项目中研究了基于电磁(EM)的追踪传感技术,用6-12个没有Line-of-Sight(LOS)视线限制的定制无线EM传感器来进行人体追踪。
......(全文 2044 字,剩余 1640 字)











