Arm分享:从科幻到现实,移动端全息显示计算的发展进步

全息图无处不在,而它们很快就会出现在我们的面前
(映维网 2020年11月06日)你或许没有注意到,但全息图早已存在于我们的日常生活之中。由于难以复制,模拟全息图被广泛用作信用卡、银行票据、驾照和众多应用的防伪措施(见图1)。
随着计算能力的提高和增强现实等新用例的出现,数字全息显示的研究和开发同样在不断地进行。在展示先进视觉化未来的时候,一众热门的科幻电影和电视都有受到全息显示的启发,例如《星球大战》、《少数派报告》和《星际迷航》等。但全息显示真的是一个遥远的未来吗?在这篇博文中,Arm的软件工程师主任罗伯托·洛佩兹·门德斯(Roberto Lopez Mendez)介绍了有助于移动处理器支持全息显示的算法与计算进步。下面是映维网的具体整理:

图1:钞票(左)和信用卡(右)都有使用全息图作为防伪手段。
我们首先来看看经典全息图的产生过程:
1. 记录和再现全息图的起源
在计算机时代以前,模拟全息图的记录和再现方式与黑胶唱片相似。在这个过程中,两束激光束照射目标对象(图2)。由此产生的干涉图(全息图)编码了对象的整体(“全息”)相位信息,并以极高的分辨率记录在感光胶片上。当用激光照射胶片时(图2),发生的衍射会再现一个播放场,而它在眼睛看来是一个三维图像。这个图像完美地再现了所记录的对象,因为它保留了原始场景的深度、视差和其他属性。作为一名物理学家,这是我在大学学习全息术时所熟知的过程。
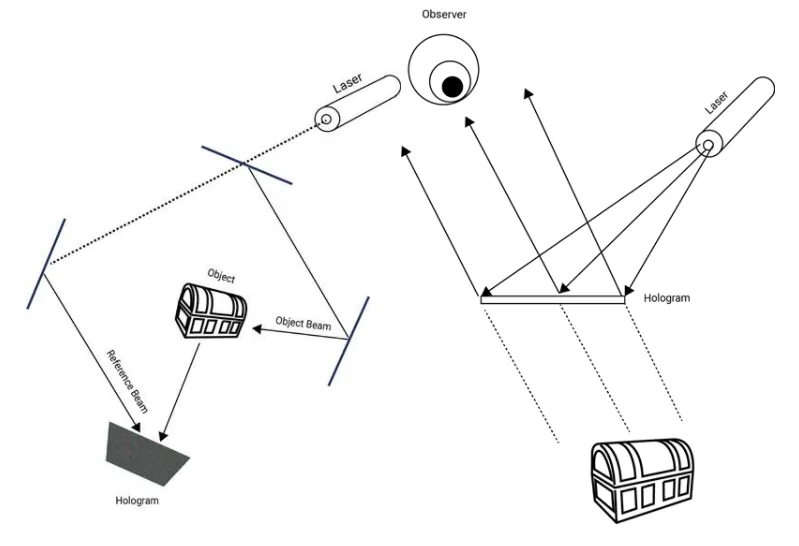
图2:经典全息图的创建(左)与播放(右)。图源:VividQ。
在上一篇博文中,我们介绍了Arm与英国初创企业VividQ达成合作,共同致力于帮助消费电子产品实现数字全息显示。在计算全息(Computer-Generated Holography;CGH)中,干涉图案是根据各种数据源(从游戏引擎到深度感应摄像头)并以数字方式生成,然后再通过一个微型显示器进行显示。其中,所述显示器相当于经典全息图中的感光胶片,并且在用激光照射时可以同样地再现三维图像。但CGH的计算量非常巨大,在过去一副数字全息图像的生成需要耗费数天时间。当第一次访问离Arm剑桥总部不远的VividQ时,我简直不敢相信眼前的一切。采用VividQ软件实现的全息显示器原型能够在我面前实时地投射出一个Unity动画场景的3D全息视频。我感到非常不可思议。下面我们来看看这一切是如何实现的。
2. 数字全息术的革命:基于快速傅里叶变换(Fast Fourier Transform;FFT)的全息图生成
传统的计算全息术是用基点计算(Point-Based Compute;PBC)来实现。三维虚拟对象可以表示为点云,点云携带颜色和深度信息。在PBC中,计算虚拟对象的每个点到显示器的每个像素的光线,并将相关值相加。这一过程所需的计算能力非常巨大,并且会随着分辨率的增大而急剧扩展:大约需要O(N4)运算,其中N是显示器的边长。
