VR游戏《Space Pirate Trainer》如何用英特尔620集显实现流畅运行

文章相关引用及参考:intel
本文来自Seth S. (Intel)
(映维网 2018年08月24日)《Space Pirate Trainer》是兼容HTC Vive,Oculus Touch和Windows Mixed Reality的VR游戏之一。1.0版本最初于2017年10月发行,并迅速风靡VR社区,在全球VR街机店中占据了一席之地。据统计,这款游戏的销量已经超过15万份。这甚至成为了众多VR硬件厂商用来演示VR神奇之处的首选内容之一。
《Space Pirate Trainer》的创意总监,游戏开发商I-Illusions的首席执行官德克·范威尔登(Dirk Van Welden)曾说道:“我永远都不会开发VR游戏。”这是他首次使用Oculus Rift原型后发表的言论。作为Kickstarter的支持者,他拿到了这款设备,但并没有留下深刻的印象,因为范威尔登经历了相当严重的晕动症,并准备基本上放弃虚拟现实。
幸运的是,后来出现了位置追踪,而他准备再给VR一次机会,体验HTC Vive的原型。经过一个月的实验后,他们完成了《Space Pirate Trainer》的首个原型。范威尔登将其发布到SteamVR论坛,希望可以获得社区的反馈,而他在每个版本更新中发现了越来越多的受众。这款游戏同时引起了Valve的注意,后者邀请I-Illusions参加他们的SteamVR开发者演示,并向媒体介绍了《Space Pirate Trainer》。范威尔登知道自己已经做出了一定的成绩,所以他接受了邀请。即使在预测试阶段,游戏都受到了玩家的欢迎。

◐ 1. 什么是主流VR?
主流VR主要是指降低VR门槛,使得用户无需过分投资硬件即可开玩一些最流行的VR游戏。对于大多数高端VR体验,图形处理方面的最低规格要求是英伟达GeForce GTX 970或更高版本。除了购买昂贵的独显外,玩家同时需要为头显和传感器的组合支付数千人民币。VR设置的成本可以迅速叠加。
但是,如果可以在搭载集显的系统上运行VR游戏呢?这意味着拥有Microsoft Surface Pro,Intel NUC或Ultrabook设备的所有移动用户都可以开玩一些高端VR体验。搭配不需要外部追踪器的WMR头显,你将能够随时随地设置VR。这听起来好得令人难以置信,是吧?范威尔登和我也这么认为,但我们发现,你可以通过最小的权衡协调来实现非常优秀的体验。

图1:左为《Space Pirate Trainer》的预测试版;右边则是1.0版本
◐ 2. 在搭载集显的13瓦特SoC上以60 fps渲染两只眼睛?你是说真的吗?
如何令你的VR游戏在集显上运行呢?《Space Pirate Trainer》的初始端口运行速度为12 fps。主流空间所需的帧速率仅为60 fps,但这给我们留下了48 fps的空间,可以通过某种方式进行大幅度的优化。幸运的是,我们发现了一系列唾手可得的成果,亦即能够极大地影响性能的要素。下面是一个并排比较:

图2:左边以12 fps运行《Space Pirate Trainer》;右边的速度则是60 fps
◐ 3. 开始
VR开发者可能几乎都没有优化集成图形的经验,而这里需要注意一些非常重要的事情。在桌面分析和优化中,热量(热量产生)通常不是问题。你可以单独考虑CPU和GPU,并假设每个都能以完整的时钟速率运行。遗憾的是,SoC并非如此。“集显”意味着GPU与CPU集成在同一芯片上。每次电流通过电路都会产生一定的热量,并朝所有元件辐射。由于这种情况发生在CPU端和GPU端,因此这可以为整个封装带来大量的热量。为了确保芯片不会出现损坏,我们需要限制CPU或GPU的时钟速率以允许间歇性散热。
为了保持一致性,将搭载可预测热量模式的测试系统作为基线非常有用。这样你总是拥有一个可靠的参考点,可以在实验时验证性能优化或进行回归分析。为此,我们建议使用GIGABYTE Ultra-Compact PC GB-BKi5HT2-7200作为基准,因为它的热量非常一致。当在这台机器上以60 fps的速度运行游戏时,你就可以针对各个原始设备制造商(OEM)的设备,看看它们的运行效果。每台笔记本电脑都提供自己的散热解决方案,这有助于在热门的设备上运行游戏,并确保散热解决方案能够跟上。

