研发实战三:用RenderDoc验证有效渲染方式,优化Quest应用

利用RenderDoc来优化你的Quest应用
(映维网 2020年01月03日)Oculus开发者关系团队的一个主要任务是帮助开发者优化游戏,令其能够有效地支持所有的Oculus硬件。所述团队中的开发者关系工程师克里斯蒂亚诺·费雷拉(Cristiano Ferreira)正在通过系列博文来介绍如何通过RenderDoc来优化你的Quest应用,包括如何轻松将其集成至你的工作流程,相关的基础知识,以及允许你在未来利用这项有用工具的技巧经验。对于第三篇博文,费雷拉探索了如何使以最有效的方式进行渲染,包括验证CPU和GPU渲染方法是否能够尽可能高效完成的关键使用情景,下面是映维网的具体整理:

◐ 1. 验证多通道 vs 实例立体渲染(instanced stereo rendering)
由于VR渲染的性质,确保绘制调用的最优化非常重要。在幕后,引擎分别渲染两只眼睛。每只眼睛都有自己的模型视图投影矩阵,而后者由透镜设置限定的IAD(轴间距离)所定义。大多数人都知道IPD(瞳孔间距离)设置会影响轴间距离,商用引擎通常会为你处理这个问题,但你需要确保设置正确。下面是具体的概述:
◐ 1.1 单通道
对于基础通道中的每个网格
绘制左眼(一次绘制调用)
绘制右眼(一次绘制调用)
◐ 1.2 多通道
对于基础通道中的每个网格
绘制左眼(一次绘制调用)
对于基础通道中的每个网格(再一次)
绘制右眼(一次绘制调用)
◐ 1.3 实例立体渲染/多视图