业界直到数年前才真正提出了实际的解决方案,而这个突破就像是从模拟音频处理到数字音频处理的转变。对于音乐,数字化过程以固定的时间间隔对音频信号进行采样。相比之下,全息领域的新举措是对三维虚拟对象的深度切片进行采样。图3总结了用于全息投影的切片过程和干涉图(全息图)的生成。
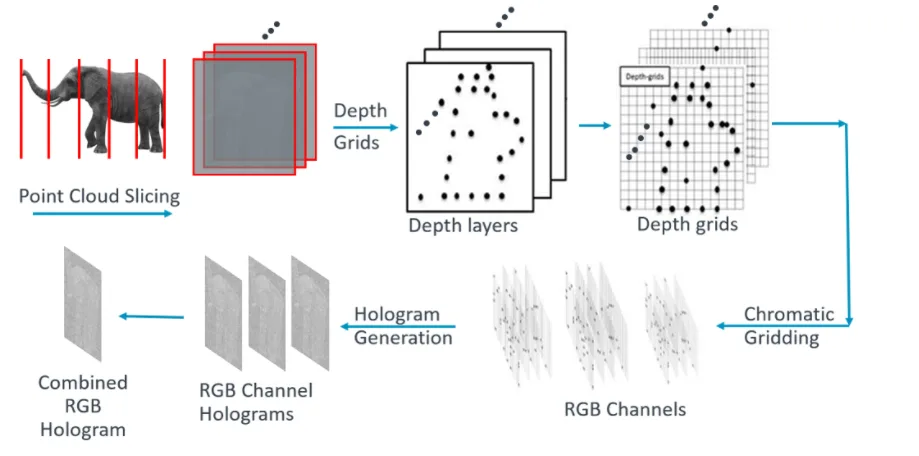
图3:基于FFT的CGH管道
在切片过程中,点云的每个点被划分为深度层。在下一步中,深度层将重新采样并栅格化为深度网格。在这个阶段,每个深度栅格包含处于相同深度的点。在实际应用中,每个深度网格可以看作是一个二维图像,而每个深度层的点可以有效地视为像素。这种分层方法允许我们将计算全息问题简化为具有O(N2 log N)时间复杂度的快速傅立叶变换问题(其中N是显示器的边长)。接下来,我们进行色度网格划分,将深度网格划分为RGB通道。然后利用FFT对深度网格进行衍射计算,并且生成全息图。每个RGB通道都需要自己的FFT计算,因为衍射速率取决于每个颜色波长。最后,将RGB通道全息图合并成单色全息图。
当生成全息图(干涉图)后,我们应该在哪里记录或打印并用激光束重建及产生全息投影呢?数字技术已经在这一领域获得长足的进步,所谓的空间光调制器(SLM)取代了模拟胶片。SLM可以动态显示计算出的衍射图样,并在用红绿蓝三种激光二极管照明时产生全息投影。
显然,这是全息图生成过程的一个简略版本,我们在这里没有考虑与显示器本身相关的技术挑战。然而,我们可以看到所需的计算能力将随深度层的数量和深度网格的分辨率提升而增加。随着层数的增加,我们可以预期FFT计算的权重将更加显著。GPU在并行计算方面非常出色。它们可以充分利用运算能力,而高端GPU的运算能力通常更为强大。这就是为什么今天全息图生成过程的推荐计算单元是GPU的原因。
在访问VividQ期间,我尝试了团队研发的全息头显原型(图4)。这家公司已经为相关的软件和参考设计申请了专利,并希望加速全息显示在AR头显和智能眼镜、汽车平视显示器和消费电子产品领域的大规模采用。

图4:VividQ的双目全息头显原型,头显上方是一个深度传感器。
如今,VividQ的全息头显原型会接入到一台PC,而后者运行的相关程序可以渲染来自Unity或Unreal等游戏引擎的虚拟内容。虚拟内容的颜色和深度信息会发送到CGH管道(图3)。当在环境中投射全息图时,所述设备同时会使用深度传感摄像头的信息来实现虚拟与真实和真实与虚拟的遮挡(图5)。FFT计算在GPU中进行。
图5:在不同距离捕获的三维全息投影。
尝试VividQ的全息头显是一次令人大开眼界的经历,因为当CGH只存在于科幻作品描述的的未来时,我的全息知识就随着我的大学毕业而终止。这一次访问令我意识到全息技术自80年代以来已经发展到什么程度,但还有更多的惊喜在等着我。
3. 移动端的实时CGH:是科幻还是现实?
