谷歌发布MediaPipe Holistic,优化人体姿态、面部和手部

查看引用/信息源请点击:映维网
具有优化的姿态、面部和手部组件
(映维网 2020年12月11日)支持移动设备实时、同步地感知人体姿态和面部特征并进行手部追踪,这可以实现多种有影响力的应用,如健身和运动分析、手势控制和手语识别、以及增强现实效果等等。开源框架MediaPipe专门为利用加速推理的复杂感知管道而设计(如GPU或CPU),而它已经在为上述任务提供快速而精确的解决方案。将它们实时地组合成一个语义一致的端到端解决方案是一个独特的难题,需要多个相互依赖的神经网络同时进行推理。
谷歌日前正式发布了MediaPipe Holistic。这个旨在解决上述挑战的方案提供了一种新颖的、先进的人体姿态拓扑,并可以打开全新的用例。MediaPipe Holistic由一个全新的管道组成,而所述管道具有优化的姿态、面部和手部组件。每个组件都实时运行,推理后端之间的内存传输最少,并且根据质量/速度权衡增加了对三个组件互换性的支持。当包含这三个组件时,MediaPipe Holistic能够为540多个关键点提供统一的拓扑结构,并在移动设备实现近乎实时的性能。MediaPipe Holistic将作为MediaPipe的一部分发布,可用于移动设备(Android、iOS)和PC桌面。谷歌同时为研究(Python)和Web(JavaScript)发布了全新的即用API,以方便大家对所述技术的访问。