图3:GIGABYTE Ultra-Compact PC GB-BKi5HT2-7200
规格(产品可能因地区而有所不同):
- 采用最新的英特尔酷睿第7代处理器
- 超小型PC设计,仅0.6L(46.8×112.6×119.4mm)
- 支持2.5英寸HDD/SSD,7.0/9.5 mm厚(1×6 Gbps SATA 3)
- 1 x M.2 SSD(2280)插槽
- 2个SO-DIMM DDR4插槽(2133 MHz)
- 英特尔IEEE802.11ac,双频Wi-Fi和蓝牙4.2 NGFF M.2卡
- 英特尔HD Graphics 620
- 1个Thunderbolt 3端口(USB 3.1 Type-C)
- 4个USB 3.0(2 x USB Type-C)
- 1个USB 2.0
- HDMI 2.0
- HDMI和Mini DisplayPort输出(支持双显示屏)
- Intel Gigabit Lan
- 双阵列麦克风(支持语音唤醒和Cortana小娜)
- 耳机/麦克风插孔
上述系统主要是用于我们的所有优化,以实现一致的结果。出于本文的目的和提供的数据,我们将采用Microsoft Surface Pro:

图4:Microsoft Surface Pro
规格:

对于本次优化,我们使用了英特尔图形性能分析器(Graphics Performance Analyzers)。这是一套图形分析工具,而我不会详细介绍每个细节。但在大多数情况下,我们将使用图形帧分析器(Graphics Frame Analyzer)。
◐ 4. 优化
为了达到60 fps,同时又不影响美学,我们进行了一系列的实验。以下列表说明了就性能和最小化艺术变化而言,优化降压的最大优势。当然,每次游戏都有所不同,但它们是你实验的第一步。
◐ 4.1 着色器-地板
第一个优化可能是最容易和最有效的改变。场景的地板可以占据相当一部分的像素覆盖。

图5:地板场景,地板进行了突出显示
上图在帧缓冲区中以洋红色突出显示了地板。就像素覆盖范围而言,地板占据场景的60%以上。这意味着影响地板的材质优化会对保持低于帧预算产生巨大的影响。《Space Pirate Trainer》当时采用了包含反射探针的标准Unity着色器来获取表面上的实时反射。反射是一项非常棒的功能,但在我们的目标系统上计算和采样每一帧的成本都有点过于高昂。我们使用简单的Lambert着色器来替换标准着色器。这不仅保存了反射采样,而且避免了使用正向渲染系统时标记为“重要”的动态照明所需的额外通道。
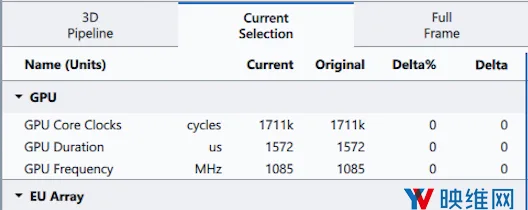
图6:优化前渲染地板的测量数据
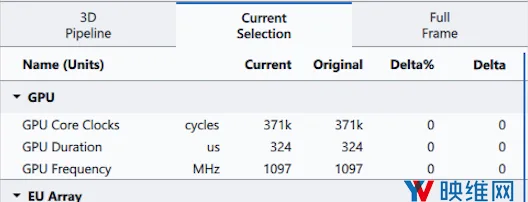
图7:在优化后渲染地板的测量数据
根据上面的性能比较,我们可以看到渲染地板的原始成本大约是每帧约1.5毫秒,而替换着色器的成本仅为每帧约0.3毫秒。 这在性能上提升了5倍。

图8:着色器的程序集从267条指令(左)减少到只有47条(右),而且每个样本的像素着色器调用次数明显减少
如上图所示,着色器的程序集从267条指令减少到只有47条,而且每个样本的像素着色器调用次数明显减少。