将CGH从桌面端带到移动端似乎是一项艰巨的任务。如果在拥有强大CPU和GPU的桌面端实现CGH已经是一个巨大挑战,将全息图生成转移到移动设备还有意义吗?然而,如果我们仔细思考,如果我们希望看到实时全息显示器的广泛采用,转向移动端显然是下一个自然而然的步骤。
类似的过程已经在虚拟现实发生。如果你关注这个行业的发展,你应该会知道于2016年面世的Oculus Rift和HTC Vive。这种系留头显需要接入一台功能强大的PC,然后才能够以每秒帧数(FPS)的高分辨率为每只眼睛渲染虚拟场景。但我们在2018年看到了第一代VR一体机Oculus Go,并在后来见证了非常成功的Oculus Quest。一体机的形式意味着它包含了提供虚拟现实体验所需的一切组件,不再需要外接设备。这一形态的设备优势非常明显:不再需要线缆,设备可以随身携带,功耗更低。所有这一切都是通过移动SoC实现。将CGH移植到移动SoC可以为我们带来同样的好处,并把这项技术带到AR的真正未来。在这个未来里,一款形状紧凑的低功耗全息显示器将是必要事项。对于这一点,Arm的Total Compute(全面计算)策略将能发挥重要的作用。
4. Arm的全面计算和ViviQ将如何塑造全息术的未来?
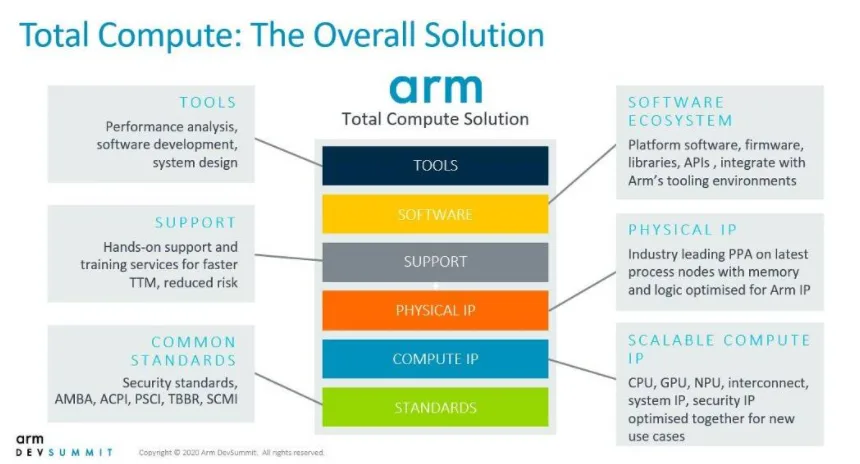
图6:未来的全面计算解决方案的不同要素
为了满足在计算能力和功耗方面不断增长的需求,Arm正在通过全面计算来实现战略转变:从优化单个IP到采用整个SoC设计的系统级解决方案视图(图6)。这意味着整个系统应该无缝协作,为低功耗SoC封装的计算密集型工作负载提供最大性能。这种新方法将分析如何在不同的IP块和计算域之间最好地部署互连的数据和计算。它不仅包括主要的计算域(CPU、GPU和NPU),而且会纳入软件框架和计算库来提高它们的性能。同时,诸如Performance Advisor这样的新工具可以识别瓶颈并帮助实现整个系统的最佳性能。
这种方法特别适用于高性能计算,如CGH的核心要素FFT。最新的Mali Premium GPU(Mali-G78和Mali-G77),以及主流的Mali-G57都利用了Arm Compute Library(ACL)。这是一个高度优化的底层函数集合,包括一个通过OpenCL加速的高效FFT计算实现。FFT在复杂域中运行,而我们可以使用FP32和FP16浮点精度。硬件后端性能的每一次改进都直接转化为每秒乘法累加运算(MAC/s)的增加,从而转化为FFT计算性能的提高。这一点尤其重要,因为即使考虑到预处理和后处理操作,FFT计算都占全息显示所需总计算量的60%-90%。
在2019光场和全息显示峰会(2019 Light Field and Holographic Display Summit),VividQ首席执行官达伦·米尔恩(Darran Milne)分享了在2048x1536显示器为指定数量目标层生成单帧全息图像的浮点运算要求要求(表1)。
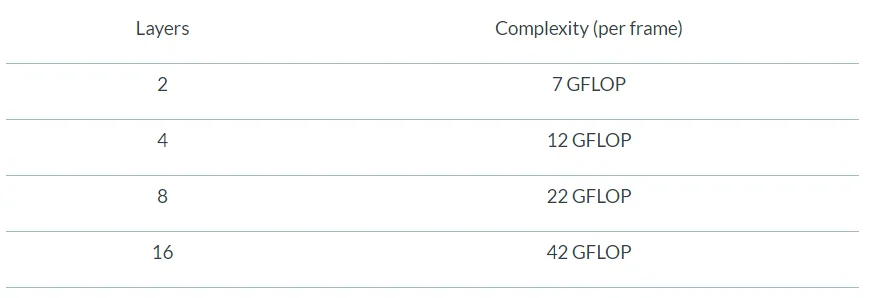
表1:使用ViviQ实时算法生成单个2048x1536帧的浮点运算要求。
即使是1280x720显示器,对于传统的基点计算而言,每帧的计算需求大约为7000 GFLOP。对于计算需求减少了1000倍,这说明了利用FFT和相关Arm库的ViVidQ方法更加高效。重要的是,VividQ的解决方案不仅优化了计算要求,而且提高了图像质量。VividQ SDK所提供的算法针对不同的显示类型、大小和位深、以及各种图像特性(如高对比度)进行了优化。由于用户或调用程序可以请求特定数量的输出层,所以对于给定的光学系统和输入场景,你只能使用所需的计算量。但值得注意的是,简单场景可能只包含几个位深的数据。这一巨大的灵活性允许运行VividQ软件的Arm-Mali GPU实时交付各种应用的全息图。
