ARM发布Cortex-A77 CPU、Mali-G77 GPU,大幅提升AR性能

查看引用和消息源请点击:映维网
Cortex-A77 CPU和Mali-G77 GPU
(映维网 2019年05月27日)ARM今天在台北电脑展正式发布了全新的旗舰产品:Cortex-A77 CPU和Mali-G77 GPU,以及更节能,功能更强大的机器学习处理器。
◐ 1. Mali-G77
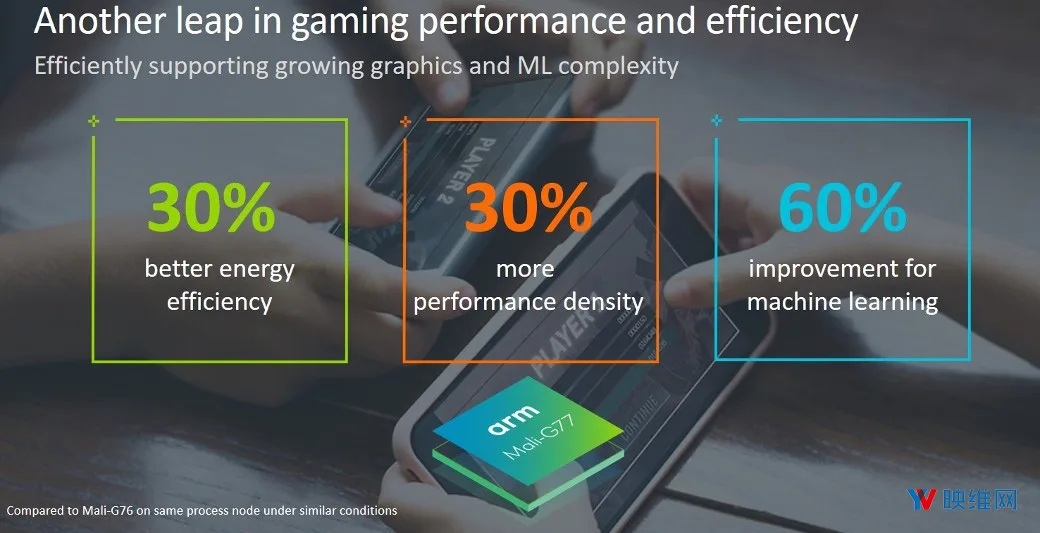
Mali-G77基于全新的 Valhall 架构。与Mali-G76相比,Mali-G77的性能密度提升了30%,能效增加了30%,机器学习性能则达到60% 。对于Mali-G77的性能提升,ARM特别提到了针对移动设备的增强现实性能。
ARM指出:“越来越多的消费者正在寻找全新的移动设备体验,尤其是AR。AR正越来越多地被用于移动设备,允许用户改变周遭的环境,以及物理世界和虚拟世界之间的交互。Mali-G77的高端图形支持可以增强移动设备实现AR功能的能力,并将改变移动游戏和其他移动用户体验。”
值得一提的是,Mail-G77 GPU同时可与全新的Mali-D77显示处理器协同工作。
◐ 1.1 Valhall
Valhall架构是Mali-G77和未来Mali GPU的基础。Valhall具备以下的新颖功能:
- 一种新的超标量引擎,可实现能效和性能密度的又一次飞跃
- 带有新指令集的简化标量ISA,更易于编译
- 新的动态调度指令
- 重写的数据结构可更好地与现代API保持一致,如Vulkan。
尽管新架构存在众多不同的进步和新功能,但两个关键是执行引擎和纹理映射器。
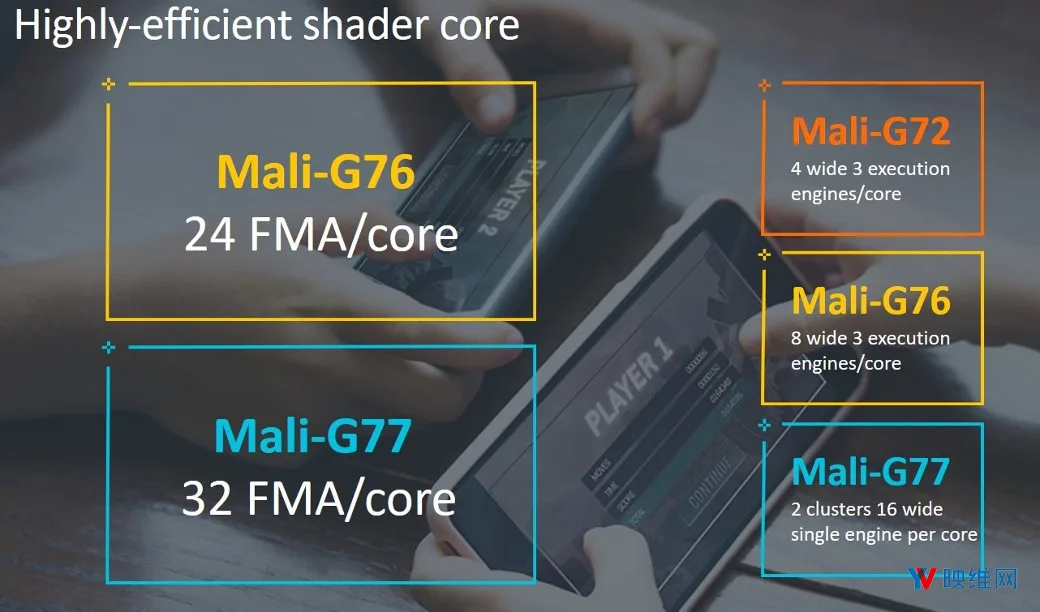
Mali-G77的执行引擎通过共享对更多通道的控制来提高性能密度。Mali-G76的执行单元线程数为8条,每个着色器核心共有24个FMA通道。但Mali-G77已增加至16条执行单元线程数,32个通道,以及每个着色器核心一个引擎。与Mali-G76相比,这意味着同一区域的计算量增加了33%。

Mali-G77的游戏性能提升与四重纹理映射器有关,后者提供了四个纹素/周期。这比Mali-G76高2倍,比Mali-G72高4倍。四重纹理映射器为高保真与休闲游戏带来了全面的优化。另外,由于ARM增加了Mali-G77的计算能力,这使Mali-G77能够提供比以往更高的每平方毫米性能。
为了匹配全新的16执行单元线程数的执行引擎,以及四重纹理映射器,Mali-G77已经经过了全面的优化,这包括重新设计LSC和属性管道(重点关注性能密度和能效)。
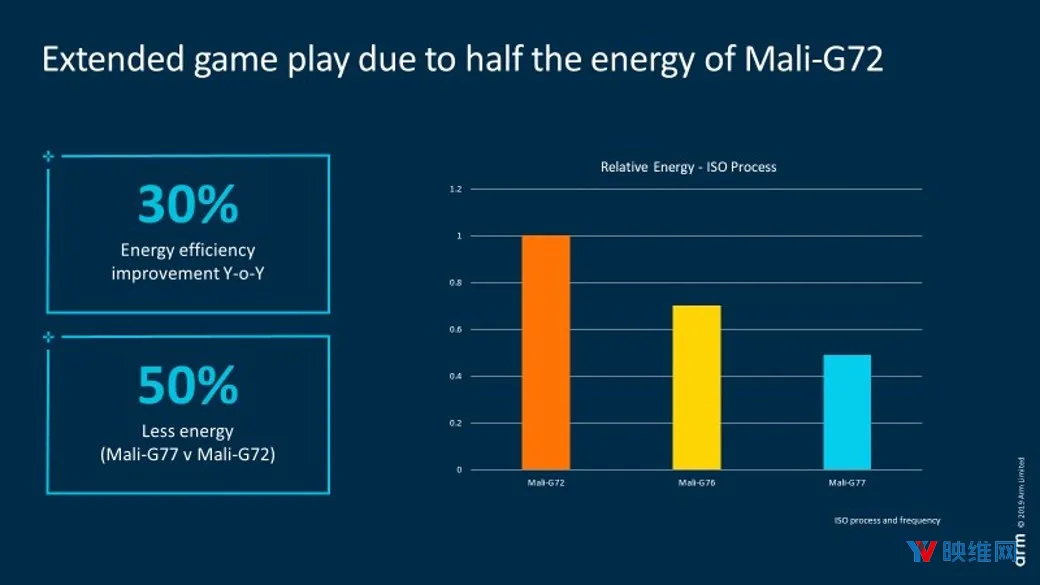