对于基础通道中的每个网格
绘制双眼(一次绘制调用)
如你所见,实例立体渲染/多视图是最佳选择,因为它将使基本通道中的总绘制调用次数减少一半。
◐ 2. 验证没有使用临时缓冲区
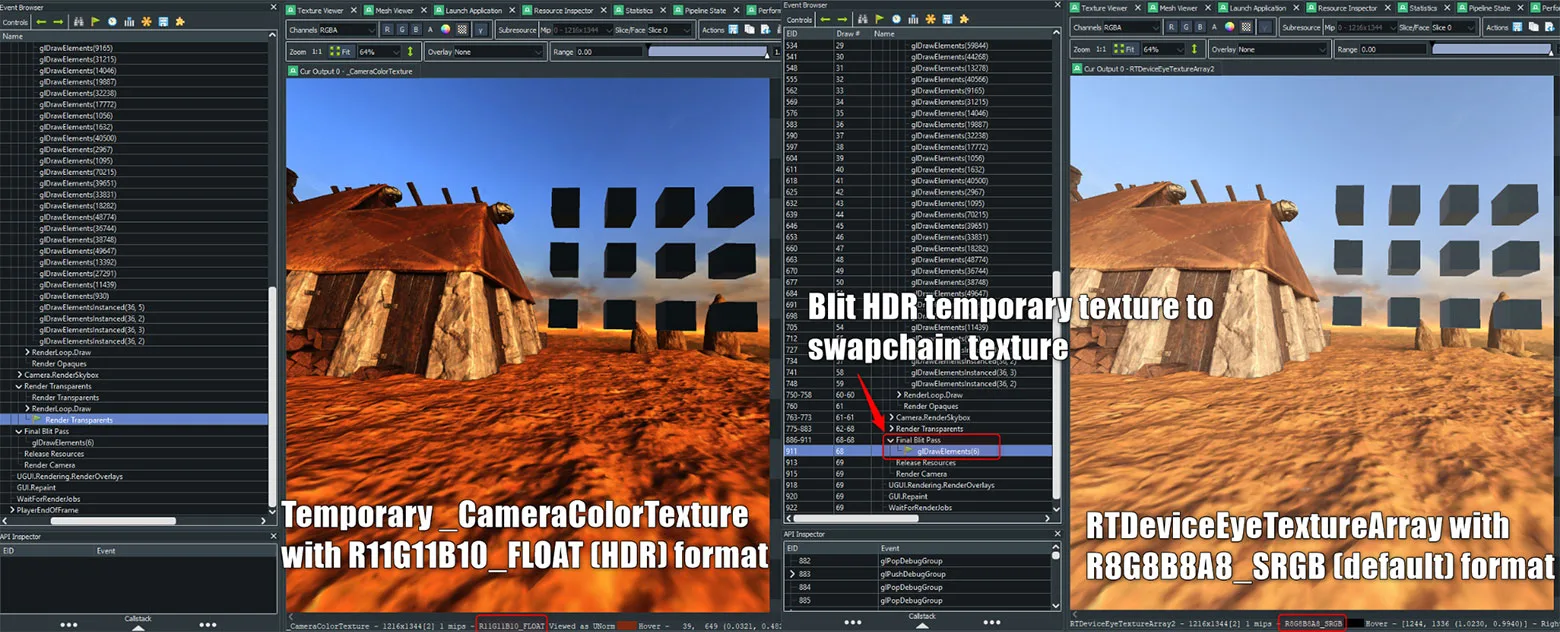
检查输出/渲染纹理,以确保资源名称标记为RTTextureArray而非TempBuffer,ColorBuffer或其他名称。要应用MSAA和/或节约固定注视点渲染量,你必须直接写入交换链纹理。这同时将确保你不会意外地解析中间渲染目标/临时缓冲区,从而节省1ms-1.5ms的固定GPU解析成本。
交换链纹理的正确名称如下显示:
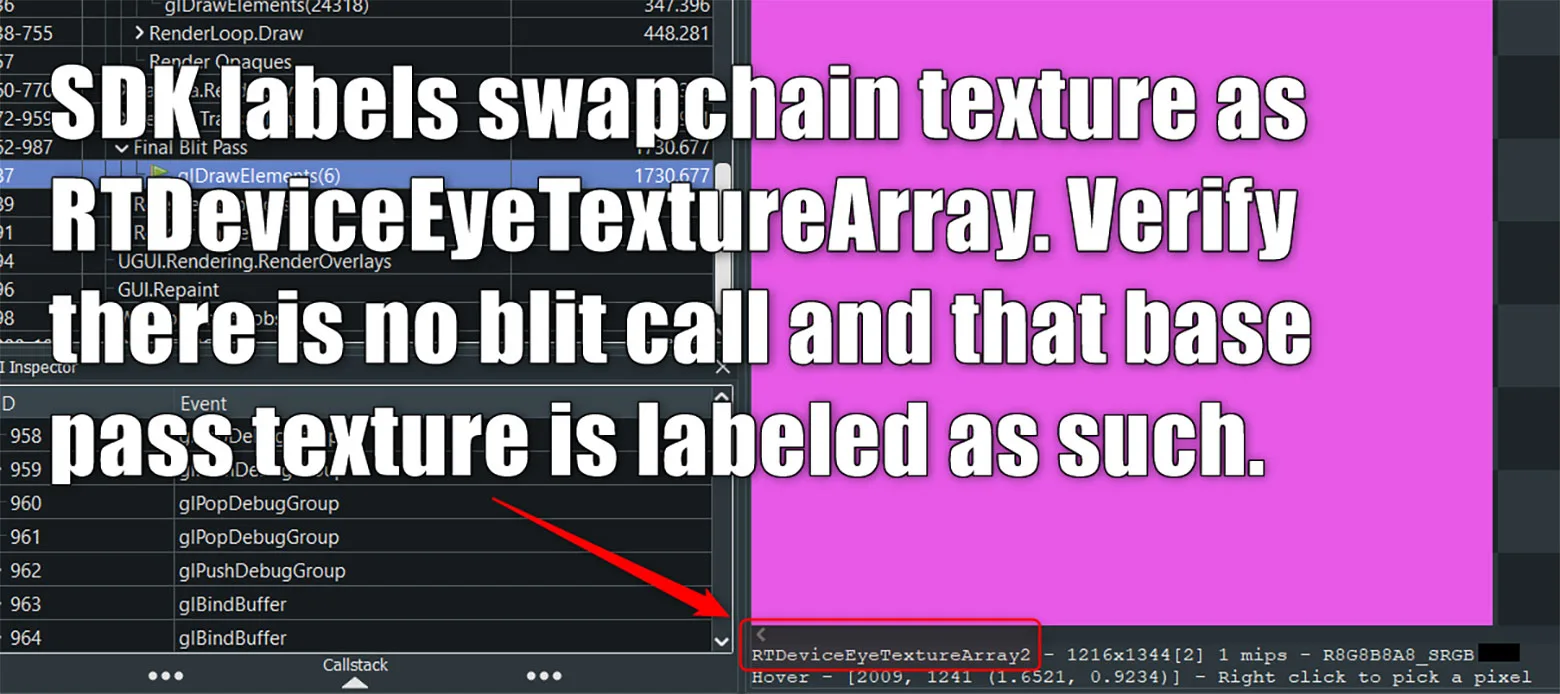
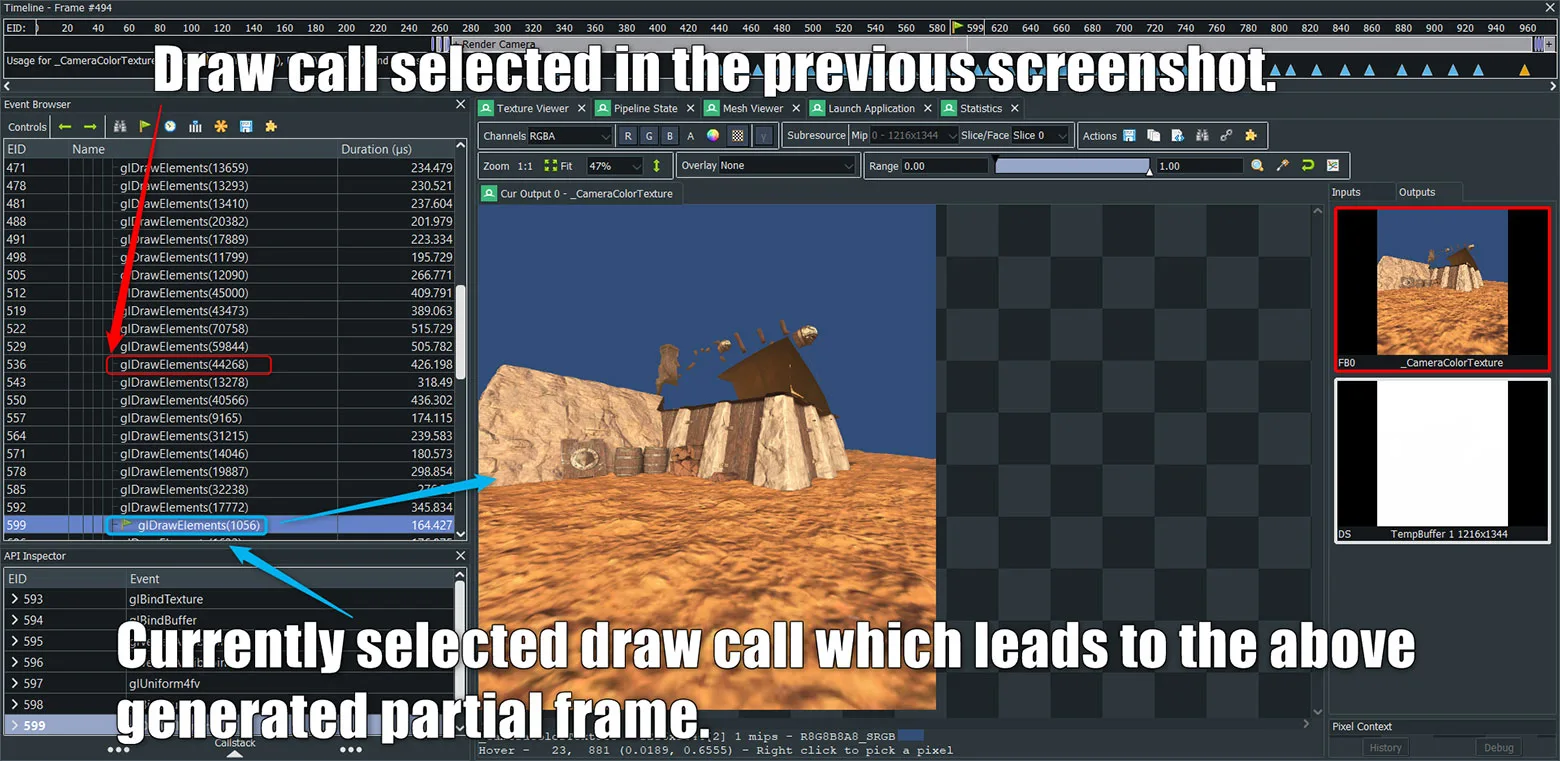
这是写入正确交换链纹理时的输出纹理名称。在这个示例中,你会看到选定的绘制调用位于名为“Final Blit Pass”的注释之下。这意味着你要使用先前生成的渲染目标并将其用作临时缓冲区,然后再把它复制到交换链纹理。GPU需要付出昂贵的解析成本,而仅将其映射到交换链纹理又要付出每像素成本。
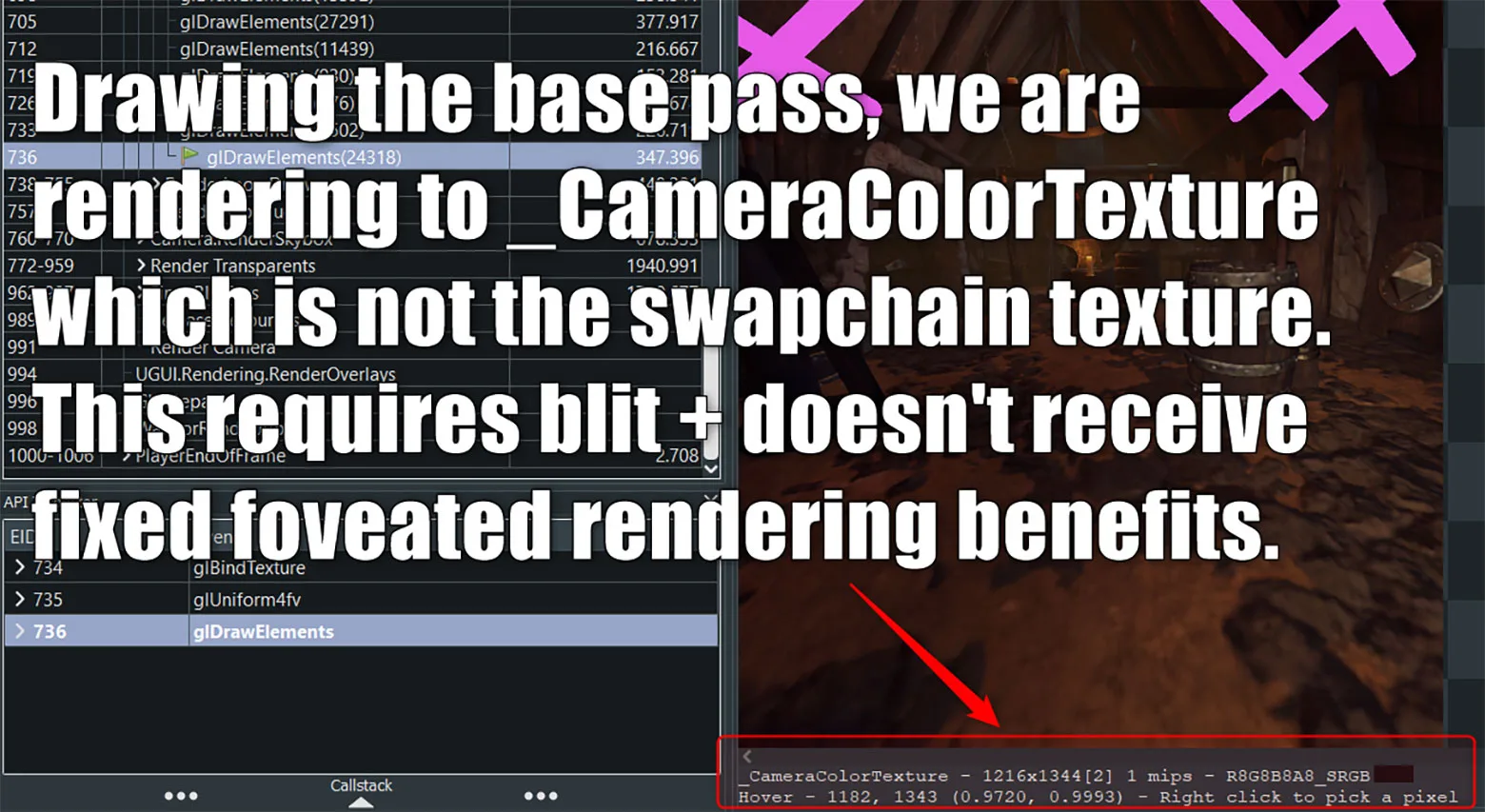
我在前面显示的同一捕获帧中高亮了基础通道绘制调用。相应输出渲染目标显示的标签为“_CameraColorTexture”。这意味着引擎生成了一个中间渲染纹理并在后面用作blit/copy的输入资源,这意味着解析成本,没有固定注视点渲染像素着色器节省量和MSAA质量提升。这里说明的是,你需要始终关注渲染目标,确保仅在单通道中直接渲染到交换链纹理。