下面我们来详细谈谈Arm Mali-G76 GPU的计算能力。一个Mali-G76内核中包含3个执行引擎,各自具有8个线程,并且每个时钟周期(3x8x3=72个浮点/周期/核心)能够传送大约3个FP32指令(MUL+ADD)。这意味着三星Galaxy S10中以720 MHz运行的10核G76显卡将提供720x106x72x10浮点或大约518 GFLOP/s。对于FP16精度,这一数字将翻倍至1.04 TFLOP/s。这是理论上的最大值。在实践中,实际数字会受到带宽限制的影响,并最终受限于功耗。对于诸如FFT这样的高负载算法而言,我们依然有望获得理论最大值的相当一部分。即使我们只计算每线程每周期单个FLOP,利用率为60%,我们都可以达到100 GFLOP/s。
正如我们所见,原则上带宽不应该是个问题,但实际上它可能会成为一个问题。使用GPU时,如果不进入热节流和出现快速电池消耗,我们就不可能维持高分辨率和复杂用例所需的处理强度。但我们有一些简单的应用程序,例如增强现实设备中的文本和图标投影,我们可以限制层的数量,并依然能够为当今的AR显示提供显著的优势。根据Arm支持团队的评估,三星Galaxy S10的一个切片计算需要8ms,分辨率为720x1280。这意味着一个全彩色的单层需要24毫秒,而且系统理论上将以40帧/秒的速度运行。这是移动GPU实时运行CGH的首次演示。VividQ最近展示了他们的全息操作系统概念(图7)。所述操作系统具有图标、文本和社交媒体等我们熟悉的应用程序,而它们通常只需要2个深度层。

图7:VividQ的全息操作系统概念。
但全息显示远不止FFT计算。CPU在内容生成和其他计算任务中起着关键作用。为了避免瓶颈并实现全息图像的高分辨率,诸如显示器和激光驱动器等不同部分必须有效地协作。全面计算旨在作为Arm系统范围内设计方法的一部分以满足所述要求,并将帮助数字沉浸的下一波浪潮成为可能。同时,VividQ团队将继续相关的算法研究,从而实现比AR可穿戴设备更高质量的全息图与全息应用。VividQ的专有全息图模拟工具(由GPU运行)允许不同的光学设置以实现高精度模拟。这使得新光学系统的快速原型化不再需要硬件实验,并最终带来速度更快画质更优的全息图像(图8)。令人高兴的是,所需的算法变化不会显著影响计算量,所以这种新型显示器依然与Arm的全面计算架构兼容,并在移动处理器实现实时性能。
图8:目标图像(a);使用VividQ SDK 4.2.0和标准生成算法创建的全息图像(b);正在开发的高黑电平程序(c)。
5. 总结
计算机全息的最新发展使得全息显示从科幻变成了现实。全息术和全息显示与当今的三维显示相比具有很大的优势。从智能眼镜到汽车平视显示器和新的消费电子产品,随着计算方法的发展,全息显示可以成为AR商业应用的一个可行替代品。为了实现其真正的潜力,全息显示必须从基于桌面的计算转移到移动端SOC。Arm和VividQ的合作旨在帮助移动处理器实现CGH。在这里,我们可以结合VividQ在全息摄影方面的深厚软件专业知识,以及低功耗、高性能的Arm IP。VividQ SDK允许跨不同终端支持实时的高质量CGH,而用于沉浸式计算的全面计算方法致力于在性能和功耗方面实现整体系统改进,从而帮助未来的全息显示成为现实。