图9:同一场景的并排比较。左侧是标准着色器,右侧是优化的Lambert着色器。
上图是同一场景的并排比较图,分别采用的是标准着色器和Lambert着色器。请注意,在经历所有这些变化之后,我们仍然留下了一个漂亮,整体的地板。微软同时创建了许多Unity内置着色器的优化版本,并将它们作为其混合现实工具包的一部分。你可以试用工具包中的材质,并看看它们是如何影响游戏的画面和性能。
◐ 4.2 着色器-无光照着色器(unlit shader)的材质批处理
绘制调用批处理是捆绑具有共同属性的单独绘制调用的惯例。渲染线程通常是性能瓶颈的焦点,尤其是对移动和VR而言,而批处理只是功能带中缓解驱动程序瓶颈的主要工具之一。就Unity引擎而言,批量绘制调用所需的共同属性是材质和材质所使用的纹理。Unity引擎能够进行两种批处理:静态批处理和动态批处理。
静态批处理非常简单,通常使用起来很有意义。只要场景中的所有静态对象在检查器中都标记为静态,与这些对象的网格渲染器组件相关联的所有绘制调用都将进行批处理(假设它们共享相同的材质和纹理)。最好的做法是在引擎检查器中标记所有保持静态的对象,从而巧妙地优化不必要的工作,并将其从Unity引擎中的各种内部系统中删除,这对于批处理而言尤为如此。请记住,对于WMR主流而言,实例化立体渲染尚未实现,因此任何已保存的绘制调用都将计为两倍。
动态批处理有一点点细微差别。静态批处理和动态批处理之间要求的唯一区别是,必须考虑动态对象的顶点属性计数,并确保其低于某个阈值。请务必查看Unity文档以了解Unity版本的阈值。通过在英特尔GPA图形帧分析器中进行帧捕获来验证幕后实际发生的事情。请参阅下面的图10和图11,了解禁用和启用批处理后《Space Pirate Trainer》帧之间的帧可视化差异。
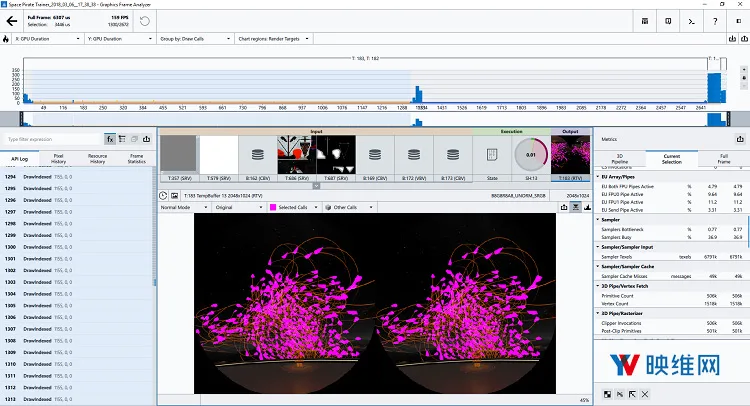
图10:禁用批处理和实例化;1300次绘制调用;总共150万个顶点;GPU持续时间为3.5毫秒/帧
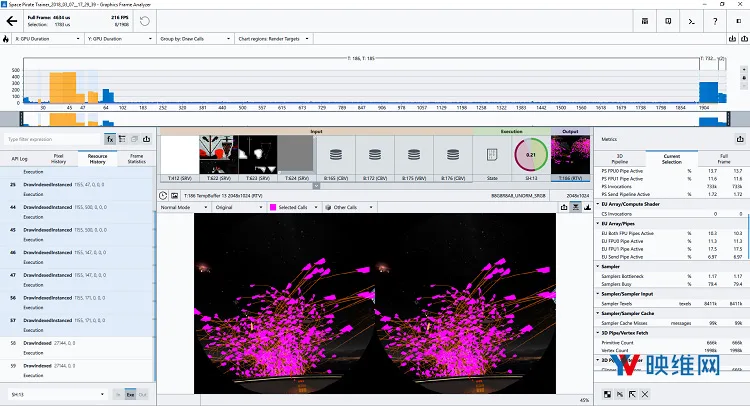
图11:启用批处理和实例化;8次绘制调用;总共200万个顶点;GPU持续时间为1.7 ms /帧(性能提升2倍)
如上图所示,渲染1300艘船(总共150万个顶点)所需的绘制调用量从1300一直下降到8。在批量处理的示例中,我们实际上渲染了更多的船只(总共200万个顶点)。这不仅节省了渲染线程上的大量时间,并且通过更有效地运行图形管道而在GPU上节省了相当多的时间。通过这样做,我们实际上获得了2倍的性能提升。为了最大化批量调用的总量,我们同时可以利用一种名为Texture Atlasing的技术。
Texture Atlas基本上大纹理和sprites的集成,用于将不同的对象打包至单一的大型纹理中。要利用这项技术,我们需要更新纹理坐标。这听起来可能很复杂,但Unity引擎提供了实用程序,可以帮助我们轻松实现自动化。美术同样可以利用他们选择的建模工具,并以熟悉的方式来构建Atlas。回顾模型之间共享纹理的批处理要求,Texture Atlas可以成为一种强大的工具,帮助你在运行时避免不必要的工作,从而以低于16.6毫秒/帧的速度进行渲染。
关键要点:
- 确保所有在其生命周期内永不移动的对象都标记为静态。
- 确保要进行批处理的动态对象的顶点属性少于Unity文档中指定的阈值。
- 确保创建Texture Atlas以包含尽可能多的可批量处理对象。
- 使用英特尔GPA图形帧分析器来验证实际行为。
◐ 4.3 着色器- 无人机镭射枪的LOD系统
LOD(细节层次)系统是指基于某些参数动态交换各种asset类型。在本节中,我们将介绍根据camera距离更换各种材质的过程。对象越远,在更低像素覆盖范围内实现最佳美学所需的资源就越少。更换asset应该对玩家保持隐晦。对于《Space Pirate Trainer》,范威尔登创建了一个系统,当无人机镭射枪距离camera达到一定范围时,就用更简单的着色器来替换镭射枪的Unity标准着色器的。请参阅以下示例代码:

这是一个非常简单的更新循环,它每隔100毫秒就检测替换材质所需的对象距离,如果超过30个单位远,则切换材质。请记住,替换材料可能会破坏批处理,因此总是建议首先进行实验,并判断优化将如何影响各种硬件级别上的帧时间。
除了这个手动材质LOD系统之外,Unity引擎同时在编辑器中内置了一个模型LOD系统。我们总是建议在较低瓦特的部分上为尽可能多的对象强制开启最低LOD。对于高保真度可以产生重大影响的场景关键部分,可以为计算更加昂贵的材质和几何体进行折衷。例如在《Space Pirate Trainer》中,范威尔登决定不遗余力地渲染爆能枪,因为它们一直是场景中的焦点。这些权衡可以帮助游戏保持所需的画面,同时仍然最大化目标硬件并吸引潜在的VR玩家。
◐ 4.4 照明与后期效果-移除动态光源
如前所述,当引擎使用正向渲染通道时,实时照明会严重影响GPU的性能。这种性能影响的显示方式是,受主要方向光源影响的模型的额外通道,以及所有光源都在检查器中标记为重要。如果你的模型位于两个重要动态点光源和主要方向照明的中间,你所看到的至少是这个对象的三个通道。
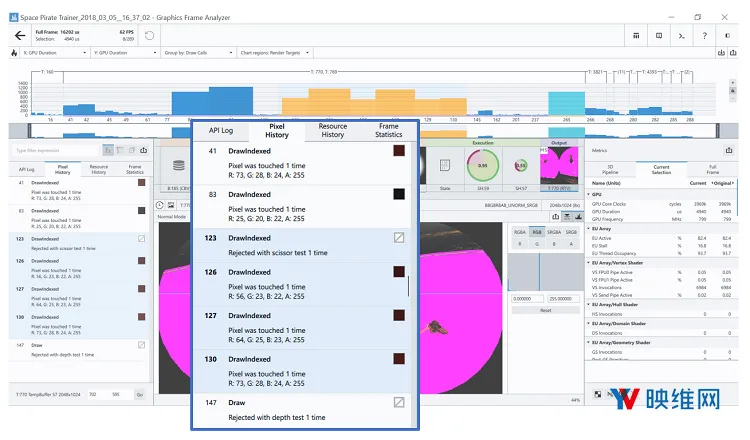
图12:每当玩家在《Space Pirate Trainer》开枪时,翻倍武器底部点亮的动态光源,为地板提供5 ms的帧时间(突出显示)
在《Space Pirate Trainer》中,枪管的点光源在较低的设置下被禁用,从而避免这些额外的通道,这可以节省相当多的帧时间。你可以回顾关于地板渲染的部分,并想象整个地板被渲染三次的情况。现在考虑为每只眼睛做这件事情。你将得到6个几何图形的调用,覆盖屏幕上大约60%的像素。
关键要点:
- 确保所有动态光源都被移除/标记为不重要。
- 烘烤尽可能多的光线。
- 为动态照明使用光线探针。
◐ 4.5 后期处理效果
如果不小心,后期处理效果可能会大幅削减你的帧预算。《Space Pirate Trainer》优化的“High”设置利用了Unity的后期处理堆栈,但在我们的表面目标上仍然只花费了大约2.6 ms/帧。见下图:
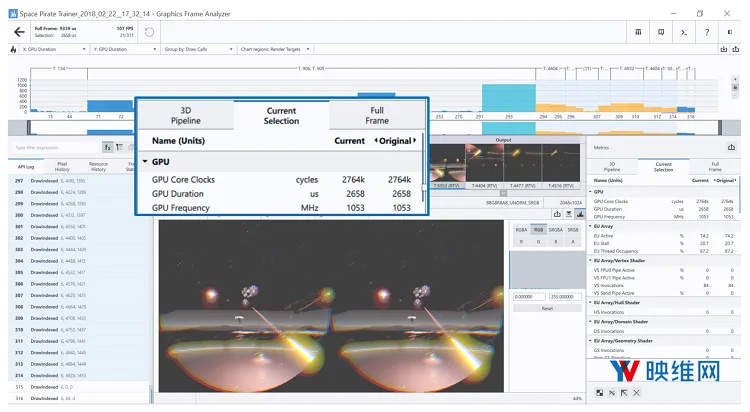
图13:“High”设置显示了14个通道(从更多中减少);GPU持续时间为2.6 ms/帧
上面突出显示的部分说明了《Space Pirate Trainer》后期处理效果中涉及的所有绘制调用,显示的弹出窗口是所选调用的总GPU持续时间,大约2.6 ms。在一开始,范威尔登和团队尝试用mobile bloom来取代常用的效果,但发现它引起了分散人注意力的闪烁。最终,他们决定废弃bloom,并将剩余的样式化效果合并到一个自定义通道中,使用color lookup table来近似计算高端版本的画面。
合并通道将帧时间从先前的2.6毫秒/帧降低至0.6毫秒/帧(4倍的性能改进)。这种优化涉及更多,可能需要一位优秀的技术美术,但这是一个非常好的技巧。另外,即使Bloom的移动版本不适用于《Space Pirate Trainer》,测试移动VFX解决方案也是一项优秀,快速且简单的实验。对于某些场景设置,它们可能奏效并且性能更高。使用新的后期处理效果通道,检查表示“Low”设置场景的帧捕获:
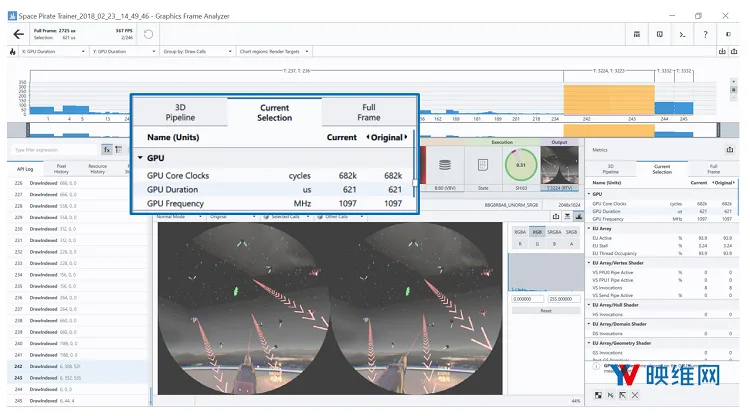
图14:“Low”设置,将所有后期处理效果合并为一个通道;GPU持续时间为0.6 ms/帧
◐ 4.6 HDR使用和垂直翻转
避免在“Low”Tier使用高动态范围(HDR)纹理,这可以以多种方式使性能受益,主要是因为HDR纹理和它们所需的技术(例如色调映射和bloom)在计算成本上相对昂贵。还有额外的颜色确定计算,以及每像素需要更多内存来表示全色范围。最重要的是,在Unity中使用HDR纹理会令场景呈现倒置情况。通常情况下这都不是一个问题,因为最终的渲染目标翻转只需大约0.3毫秒/帧,但当你的预算下降到16.6毫秒/帧时,你需要为每只眼睛进行一次翻转(约0.6毫秒/帧),这将占据帧的相当大一部分。
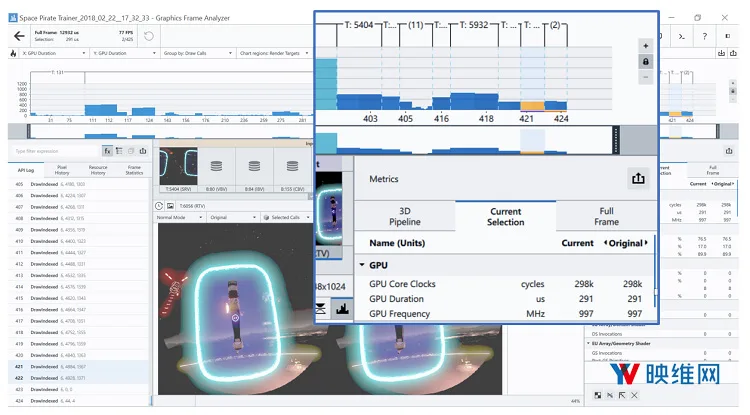
图15:单只眼睛的垂直翻转,291ms
关键要点:
- 取消选中场景camera上的HDR框。
- 如必须使用后期制作效果,请使用Unity引擎的Post-Processing Stack,而非有可能造成沉余工作的Image Effects。
- 移除任何需要深度通道的效果(如雾等)。
◐ 4.7 后期处理-抗锯齿
多重采样抗锯齿(MSAA)的计算成本高昂。对于低设置,切换到时间稳定的后期制作效果抗锯齿解决方案将相当明智。为了解MSAA在低端目标上的计算成本有多昂贵,我们下面来看看在高设置下捕获的《Space Pirate Trainer》:
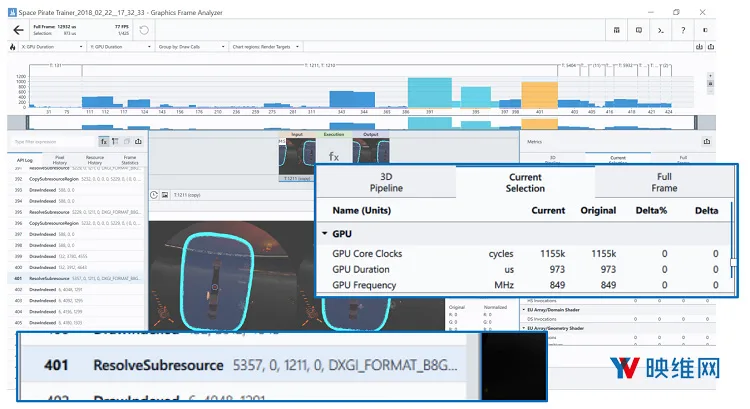
图16:使用多重采样抗锯齿(MSAA)时的ResolveSubresource成本
ResolveSubresource API调用是MSAA的固定函数方式,它确定启用MSAA时的渲染目标最终像素。我们可以在上面看到,单单这个步骤就需要约1毫秒/帧。
目前存在几种成本更低的后期制作效果抗锯齿解决方案,包括英特尔开发的Temporally Stable Conservative Morphological Anti-Aliasing (TSCMAA)。TSCMAA是可在英特尔集显上运行最快的抗锯齿解决方案之一。如果在升级到原生头显分辨率之前以低于1280×1280的分辨率进行渲染,则后期制作效果抗锯齿解决方案对于避免锯齿和保持良好体验方面将变得非常重要。