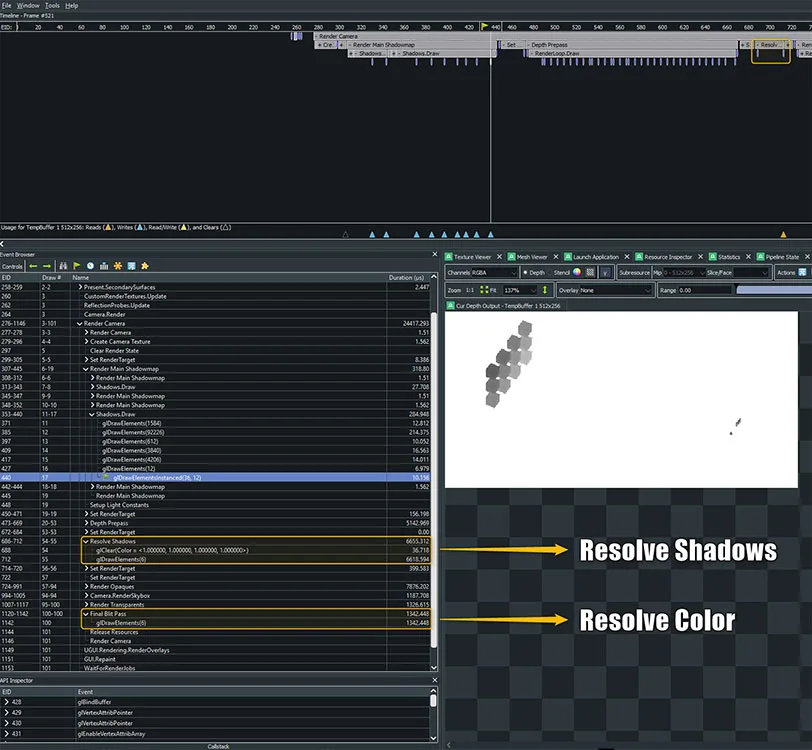
在上面的屏幕截图中,你可以看到Unity中的调试标记通过Resolve Shadows标记显式注释了解析阴影贴图的过程。你同时可以看到Final Blit Pass批注,意味着将临时颜色缓冲区复制到交换链纹理。
◐ 3. 验证阴影投射器/接收器/级联级别和阴影贴图分辨率(如若使用)
所有投射和/或接收阴影的网格都将需要从光源方向写入深度缓冲区方向的额外绘制调用。尽管没有针对这种绘制运行的片段着色器(这意味着它们的GPU开销要低于典型的着色绘制),但CPU(绘制调用数增加)和GPU(顶点着色器投影所有网格几何体+深度阴影贴图解析)的开销依然会产生。
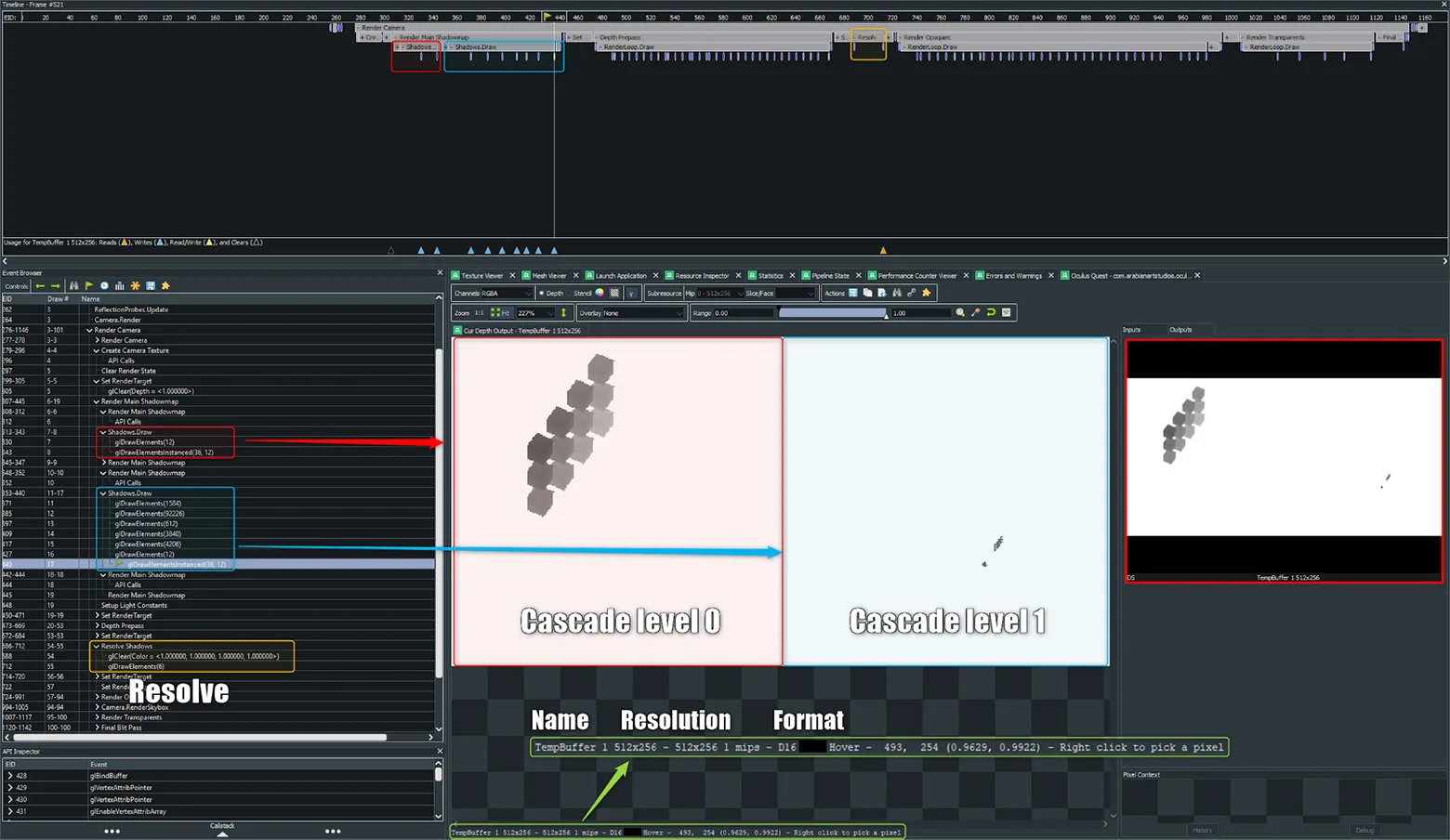
上面是RenderDoc中的阴影贴图。你会发现阴影通道中有一个用于稍后采样场景阴影的临时深度缓冲区。重要的是要验证总体阴影贴图分辨率,以及与每个级联相关的绘制调用次数。在几乎所有的情况下,随着camera距离的增加和每增加一个级联,较接近的级联将具有较少的绘图调用。请注意橙色的解析阴影一栏。当你将临时缓冲区存储在外部存储中时,这是固定成本。如果必须使用阴影,请确保将分辨率和其他绘制调用保持在尽可能低的水平。
◐ 4. 验证共享网格的GPU实例化
