Oculus分享Lipsync工作原理,如何让虚拟角色唇部说话栩栩如生

文章相关引用及参考:oculus
这项技术将在最新的Oculus Lipsync Unity集成更新中向开发者开放
(映维网 2018年08月22日)在今年的Facebook开发者大会上,Oculus展示了音频到面部动画技术的最新进展。这项功能允许我们通过任何语言的口语来实时驱动面部动画。Oculus日前正式宣布,这项技术将在最新的Oculus Lipsync Unity集成更新中向开发者开放。
◐ 1. Oculus Lipsync的工作原理
Oculus Lipsync是一种Unity集成,用于将虚拟角色的唇部动作同步至语音。它主要是离线或实时分析音频输入,然后预测可用于令虚拟角色或非玩家角色(NPC)嘴唇动画化的一组发音嘴形。视觉音素/视素(visual phoneme/viseme)是嘴唇和面部的姿势或表达,其对应于特定的语音(音素)。例如在讨论读唇术时,我们常常使用这个术语,其概念类似于音素,并且是具备可理解度的基本视觉单元。在计算机动画中,我们可以使用视觉音素来制作虚拟角色的动作,令它们看起来像是在说话。
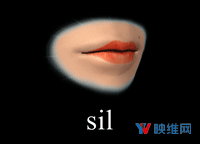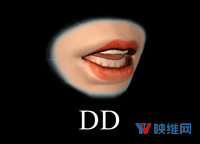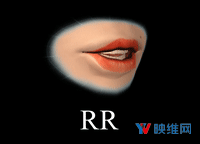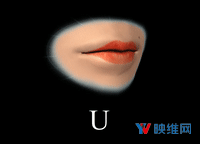
Oculus Lipsync将音频输入映射至一个包含15个视觉音素目标的空间:sil,PP,FF,TH,DD,kk,CH,SS,nn,RR,aa,E,ih,oh和ou。视素描述了在发出相应语音时产生的面部表情。例如,视素sil对应于silent/neutral表达;PP对应于在“popcorn(爆米花)”发音的第一个音节;FF是“fish(鱼)”的第一个音节,诸如此类。选择上述目标是为了给出最大范围的唇部运动,并且支持尽可能多的语言。有关这15个视素及其选择方式的更多信息,请参阅本文最后的文档:Viseme MPEG-4 Standard。尽管本文档包含了视素的参考图像,但Oculus发现艺术家难以从中复制精确的几何图形。为了克服这个问题,Oculus从多个角度制作了一组更高分辨率的视素参考图:Oculus Viseme Reference Images(Oculus视素参考图像)。
◐ 2. Oculus Lipsync的演变

当Oculus第一次发布LipSync时,他们专注于支持Facebook Spaces等应用程序。在这种情况下,它用于生成静态唇形张开和闭合的粗略动画。对于这一点,实现方式是使用Lipsync插件来驱动所谓的Texture-Flip风格面部动画,如上面的机器人动图所示。这里每个视素都映射到单个纹理,并且每帧显示最大活动视素的纹理。最近的社交VR发展(包括2018年初的Spaces更新)都使用了更高保真度,基于混合形状的面部模型,而这需要更高质量的面部动画。对于基于混合形状的模型,其需要对相同拓扑的不同几何形状(或混合形状)进行加权组合,并将它们相加以创建动态形状输出。这样的模型不仅需要预测最大活动的视素,而且要求所有视素的权重,从而能够流畅地为模型设置动画,结果如下图所示。为了实现如此高保真的面部动画,Oculus的研究团队采用了一种新颖的方法,将深度学习的进步与人类语音生成的知识结合了起来。
