研发实战:如何用AMD LiquidVR技术优化CPU、GPU性能

文章相关引用及参考:gpuopen
本文来自于游戏开发小组Croteam的开发者Karlo Jez
(映维网 2017年10月24日)本文来自于游戏开发小组Croteam的开发者Karlo Jez,《Serious Sam VR:The Last Hope》的开发人员之一。他将向我们详细分享如何为游戏引擎添加Affinity Multi-GPU支持。

◐ 一. 介绍
假设你在一家商店,正在考虑购买哪款头戴式耳机。你不想花太多钱,所以你选择了一款质量不错,而且价格便宜的有线耳机。但数据线不可避免地出现了损坏,于是你回到了店里。由于你知道数据线很有可能再次出现问题,你不希望再为这个问题花费任何资金。经过一番挣扎之后,你最终还是购买了店内价格最贵的产品,而你心里一直懊悔,其实自己一开始就应该购买这款耳机。
◐ 二. 短期开发
同样地,当你需要为现有的游戏引擎添加虚拟现实渲染支持时,你希望可以尽可能快地实现并查看结果,然后再决定下一步计划。你通常是简单地渲染整个场景两次,针对每只眼睛使用不同的矩阵。这种方法的问题是会导致糟糕的性能表现,因为它会使绘制调用加倍。当然,你无需太多的努力便可得到一个正确渲染的VR场景。然而,更有效的方法是通过单通道渲染整个场景。
采用单通道的方式意味着我们每帧只渲染一次,同时为两只眼睛渲染视图,而这将能有效减少CPU负载。显然,我们正希望得到如此结果。但单通道渲染的缺点是,在现有引擎中实现起来往往更加困难,因为它需要更换大量的代码。
我们希望为引擎添加LiquidVR Affinity Multi-GPU渲染支持,因为与单个GPU相比,两个GPU可以在几乎一半的时间内渲染两只眼睛的视图,而这将能大大减少GPU的瓶颈限制。Affinity MGPU可以在单通道中实现,或者是为每只眼睛采用不同的通道。无论在那种情况下,我们都能在CPU工作负载保持不变的同时发挥出GPU的最大性能。
一开始,我们为Affinity MGPU VR渲染采用了相同的“一切从简”哲学,因为我们最初是为单个GPU进行设计,并决定采用两个单独的通道。在为引擎添加了这样的支持后,我们增加了所需的调用,以便第一个渲染通道面向第一个GPU,第二个渲染通道面向另一个GPU。在另一个GPU上渲染场景之后,它被复制到第一个GPU并提交至VR合成器。这很简单,但遗憾的是结果并不奏效。一个眼睛视图能够完美呈现出来,但另一只眼睛视图则完全是黑屏,或者只是一堆乱码。
◐ 三. 我们的引擎需要做出改变
对于不正确的眼睛视图,其根本原因在于我们的引擎没有关联感知能力。例如在一个GPU上绑定纹理会影响我们在另一个GPU上绑定相同的纹理,因为它已被标记为绑定。解决方案很简单:在为每只眼睛渲染视图后忘记纹理状态即可。然后,我们发现自己是从一个GPU上的空白表面读取数据,因为我们只在另一个GPU上渲染了该表面。对于这个问题的解决方案,我们可以在两个GPU渲染任何纹理之前为两个GPU设置关联。
我们发现了许多类似的问题,而且为这个简单的解决方案上付出了几个星期的工作努力。最终我们设法修复了几乎所有的渲染问题。这在GPU绑定的场景中带来了稳定的性能提升,但在CPU受限的情况下,我们一无所获。我们需要花更多的时间来寻找和修复剩余的渲染问题,所以我们把心一横并转移到单通道渲染。
◐ 四. 长期开发
对Affinity MGPU实施单通道渲染的最简单方法是,为每个GPU上的常量缓冲区设置不同的单个眼睛值,然后同时向两个GPU广播命令并渲染场景。这对我们来说是一个问题,因为我们庞大的着色器目录支持不同的常量集合:部分只有模型-视图-投影矩阵;部分需要单独的视图矩阵或投影矩阵,部分着色器只需要投影截面的部分,浏览器的位置,部分逆矩阵,或者是在视图空间中的对象位置。所有这些数据都是通过不同的常量寄存器进行传递,没有两个着色器支持相同的常量。这影响了我们为每只眼睛传递一组初始值,并在每个着色器中直接使用它们。
另外一个需求是,我们希望在单个GPU上使用相同的系统进行单通道渲染,而在同一个常量缓冲区中不可能存在不同的值,所以我们只能查询我们渲染的是哪一只眼睛视图。
我们的解决方案是在着色器中复制所有与眼睛相关的数据,这样每个着色器都可以同时访问左眼和右眼数据。我们添加了一个所有着色器都可以访问的单一全局常量,在第一个GPU上设置使用关联为0,另一个为1。然后,我们根据该常量使用左眼数据或右眼数据(或根据单个GPU渲染情况下的另一个预定义常量)。
◐ 五. 代码细节
我们现在将讨论一些编码细节。以下是一些简单的多通道单GPU渲染功能的伪代码:
// do the rendering pass for the left eye
vrSetCurrentEyeLeft();
vrRenderFrame(vrEyeRenderTargetLeft);// do the rendering pass for the right eye
vrSetCurrentEyeRight();
vrRenderFrame(vrEyeRenderTargetRight);
Here’s how it would look when adapted for single pass Affinity Multi-GPU rendering. Notice that rendering is done only once, but the preparation and copy after rendering is done for each GPU separately.