GPU实例化是图形API/驱动程序级别的功能,可允许你调度单个绘制调用来渲染多个网格。这里需要遵守一定的规则,包括共享完全相同的管道状态和网格输入。如果一个网格每帧使用了多次(子弹,装饰,粒子和树叶等),则可以通过实例化网格来大幅减少绘制调用。请注意,这不会降低GPU的成本,因为你依然必须投影每个网格。
每当你调度一个实例化绘制,每个网都会收到可以在着色器中使用的实例ID。这样,你就可以将每个网格实例的实例ID与属性信息(如纹理索引,颜色或其他)相关联。我一直十分喜欢举的一个例子是,在赛车游戏中渲染大量人群。你可以通过实例化并使用不同颜色的衬衫来绘制每个人,从而确保一种观众满满的感觉,同时不必为每个网格分别调度单独的绘制调用而产生过多的CPU开销。在这个基本示例中,你将不会使用蒙皮网格……但你可以在GPU进行蒙皮/动画操作来实例化蒙皮网格。这是一种更先进的技术,但同样有着优点和缺点。这里的想法是,你会实例绘制共享的T形网格,然后使用实例ID查找并计算时间戳和姿态信息。这样可以完成混合形状查找,并在顶点着色器中进行蒙皮。或者,你可以提前在计算着色器中批量处理所有混合形状和蒙皮操作,然后使用实例ID查找当前绘制的网格的相关数据的位置。
旁注:GPU实例化是实例立体/多视图渲染的工作方式。使用所述方法的每个绘制调用为每个网格调度两个实例。两个网格映射中的每一个实例ID均绘制到相关的眼睛缓冲区,而顶点着色器将用来索引到模型视图投影矩阵的一个阵列,从而正确地将网格投影到相关的眼睛位置。