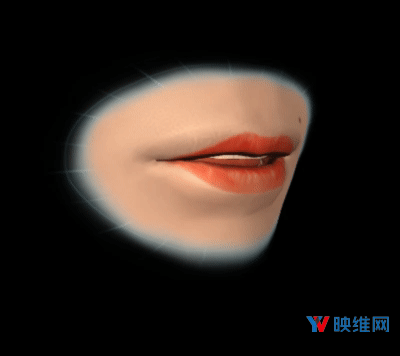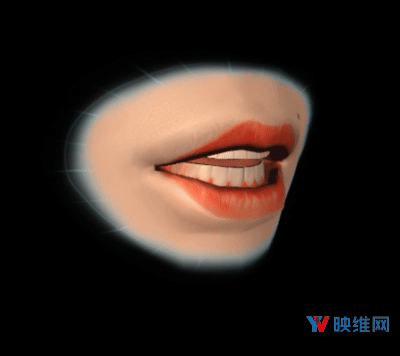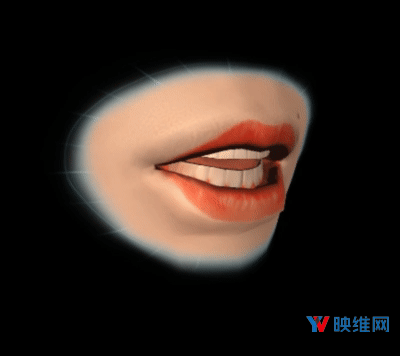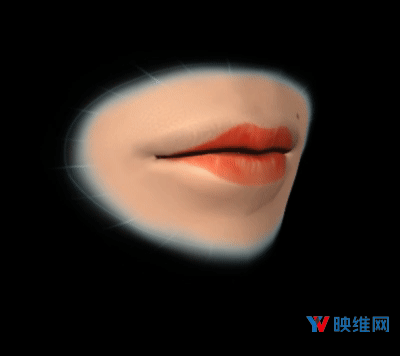
◐ 3. 以更高的精度预测视素
最初通过SDK 1.16.0推出的原版Oculus Lipsync采用一个小而浅薄的神经网络来学习一小段语音音频输入和音素(构成人类语音的声音单位)之间的映射。尽管这个模型在英语方面的效果相当好,但它在其他语言方面效果不佳,而且容易受背景噪音的影响。作为研究和产品之间的合作,Oculus投资了更新的机器学习模型,即时间卷积网络(TCN)。对于时间卷积网络,它们已经能够在其他领域的任务中实现显著更高的性能和稳定性,如视觉和语言。在内部测试中,这种TCN模型能够将英语语音的视素准确度提高30%以上,并且在重口音和大量背景噪音方面优于先前的模型。在Speech Processing社区中,它们被称为声学模型,并且经常用作语音识别管道的输入。
下图描述了一般的TCN架构。这个模型使用过去的low-level音频特征数据流来作为输入,以及在某些情况下(如对于离线应用而言),使用来自“未来”的信息来预测一组视素。可以调整架构的精确参数来优化计算效率和性能,但总体布局属于原样。
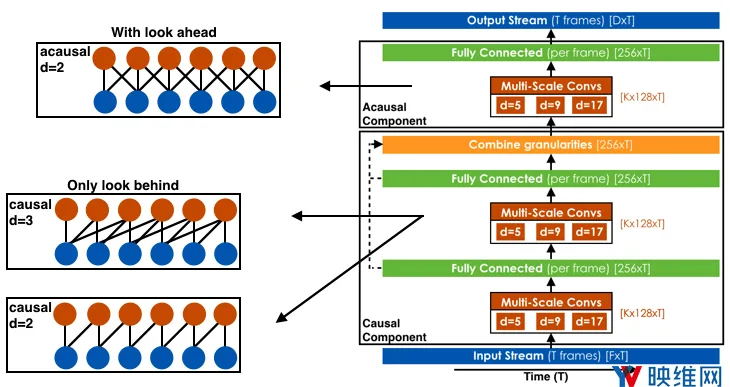
尽管模型比先前的Lipsync方法复杂得多,但Oculus能够使用类似于Fast WaveNet Generation Algorithm的缓存技术来非常有效地执行处理。
这项研究源于Facebook Reality Labs的一系列工作(在pyTorch中完成)。研究人员使用ONNX将模型转换为Caffe2以进行实时处理,并由Oculus进行优化和集成以包含在Oculus Lipsync中。
◐ 4. 制作逼真的面部动画
Oculus表示,这个全新的优化模型使他们意识到需要大量的努力来制作高质量的视素混合形状,从而驱动富有表现力的虚拟角色面部表情。Oculus的美术和面部姿势专家共同解决了这个问题,并制作了一套新的视素参考图像。借助这些参考图像,Oculus为虚拟角色,以及为演示几何创建了新的面部动画混合形状,具体可通过这个页面进行下载。
◐ 5. 总结
在这个版本中,Oculus为开发者提供了利用最先进唇形技术来驱动实时虚拟角色和非玩家角色的能力。这是Oculus和Facebook Reality Labs的研究科学家,机器学习工程师,产品管理,图形艺术家和面部姿势专家的共同努力。Oculus已经更新了Unity插件和演示内容,目标是令Oculus Lipsync更强大,更具表现力,更易于使用。
相关文档:MPEG 4FBAOverview