谷歌如何通过机器学习实现逼真AR实时自拍效果

文章相关引用及参考:映维网
谷歌分享了他们是如何通过机器学习来实现逼真的AR实时自拍效果
(映维网 2019年03月09日)增强现实可以在物理世界之上叠加数字内容与信息,从而增强你的感知。例如,谷歌地图的AR功能可允许你直接看到叠加在现实世界视图的方向。借助Playground,你就可以通过AR并以不同方式浏览世界。对于最新版本的YouTube Stories,以及ARCore全新的Augmented Faces API,你可以为自拍添加动画面具,眼镜,3D帽子等滤镜。
实现这种AR功能的关键挑战之一是合理地将虚拟内容锚定在现实世界。这个过程需要一套独特的感知技术,需要能够追踪千差万别的表面几何,每一个微笑,每一次皱眉都要准确识别。

为了实现这一切,谷歌采用机器学习来推断近似的3D表面几何形状,只利用一个摄像头输入而无需专用的深度传感器。利用面向移动CPU界面的TensorFlow Lite或可用的全新移动GPU功能,这种方法带来了实时速度的AR效果。所述解决方案与驱动YouTube Stories全新创作者效果的技术相同,并已经通过最新的ARCore SDK和ML Kit Face Contour Detection API向广泛的开发者社区开放。
1. 用于AR自拍的机器学习管道
谷歌的机器学习管道由两个协同工作的实时深度神经网络模型组成:一个在整张图像上运行,并计算面部位置的探测器;在所述位置上运行,并通过回归预测来近似表面几何的通用3D网格模型。精确地裁剪面部可以大大减少对相同数据增强的需求,比方说由旋转,平移和比例变化组成的仿射变换。通过精确地裁剪面部,这允许系统将大部分性能用于预测坐标,而这对于实现虚拟内容的正确锚定至关重要。
一旦裁剪了感兴趣位置,网格网络一次仅应用于单个帧,利用加窗平滑(windowed smoothing)以减少面部静止时的噪点,同时避免在显著移动期间出现延迟。

对于3D网格,谷歌采用了传递学习,并训练了一个具有多个目标的网络:网络同时利用合成渲染数据预测3D网格坐标,以及利用注释的真实世界数据来预测2D语义轮廓。因而产生的网络为谷歌提供了合理的3D网格预测,这不仅体现在合成上,同时体现在现实世界数据上。所有模型都接受来自地理不同的数据集数据培训,随后在平衡的,多样化的测试集上进行测试,从而获得定性和定量性能。
3D网格网络接收裁剪的视频帧作为输入。它不依赖于额外的深度输入,因此同时可以应用于预先录制的视频。所述模型输出3D点的位置,以及输出在输入中存在并合理对齐的可能面部。一种常见的替代方法是预测每个地标的2D热图,但这不适合深度预测,而且如此多的数据点需要高昂的计算成本。
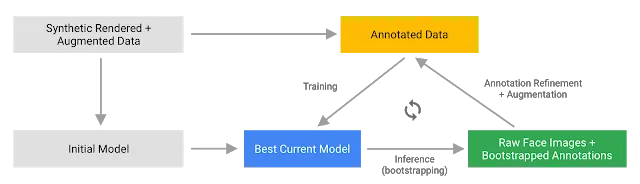
通过迭代引导和细化预测,谷歌进一步提高了模型的准确性和鲁棒性,并允许他们就将数据集扩展至越来越具有挑战性的案例,如鬼脸,斜角和遮挡。数据集增强技术同时扩大了可用的ground truth数据,开发出对摄像头缺陷或极端光照条件等问题的模型稳定性。
2. 专为硬件打造的界面
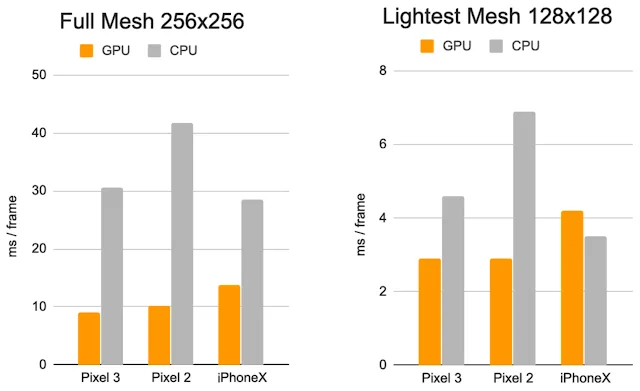
谷歌利用TensorFlow Lite实现机载神经网络推理。在可用时,新推出的GPU后端加速能够提升性能,并显著降低功耗。另外,为了涵盖广泛的消费类硬件,谷歌设计了具有不同性能和效率特性的一系列模型架构。对于较简单的网络而言,最重要的区别是残差块(Residual Block)布局和有效的输入分辨率(最简单的模型为128×128像素,而最复杂的模型中为256×256)。谷歌同时改变了层数和子采样率(随网络深度的输入分辨率减少速度)。
对于这一系列的优化,结果是更简单的模型能够实现大量的提速,同时对AR效果质量的影响维持在最低幅度。

谷歌的努力成果驱动着YouTube,ARCore和其他客户端的逼真自拍AR效果。
- 通过环境映射模拟光反射,实现眼镜的逼真渲染
- 通过将虚拟对象阴影投射到面部网格,实现了自然光照效果
- 建模面部遮挡以隐藏面部后面的虚拟对象部分,如虚拟眼镜
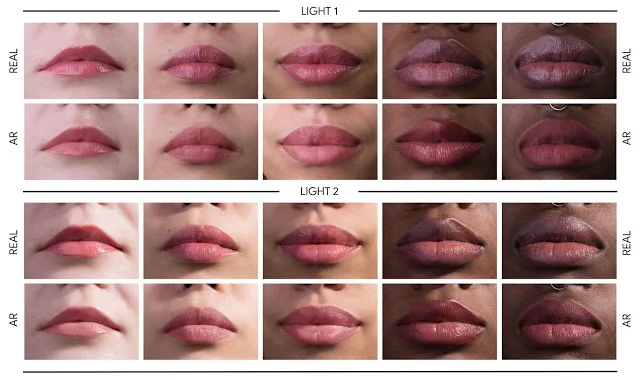
另外,谷歌实现了逼真的妆容效果,方式是:
- 建模应用于嘴唇的镜面反射
- 利用亮度感知材质来实现面部妆容
谷歌表示:“我们很高兴与创作者,用户和开发者的分享这一全新的技术。如果有兴趣,你可以马上下载最新ARCore SDK。在未来,我们计划将这项技术扩展至的更多的谷歌产品之中。”