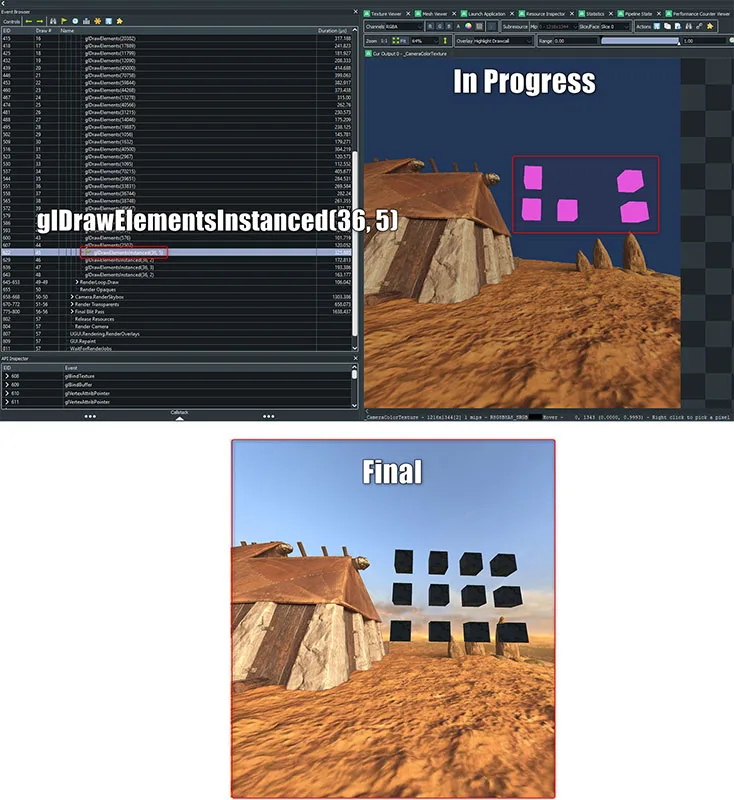
在上图中,你看到的不是十二个单独的glDrawElements(36)调用,而是4x glDrawInstanced。glDrawElementsInstanced(36,5)不能一次绘制所有多维数据集的原因是,某些多维数据集违反了Unity中的批处理规则。要判断未对它们进行批处理的原因,你可以通过Unity中的Frame Debugger工具来确定是否调用了glDrawElementsInstanced(36,12),从而将多维数据集的总绘制计数缩减为一个绘制调用。
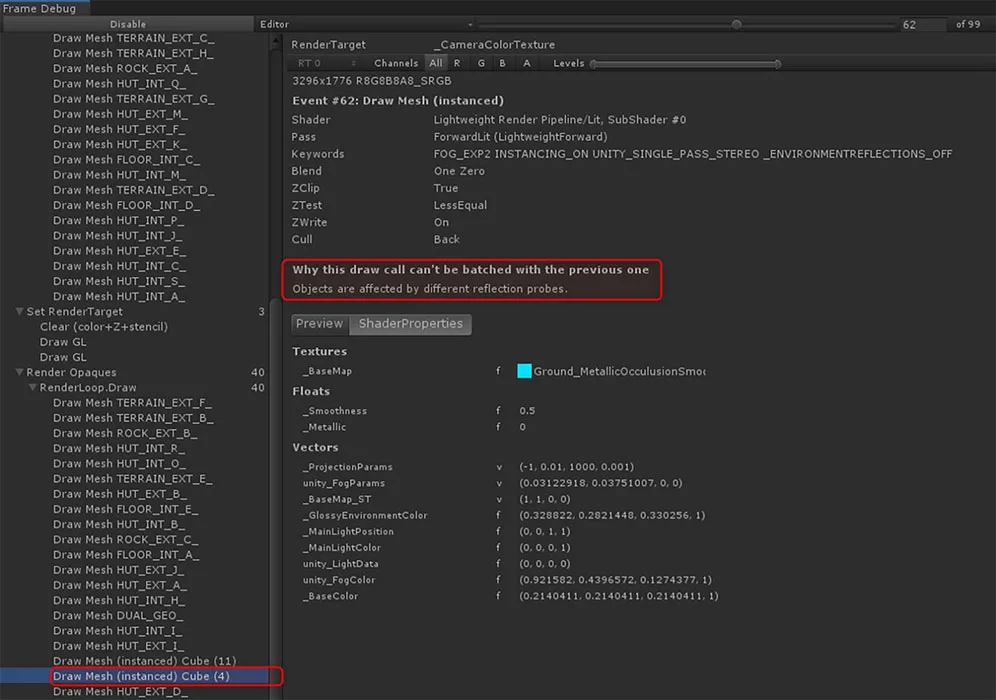
在上面的Frame Debugger视图中,我选择了第二个实例绘制调用。Unity在“Why this draw call can’t be batched with the previous one”一栏中表示,多维数据集受不同的反射探针所影响。如果它们全部在一次绘制调用中完成,我将需要对所有多维数据集使用单个反射探针。Frame Debugger免除了方程式中的猜测,而你同时可以通过RenderDoc的“Pipeline State”选项卡中使用传统的侦探方法来得出这个结论。只需检查并比较两个实例绘制调用之间的输入资源即可。
◐ 5. 渲染队列和z-sorting验证
