Facebook最新麦克风声音分离可带来更优AR/VR语音交互创新

查看引用/信息源请点击:映维网
AR/VR语音交互创新
(映维网 2020年07月20日)Facebook人工智能团队日前介绍了一种由单个麦克风同时分离多达五种声音的方法。所述方法在多个语音源分离基准(包括具有挑战性的噪声和混响的基准测试)测试中优于以往的方法。利用WSJ0-2mix和WSJ0-3mix数据集,以及通过四个和五个共时扬声器的变体,模型在尺度不变信噪比(分离质量的常用度量)方面比当前最先进的模型提高了1.5 dB(分贝)以上。
相关论文:Voice separation with an unknown number of multiple speakers
为了建立所述的模型,团队使用了一种直接作用于原始音频波形的全新递归神经网络结构。以前最好的模型主要是利用遮罩和解码器来对每个说话人的声音进行分类。当扬声器数目较多或未知时,这类模型的性能会迅速下降。
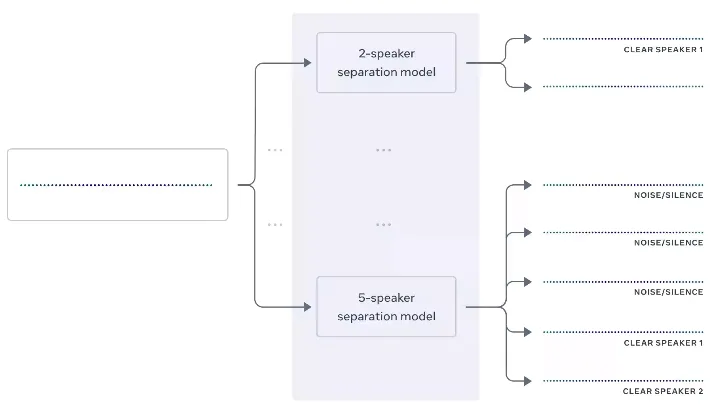
与标准语音分离系统一样,Facebook人工智能团队的模型要求事先知道说话人的总数。但为了应对未知说话人数量所带来的挑战,研究人员构建了一个新的系统来自动检测说话人数量,并选择最相关的模型。
◐ 1. 工作原理
语音分离模型的主要目标是,当给定一个输入混合语音信号时,估计输入源并为每个说话人生成一个单独信道输出。
所述模型使用了一个将输入信号映射到一个潜在表示的编码器网络。团队应用一个由多个区块组成的语音分离网络,其中输入为潜在表示,输出为每个说话人的估计信号。以前的方法通常在执行分离时使用遮罩,但当遮罩未定义,并且在处理过程中可能丢失一定的信号信息时,问题就会出现。
......(全文 1058 字,剩余 522 字)