图17:TSCMAA与4倍多重采样抗锯齿的对比,前者提供了高达1.5倍的性能提升,有着更高质量的输出。请留意模型边缘的锯齿效果
◐ 4.8 镭射枪的光线投射CPU端优化
一般来说,光线投射操作在计算上并不是非常昂贵,但当《Space Pirate Trainer》出现太多的运动时,它们很快就会成为一种资源黑洞。大多数VR游戏的瓶颈都在于GPU,但为什么我们却在担心CPU性能呢?答案是热量限制。这意味着SoC的任何工作都会在整个系统封装中产生热量。因此,即使CPU在技术上不是瓶颈,CPU工作所产生的热量都能为封装带来足够的热量,从而限制GPU频率,甚至是CPU本身的频率。
热量的产生为优化过程增加了一层复杂性。移动开发者对这个概念已经非常熟悉。为集成GPU的CPU寻找完美优化方法分散了人们的注意力,但实际上不一定需要是这样。只需将整体优化视为主要目标即可。下面我们回到光线投射优化本身。
对于这种优化,其想法是光线投射检查频率可以根据距离而产生波动。光线投射越远,检查之间可以跳过的帧就越多。在范威尔登的测试中,他发现在最坏的情况下,实际的光线投射检查和远处对象的响应仅变化几帧,这在VR渲染所需的帧速率下几乎检测不到。