以下是改编为单通道Affinity Multi-GPU渲染时的情形。请注意,渲染仅完成一次,但会为每个GPU分别进行渲染后的准备和复制。
// upload constant value of 0 on the first GPU
gfxDevice->SetGPUAffinity(1);
gfxDevice->UploadSinglePassVRConstant(0);// upload constant value of 1 on the second GPU
gfxDevice->SetGPUAffinity(2);
gfxDevice->UploadSinglePassVRConstant(1);// render the frame on both GPUs (we use the same buffer for both eyes)
gfxDevice->SetGPUAffinity(3);
vrRenderFrame(vrSingleRenderTarget);// copy from the common buffer on the first GPU to the left eye buffer
gfxDevice->SetGPUAffinity(1);
gfxDevice->CopyDrawPort(vrSingleRenderTarget, vrEyeRenderTargetLeft);// copy from the common buffer on the second GPU to the right eye buffer and transfer it to the first GPU
gfxDevice->SetGPUAffinity(2);
gfxDevice->CopyDrawPort(vrSingleRenderTarget, vrEyeRenderTargetRight);
vrTransferRightDrawPort();
有趣的是,传递左眼和右眼矩阵不一定意味着向GPU发送两倍的数据量。只需完全发送一个矩阵即可,而另一个矩阵只需要发送不同的数据即可。我们注意到,在(模型)视图和投影矩阵的情况下,只有第一(X)行有所不同,因为眼睛之间的唯一差异是它们(在视图空间中)的水平偏移和平截头体的不同水平偏移。这意味着在为每个眼睛转换一个数据点时,只有视图和剪辑空间中的X坐标有所不同。
用于处理要选择的眼睛数据的逻辑位于一个单独的标头,其看起来像是这样子:
// constant that contains either 0 or 1 (depending on the current eye)
cbuffer VREye :register(b1) {float fVREye :packoffset(c0);}// sets the first row of the given transform matrix
inline float4x4 vrAdjustXRow(float4x4 mMatrix, float4 vRightX)
{
mMatrix._m00_m10_m20_m30 = lerp(mMatrix._m00_m10_m20_m30, vRightX, fVREye);
return mMatrix;
}// selects either the left eye or the right eye variable
inline float3 vrSelect(float3 vLeft, float3 vRight)
{
return lerp(vLeft, vRight, fVREye);
}
然后根据需要在每个着色器中使用,例如:
mObjToClip = vrAdjustXRow(mObjToClipLeft, vObjToClipRightX);
vViewPosAbs = vrSelect(vViewPosAbsLeft, vViewPosAbsRight);
六. 分析数据
在本节中,我们将讨论为单个和Affinity MGPU实施所实现的结果。
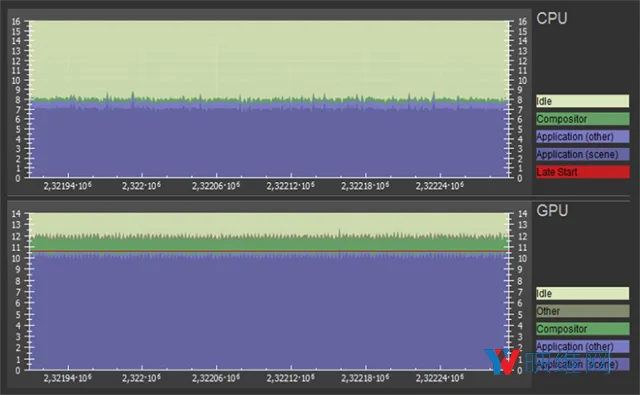
图表1是在使用单个Radeon RX 480渲染参考场景时的SteamVR GPU和CPU帧定时。你可以看到,当CPU使用率为每帧约8ms时,GPU正在超负荷工作(12 ms),而这阻止它以每秒90帧运行。图中的红线表示SteamVR已经启用了二次投影(将帧率降低到45 FPS)。
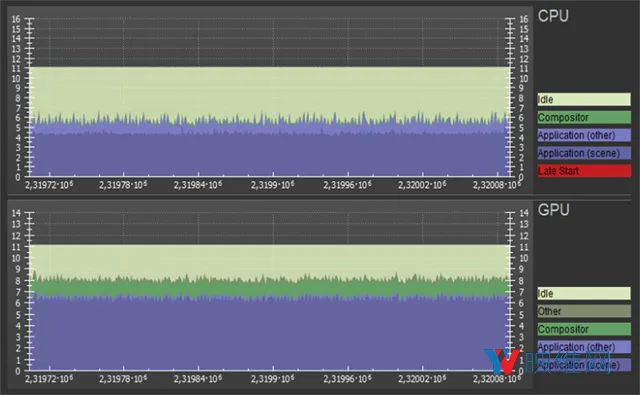
图表2是在两个Radeon RX 480显卡上启用Affinity MGPU的情景。得益于单通道渲染,以及GPU在大约8ms内完成工作,CPU的使用率从约8ms降低至约5.5ms。这使得我们有足够时间在稳定的90 FPS下运行游戏。
◐ 七. 总结
我们需要大约一个星期来修改所有着色器,并确保为每只眼睛设置正确的数据。使用Affinity Multi-GPU进行单通道渲染使得我们显着提高了CPU和GPU的速度。与修复由多通道多GPU渲染引起的问题相比,正确实现单通道渲染的所需时间更少。