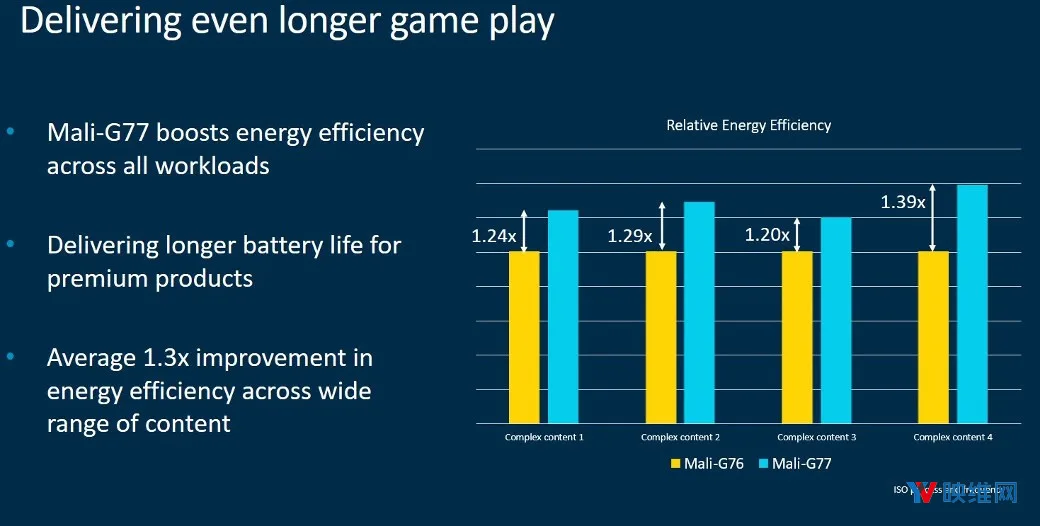
ARM指出,借助新架构,Mali-G77只需Mali-G72性能的50%即可完成相同的工作。Valhall架构和Mali-G77提高了所有工作负载的能效,使各种内容的性能提高了1.3倍。这为优质产品提供了更长的续航能力,尤其是增强现实。
◐ 2. Cortex-A77
Cortex-A77尽管只能算是A76的小改版,但IPC性能提升了20%。A77依然采用7nm工艺生产,与上代一样是3GHz峰值频率,这意味着20%的性能提升可以完全归功于架构的变化。
另外,Cortex-A77的机器学习性能已较两年前提升了35倍。
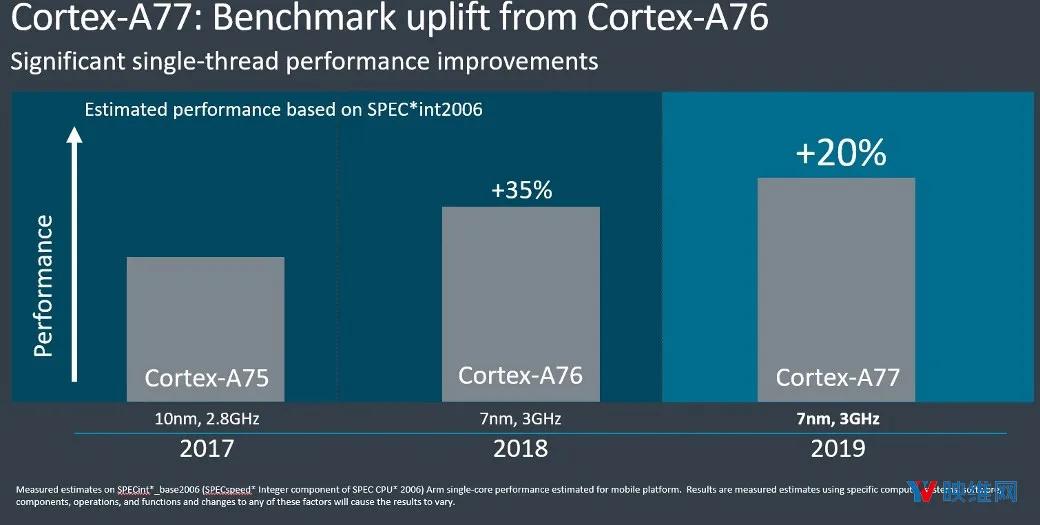
ARM指出,提高的性能意味着Cortex-A77非常适合高级用例和高级体验,如AR和ML。Cortex-A77的高性能可帮助设备实现更高的计算能力。这家公司解释说,移动设备上的ML用例和AR用例正变得越来越复杂,所以拥有能够支持这种不断增长的计算需求的CPU至关重要。
他们表示:“更高的性能同时意味着设备对基于AR的新应用和虚拟体验的响应能力更强。这包括越来越多地通过AR技术来增强用户整体游戏体验的移动游戏应用。
另外,Cortex-A77将支持5G兼容设备。
◐ 3. 机器学习处理器