◐ 5. 以较低分辨率渲染,然后放大
大多数WMR头显的单眼原始分辨率为1.4K或更高。根据一系列不同的因素,以这个分辨率渲染到目标的计算成本可能非常昂贵。要定位低瓦特集成图形组件,把渲染目标设置为合理更低的分辨率将非常有用,然后让全息API自动调整以适应最终的原始分辨率。这将大大缩短你的帧时间,同时仍然能实现看起来不错的画面。例如,《Space Pirate Trainer》渲染至目标的单眼分辨率是1024×1024,然后进行放大。
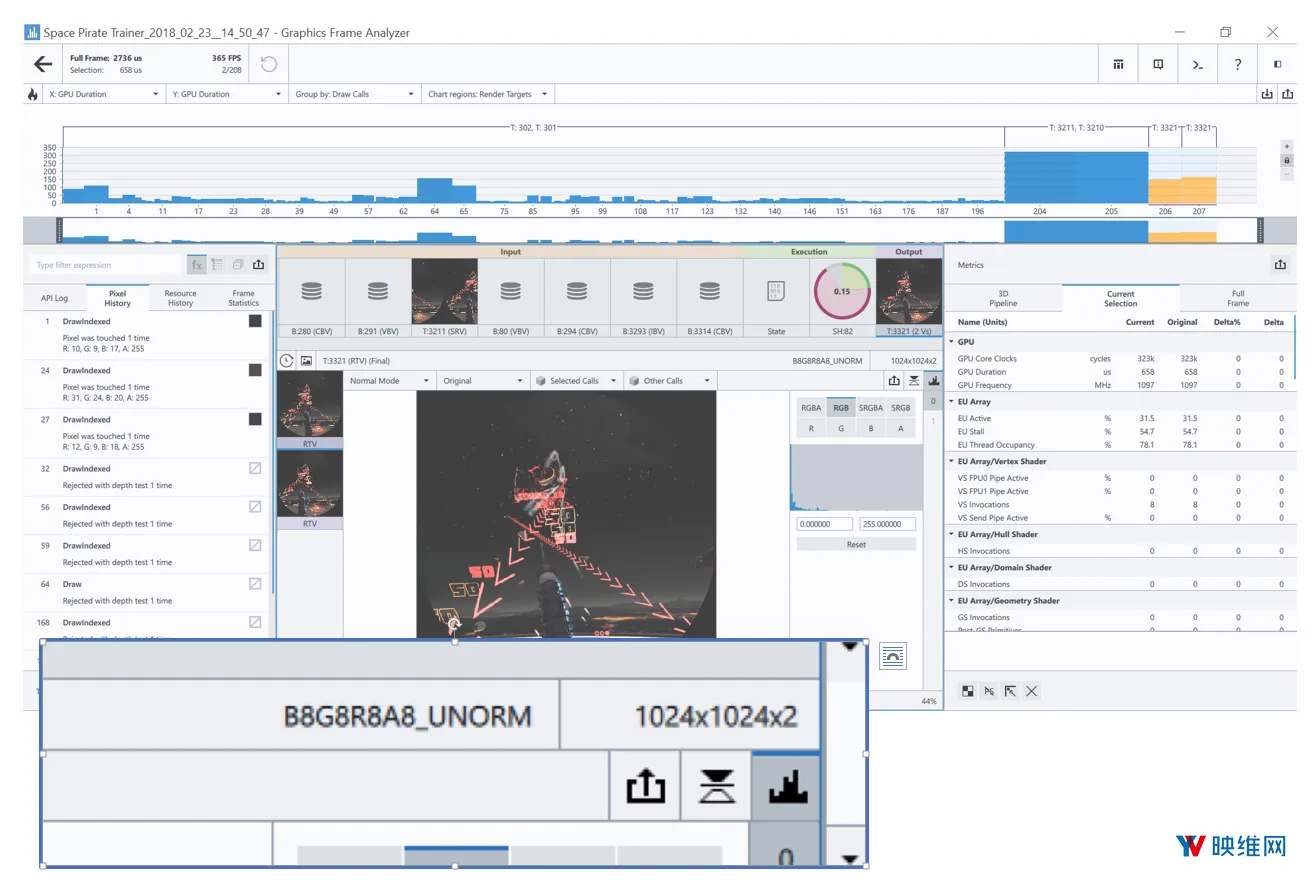
图18:渲染目标分辨率指定为1024×1024,然后放大至1280×1280
降低分辨率时需要考虑几个因素。显然,不同的游戏都有所不同,降低分辨率会以不同的方式影响不同的场景。例如,包含大量精细文本的游戏可能无法达到如此低的分辨率,或者必须使用不同的技巧来保持文本保真度。有时可以通过将UI文本渲染为全尺寸渲染目标,然后在较低分辨率渲染目标顶部进行位图复制。在渲染场景几何体时,这项技术可以节省大量计算时间,同时不会令整体体验质量受损。
要考虑的另一个因素是锯齿。渲染目标的分辨率越低,出现锯齿的可能性就越大。如前所述,可以使用后期制作效果抗锯齿技术来进行一定的止损。在考虑抗锯齿的成本之后,以较低分辨率渲染场景的像素调用节省通常为净正值。