对于大多数GPU,有一种优化方法可允许硬件拒绝遮挡的不透明像素(从前到后绘制)。例如在VR中,在大多数情况下如果手不透明,则应首先渲染它们。如果在绘制手(可能是接近于camera的对象之一)时写入深度缓冲区,并调度z-test以拒绝其后的像素,则硬件将足够智能并选择不为位于手后面的投影几何像素执行像素着色器。如果你使用了合理的几何图形计数,并且顶点着色器中没有执行任何花哨的操作,则像素着色器通常是渲染管道中开销最多的一环。
需要注意的重要一点是,由于Rift S和Quest采用了高分辨率面板,并且你必须为双眼绘制,所以这里节省量的价值二将会翻倍。在特定情况下,使用成本昂贵的像素着色器来为植物提供一个Depth Prepass物有所值,亦即为Alpha!= 0像素设置深度缓冲区,然后再执行一次彩色通道,将深度测试设置为相等。使用这两种方法进行实验将帮助你得到正确的结果。
下面是一个示例:

上图是一个问题场景中的最终渲染目标。一切看起来都不错,对吧?也许建筑物内部存在对象渲染,它们不仅使用了不必要的绘制调用并在CPU端施压管道状态,并且正通过投影所有内部对象的几何形状及遮盖所有不必要的投影来占用GPU资源。请看看下面的屏幕抓图,它说明了这种低效情况:
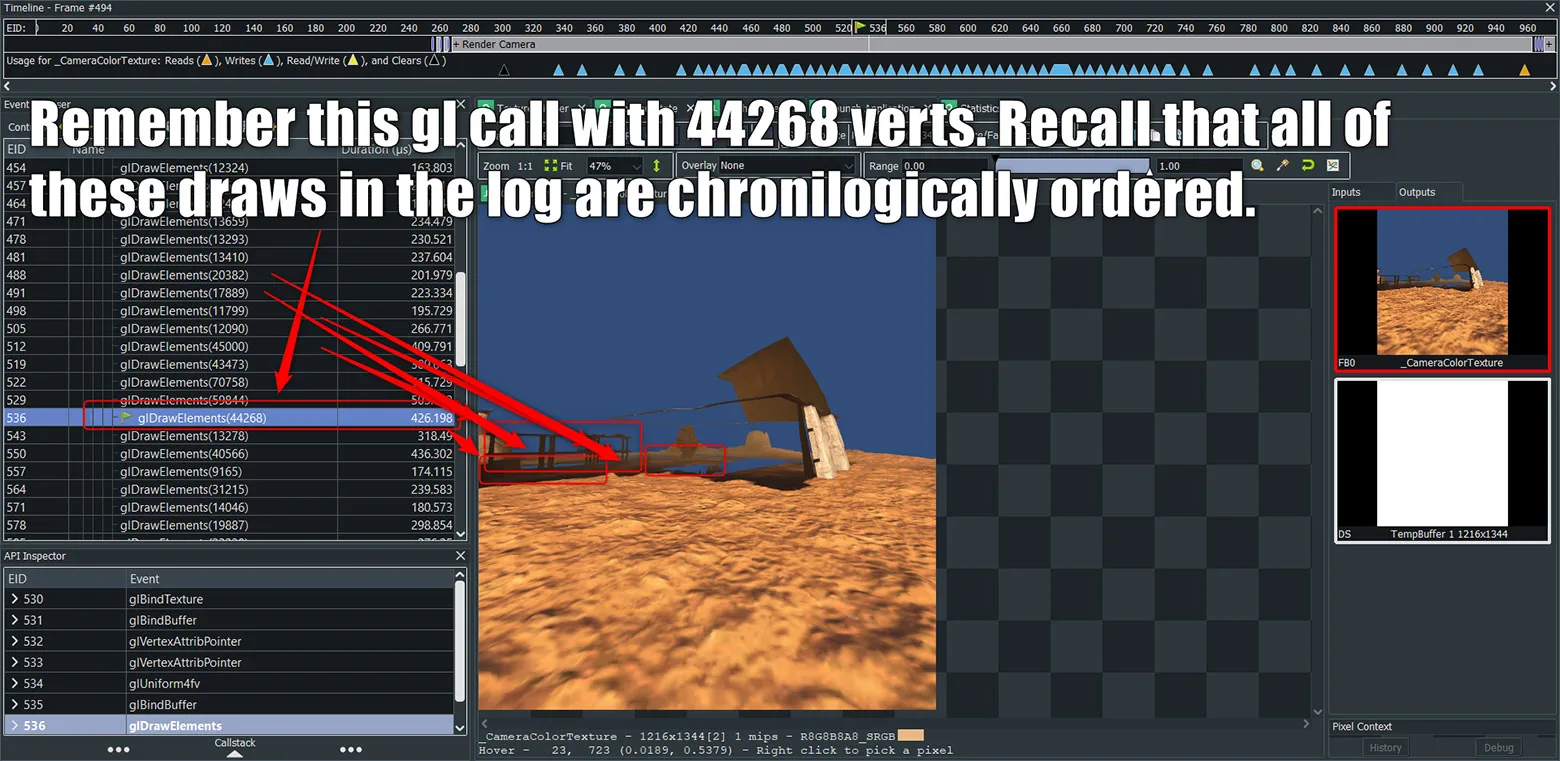
带注释的绘制只是分配给GPU的所有不必要绘制调用的一小部分。它们无缘无故地对所有几何图形进行处理和着色。如果CPU采取预防措施来遮挡剔除它们,则GPU将不必担心它们。我们会在后面介绍更多关于遮挡提出的细节。