ARM同时发布了基于全新架构的机器学习处理器。他们指出,新处理器的优化设计可支持新功能,增强用户体验,并为包括移动,虚拟现实和增强现实等各种细分市场提供创新应用。与CPU,GPU和DSP相比,它可以通过高效的卷积,稀疏度和压缩性能提供巨大的效率提升。
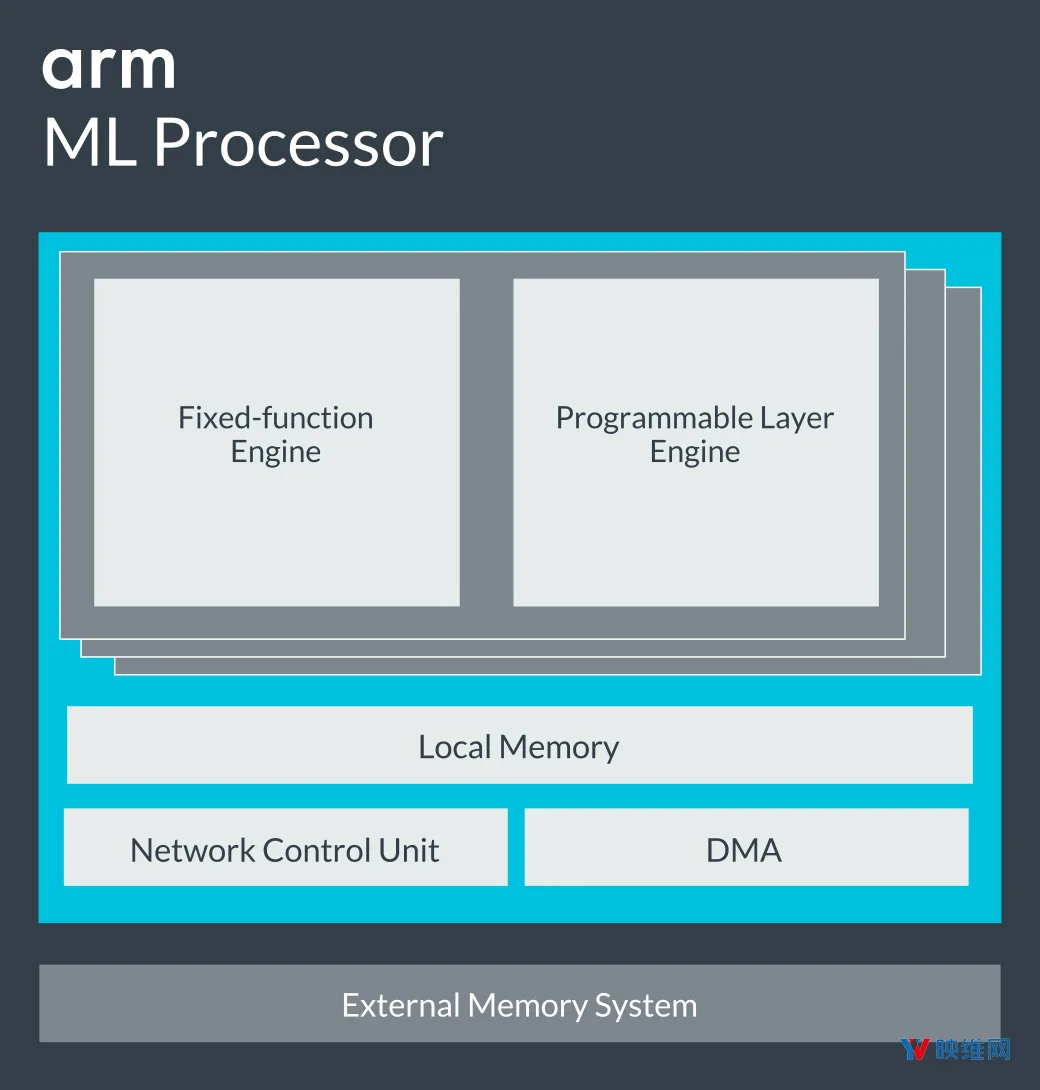
全新机器学习处理器的关键功能包括:
- 4 TOP/s,效率5 TOP/W,可为移动设备提供出色的性能,
- 可编程层引擎。
- 采用各种压缩技术,能够最大限度地减少系统内存带宽。
- 高度优化先进的几何实现。
- 支持安全操作模式以保护DNN IP和数据。
- 高响应性可减少延迟,从而改善用户体验。
- 支持TrustZone系统安全性。
另外,ARM指出全新的机器学习处理器可带来以下增益:
- 在边缘启用ML处理,节省功耗,减少数据消耗并增强用户隐私。
- 灵活的设计支持各种流行的神经网络,包括CNN和RNN。
- 与其他NPU相比,Winograd将普通滤波器的速度提高了225%,从而能够在更小的面积实现更高的性能。
- 通过各种压缩技术将系统内存带宽最小化1.5倍-3倍。
- 通过ACE-Lite主端口和可选的SMMU集成实现紧密的系统集成,并且可以轻松支持多个用户。
- 与ARM NN兼容,后者是CPU,GPU和NPU的推理引擎,它弥合了现有NN框架与底层IP之间的差距。