◐ 5.1 首先渲染VR双手和其他排序注意事项
大多数VR体验都会渲染某种形式的双手表示玩家的实际双手位置。对于《Space Pirate Trainer》,替换的不仅只是双手,同时还有爆能枪。不难想象这些物品将覆盖两个眼睛渲染目标的大量像素。图形硬件支持一种名为Early-Z Rejection的优化技术,其允许硬件将正在渲染的像素深度与来自最后渲染像素的现有深度值进行比较。如果当前像素比最后一个像素更远,则不需要写入像素,并且保存该像素着色器的调用成本和图形管道的所有后续阶段。图形渲染的工作方式反向画家算法(reverse painter’s algorithm)类似。画家通常是从后到前进行绘画,而同时由于这种优化,从前到后在游戏中渲染场景将能带来巨大的性能效益。
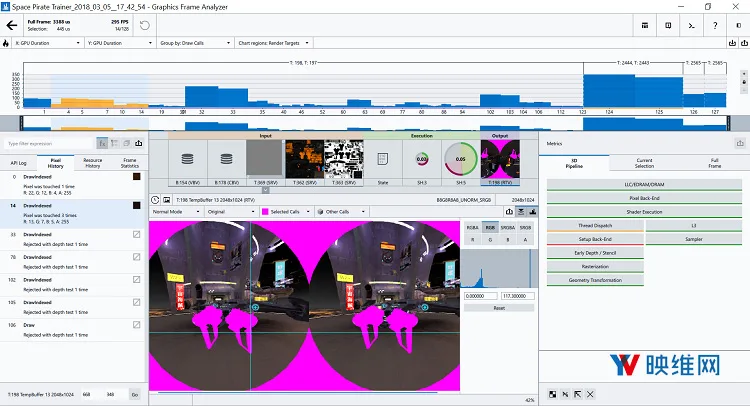
图19:在帧开头绘制《Space Pirate Trainer》中的爆能枪可以为所有像素保存像素调用
很难想象这样一个场景:VR双手,以及其握住的道具不会是最接近camera的网格。因此,我们可以先绘制双手。在Unity中这很容易做到这一点。你只需找到与手形网格相关的材质,以及可以拾取的道具,并覆盖它们的RenderQueue属性即可。通过使用UnityEngine.Rendering命名空间中提供的RenderQueue枚举,我们可以保证它们将在所有不透明对象之前得到渲染。相关示例请参见下图:

UnityEngine.Rendering命名空间中的RenderQueue枚举

覆盖材质RenderQueue参数的示例代码
如果需要,可以进一步覆盖材质的RenderQueue顺序,因为在任何给定时刻都存在对场景项目的逻辑分组。场景可以并按此进行分类与排序:
- 绘制VR双手和任何可交互的物品(如武器等)。
- 绘制场景填料。
- 绘制舞台大件布景(建筑物等)。
- 绘制地板。
- 绘制天空盒(如果是使用内置的Unity天空盒,这个步骤通常已经完成)。

图20.在覆盖RenderQueue顺序时,对场景进行分类可能会有所帮助
Unity引擎的排序系统通常能很好地处理这个问题,但有时你会发现不符合规则的对象。与往常一样,首先在GPA中检查场景的帧,从而确保在应用这些方法之前正确地排序所有内容。
◐ 5.2 天空盒压缩
最后一点是简单的修复,其存在一些潜在的优势。如果场景中使用的天空盒纹理尚未压缩,你将可以发现巨大的增益。根据游戏的类型,天空可以覆盖每帧中的大量像素。尽可能降低采样的强度,因为像素着色器可以对帧速率产生相当的影响。另外,当游戏检测到它在主流系统上运行时,降低天空盒纹理的分辨率同样有所帮助。请比较《Space Pirate Trainer》的性能:
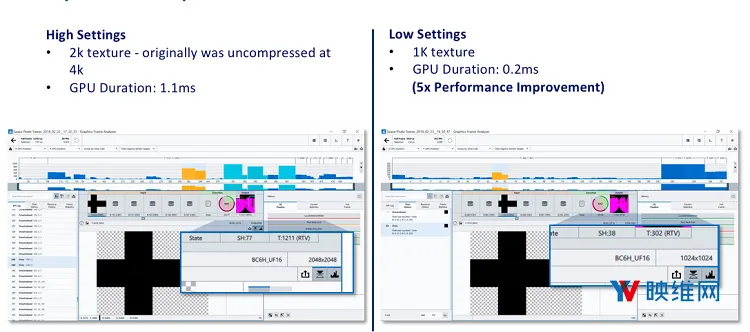
图21:只需简单地将天空盒分辨率从4K降低到2K,你可以实现5倍的性能提升。通过压缩纹理可以带来额外的提升
◐ 6. 总结
最后,我们在13瓦集成显卡组件的“Low”设置上以60 fps运行《Space Pirate Trainer》。随后,范威尔登将一系列的优化反馈到更高端平台的原始版本中,这样每个人都可以从中受益。
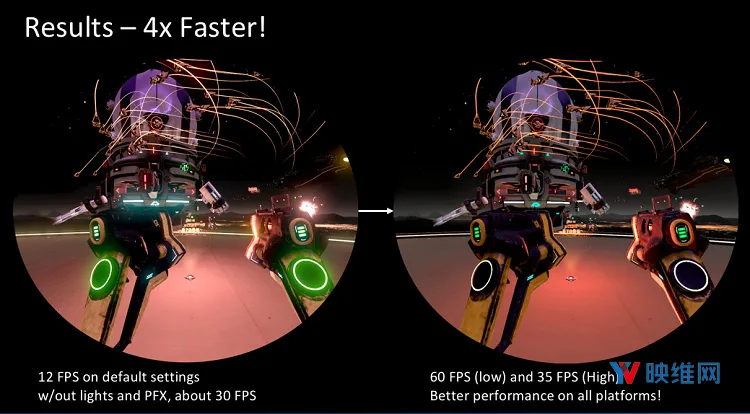
图22:最终结果:从12 fps一直到60 fps
之前以12 fps运行的“High”设置现在在集成图形系统上以35 fps运行。降低VR进入13瓦笔记本电脑的障碍可以将你的游戏带给更多的玩家,并帮助提高游戏的销售量。