对于这种情况,一个合适的比例是:你聘请了一位油漆工,然后他以每小时的速度来油刷房屋。如果你决定先将所有框梁都涂成棕色,然后用纯色涂漆整栋房屋。这时候,如果你已经告诉他们要用一种颜色涂漆房屋,但工人却把框梁都涂成红色,而且你依然要为其付费,相信你会感到非常不解和沮丧。这可是成本。在游戏和图形世界中,GPU正在处理你本可以花费在其他地方的开销,如使用更详尽的着色器/材质。为了进行比较,请参阅下图。这里显示的是同一帧,但选择了在调度顺序中更后的绘制调用。
如前所述,当你在RenderDoc的API日志中选择绘制调用时,帧会按时间顺序在你眼前构建。在早前的截图中,当我在数个调用之后选择了这个绘制时,你会看到一堆墙壁模型遮挡了先前绘制的所有内容。这意味着你先前调度的所有绘制调用均执行了其像素着色器并被覆盖。如果你在那些对象之前绘制了环境墙壁和天花板,则应该将深度缓冲区设置为墙壁网格的深度,从而节省每个像素片段着色器的过度绘制成本,因为硬件可以判断较近的像素正在遮挡它。如果你的游戏负担不起遮挡剔除,你依然可以通过为游戏量身定制优化的排序算法来节省GPU时间。Unity和Unreal均允许覆盖渲染队列中的特定图形和材质。
◐ 6. 纹理格式和分辨率验证
利用RenderDoc,你可以验证输入和输出的纹理分辨率是否太高,是否提供了mipmap,压缩格式是否符合你的期望,每次绘制采样的纹理数量等等。你在引擎编辑器中很难跟踪所有纹理的纹理信息,所以这是一个节省内存并保持效率的优秀验证方法。
为了感受具体的差异,下面我们来看看一个输入纹理:
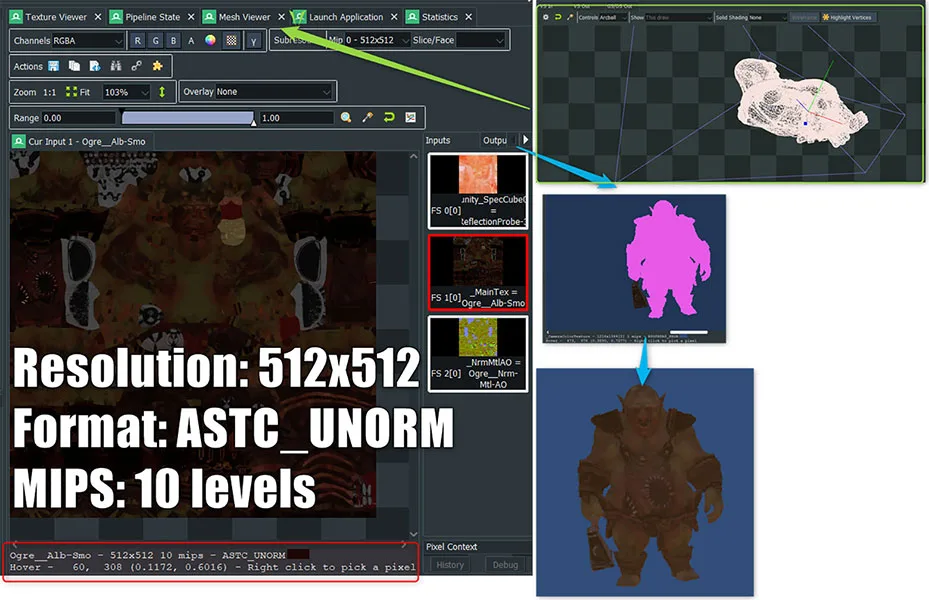