最上方:MediaPipe Holistic对体育和舞蹈用例的结果。最下方:“别出声”和“你好”手势。请注意,谷歌的解决方案始终将手识别为右(蓝色)或左(橙色)。
1. 管道和质量
MediaPipe Holistic管道集成了姿态、面部和手部组件的单独模型,每个模型都针对特定领域进行了优化。但由于它们的专长不同,对一个组件的输入并不适合其他组件。例如,姿态估计模型以较低的、固定分辨率的视频帧(256x256)作为输入。但如果要从图像中裁剪手部和面部区域以传递给各自的模型,图像分辨率会过低,无法准确表达。所以,谷歌将MediaPipe Holistic设计为一个多级管道,使用一个区域适配图像分辨率来处理不同的区域。
首先,MediaPipe Holistic通过BlazePose的姿态检测器和随后的关键点模型估计人体姿态。然后,使用推断出的姿态关键点,为每只手(2x)和面部导出三个感兴趣区域(ROI;Region of Interest)裁剪,并使用重新裁剪模型来提升ROI。然后,管道将全分辨率输入帧裁剪到ROI之中,并应用特定于任务的面部和手部模型来估计它们的对应关键点。最后,将所有关键点与姿态模型的关键点合并,并得到完整的540+个关键点。
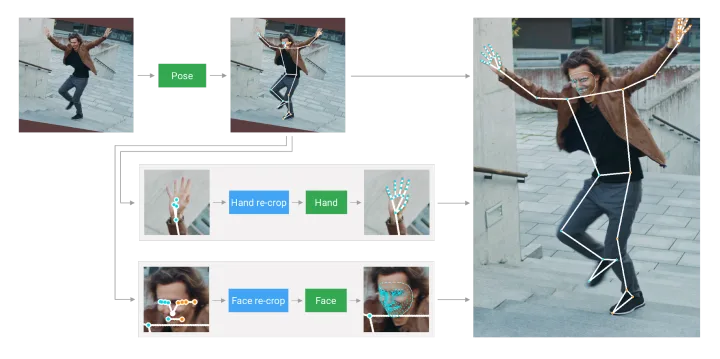
管道概览
为了简化ROI的识别,团队采用了一种类似用于独立面部和手部管道的追踪方法。所述方法假设对象在帧之间没有显著移动,然后使用前一帧的估计作为当前帧的对象区域的引导。但在快速移动过程中,追踪器可能会丢失目标,所以这需要探测器在图像中重新定位目标。MediaPipe Holistic先使用姿态预测作为额外的ROI,以减少管道对快速移动的响应时间。这同时使得模型能够防止左右手或一个人的身体部分与另一个人的身体部分之间出现混淆,从而保持整个身体及其各部分的语义一致性。
另外,姿态模型的输入帧分辨率很低,所以生成的面部和手部ROI依然不够准确,无法引导所述区域的重新裁剪(所述区域需要精确的输入裁剪以保持轻量化)。为了缩小精度差距,团队使用了轻量级的面部和手部重裁剪模型,而它们起到了空间变换器的作用,其推理时间仅为相应模型的10%左右。
| - | MEH | FLE |
| 追踪管道(基线) | 9.8% | 3.1% |
| 不含重新裁剪的管道 | 11.8% | 3.5% |
| 含重新裁剪的管道 | 9.7% | 3.1% |
手部预测质量。每只手的平均误差(MEH)已经根据手部尺寸归一化。用瞳孔间距离对人脸标志误差(FLE)进行归一化处理。
2. 性能
MediaPipe Holistic需要每个帧最多8个模型之间的协调:1个姿态检测器、1个姿态特征模型、3个重新裁剪模型、以及3个用于手部和面部的关键点模型。在构建解决方案时,团队不仅优化了机器学习模型,同时优化了预处理和后处理算法(如仿射变换)。因为由于管道的复杂性,所述算法对于大多数设备而言都需要花费大量时间。在这种情况下,根据设备的不同,将所有预处理计算转移到GPU会导致大约1.5倍的总体管道加速。所以即便是在中端设备和浏览器中,MediaPipe Holistic都能以近乎实时的性能运行。
| Phone | FPS |
| Google Pixel 2 XL | 18 |
| Samsung S9+ | 20 |
| 15-inch MacBook Pro 2017 | 15 |
各种中端设备的性能,使用TFLite GPU以每秒帧数进行测量。
管道的多阶段特性提供了另外两个性能优势。由于模型大多独立,所以根据性能和精度要求,可以使用更轻量级或更重量级的版本替换它们。另外,一旦推断出姿态,就可以精确地判断手和脸是否在帧边界内,从而允许管道跳过对所述身体部位的推断。
◐ 3. 应用
覆盖540多个关键点的MediaPipe Holistic旨在实现对肢体语言、手势和面部表情进行整体的和同步的感知。这种混合方法支持远程手势界面,以及全身AR、运动分析和手语识别。为了展示MediaPipe Holistic的质量和性能,团队构建了一个能够在浏览器本地运行的简单远程控制界面,并实现了引人入胜的用户交互。无需鼠标或键盘,用户可以通过动作操作屏幕中的对象,通过虚拟键盘键入文本,并通过指向或触碰特定的面部区域实现不同的动作,如静音或关闭摄像头。这依靠精确的手部检测,随后的手势识别将映射到一个固定在用户肩膀的“触控板”空间,从而实现了4米以内的远程控制。
在其他人机交互方式都不便使用的情况下,这种手势控制方式能够解锁一系列的新用例。你可以通过这个Web Demo进行尝试,并用它制作你构思的概念的原型。

落实控制演示。左:掌心拾取器,触控界面,键盘。右:远程触控键盘。
4. 研究与Web
为了加速机器学习的研究以及它在Web开发者社区中的采用,MediaPipe现在提供了面向Python和JavaScript的可定制机器学习解决方案。你可以直接通过Web浏览器进行尝试:对于Python,请使用Google Colab和Notebook;对于JavaScript,请使用CodePen和你的网络摄像头输入。
◐ 5. 总结
谷歌表示:“我们希望MediaPipe Holistic将激励研发社区成员构建新的和独特的应用程序。我们预计所述管道将为未来研究具有挑战性的领域开辟道路,如手语识别、裸手控制界面或其他复杂的用例。我们非常期待你的创意。”
复杂和动态的手势。视频来源Bill Vicars