Facebook公布最新AI成果:如何理解真实世界3D对象

开发对真实世界有着进一步理解的系统
(映维网 2019年11月01日)为了解释周围的世界,AI系统必须理解三维视觉场景。这种需求不仅只局限于机器人技术,同时包括导航,甚至是增强现实应用。即便是2D照片与视频,所描绘的场景和对象本身都属于三维。真正智能的内容理解系统必须能够视频中识别出杯子旋转时的把手几何形状,或者识别出对象是位于照片的前景还是背景。
日前,Facebook公布了多项能够推进3D图像理解的AI研究项目。虽然不尽相同,但互为补充。正在国际计算机视觉大会(International Conference on Computer Vision)进行演示的项目涉及一系列的用例和情形,包含不同种类的训练数据和输入。
- Mesh R-CNN是一种新颖的,先进的解决方案,可以通过各种现实世界2D图像预计最精确的3D形状。这个方法利用了Facebook的Mask R-CNN框架进行对象实例分割,其甚至可以检测诸如凳脚或重叠家具等复杂对象。
- Facebook指出,通过利用Mesh R-CNN的替代和补充方法C3DPO,他们是第一个通过解释3D几何形状而在三个基准上成功实现非刚性形状的大规模3D重建,对象类别涉及14种以上。需要注意的是,团队仅使用2D关键点来实现这一目标,零3D注释。
- Facebook提出了一种新颖的方法来学习图像与3D形状之间的关联,同时大大减少了对含注释训练示例的需求。这使得团队更接近于开发出能够为更多种类对象创建3D表示的自我监督系统。
- Facebook团队同时开发了一种称为VoteNet的新颖技术,其可以利用LIDAR或其他传感器的3D输入执行对象检测。尽管大多数传统系统都依靠2D图像信号,但这个系统完全基于3D点云。与以前的研究相比,它可以实现更高的精度。
这项研究的基础包括:利用深度学习来预测和定位图像中对象的最新进步,以及用于3D形状理解的全新工具和架构(如体素,点云和网格)。计算机视觉领域已经扩展到各种各样的任务,但3D理解将在支持AI系统进一步理解现实世界和执行相关任务方面发挥核心作用。
◐ 1. 以高精度预测非约束遮挡对象的3D形状
诸如Mask R-CNN这样的感知系统是理解图像的强大通用工具。但由于它们是根据2D数据进行预测,所以其忽略了世界的3D结构。利用2D感知技术的进步,Facebook设计了一种3D对象重建模型,可以根据非约束的真实世界图像预测3D对象形状,包含具有一系列光学挑战的图像(如具有遮挡,杂波和各种拓扑的对象)。将第三维带到对象检测系统,同时实现对复杂情况的稳定增加工作,这要求更为强大的工程能力,而当下的工程架构阻碍了所述领域的发展。
https://v.qq.com/x/page/s3015iafu44.html
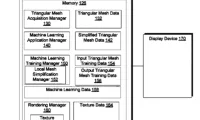
Mesh R-CNN根据输入图像预测里面的对象实例,并推断其3D形状。为了捕获几何形状和拓扑的多样性,它首先预测粗略体素,将其精化并进行精确的网格预测。
为了应对挑战,Faceboook团队通过网格预测分支增强了Mask R-CNN的2D对象分割系统,并构建了Torch3d(Pytorch库,其中包含高度优化的3D运算符)以实现所述系统。Mesh R-CNN利用Mask R-CNN来检测和分类图像中的各种对象。然后,它使用新颖的网格预测器来推断3D形状(所述预测器由体素预测和网格细化的混合方法组成)。在预测精细3D结构方面,这个两步过程实现了比以前更高的精度。通过支持复杂操作的高效,灵活和模块化实现,Torch3d能够帮助实现这一点。
他们利用Detectron2来实现最终的系统,其使用RGB图像作为输入并同时检测物体和预测3D形状。与Mask R-CNN使用监督学习来实现强大的2D感知类似,Facebook的新颖方法使用完全监督学习(成对的图像和网格)来学习3D预测。为了进行训练,团队使用了由10000对图像和网格组成的Pix3D数据集,而这比通常包含数十万个图像与对象注释的2D基准要小得多。
......(全文 3945 字,剩余 2706 字)