例如,当我在“Input”选项卡中选择了这个Ogre绘制调用,然后选择albedo输入纹理时,我可以看到每个输入纹理的分辨率,压缩格式和mip级别数量。我可以看到ASTC texture compression格式用于我的输入纹理。这是获得最佳质量和大小的推荐格式。
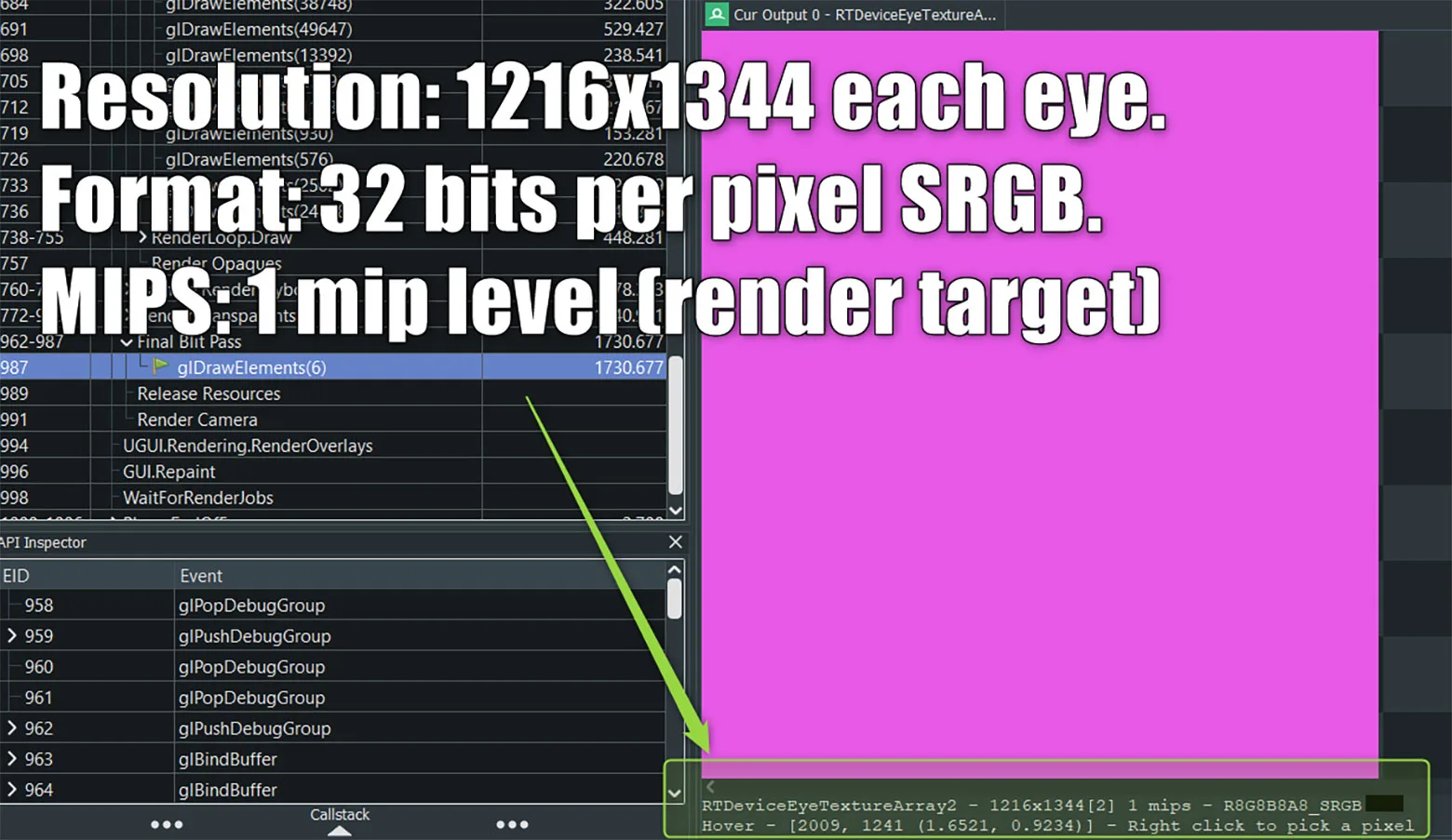
大多数情况下,高动态范围(HDR)纹理格式对Oculus Quest而言都不可行。HDR需要一个临时缓冲区,其格式与交换链纹理的格式不同,其通常是R11G11B10_FLOAT,而不是普通的R8G8B8A8_SRGB。问题不是bits per-pixel,而是当每帧准备就绪时将临时缓冲区从HDR复制和转换为标准格式的blit成本。由于需要更高的浮点精度,所以HDR效果和计算的成本通常要会昂贵得多。同样,任何时候使用临时缓冲区都不会获得固定注视点渲染或MSAA的好处,所以你可能会遭受额外的性能和/或质量损失。要确定渲染目标是否符合HDR规范,你可以确保自己正在写入采用R8G8B8A8_SRGB格式的RTDeviceEyeTextureArray交换链纹理来,如下面的比较图所示:
◐ 7. 总结
本文介绍了从Oculus Quest中实现最优性能的重要案例。请留意下一篇RenderDoc博文,我将介绍更多的使用场景及如何利用这个强大工具的建议。
延伸阅读:研发实战:如何通过RenderDoc优化Quest应用
延伸阅读:研发实战:用RenderDoc+固定注视点等渲染技术优化Quest应用