杭州电子科技大学与新华智云提出EHPE手部姿态估计新方法

3D手部姿态估计
(映维网Nweon 2025年12月25日)计算机视觉领域,3D手部姿态估计始终是一座备受瞩目但难以逾越的高峰。它要求机器从单一的二维图像中,精准地解读出人手这一具有极高自由度的复杂三维结构的空间构型。尽管深度学习已赋予我们强大的特征提取能力,但一个顽固的症结始终存在:指尖(TIP)的定位误差如同一个放大器,将其不确定性传导至整个手部骨架,导致估计结果在细节上失真。
针对这个问题,杭州电子科技大学和新华智云科技提出了一项名为EHPE(Enhanced Hand Pose Estimation) 的解决方案。它不再遵循传统“输入图像,输出所有关节”的端到端范式,而是首创性地提出了一种 “分段式”架构。
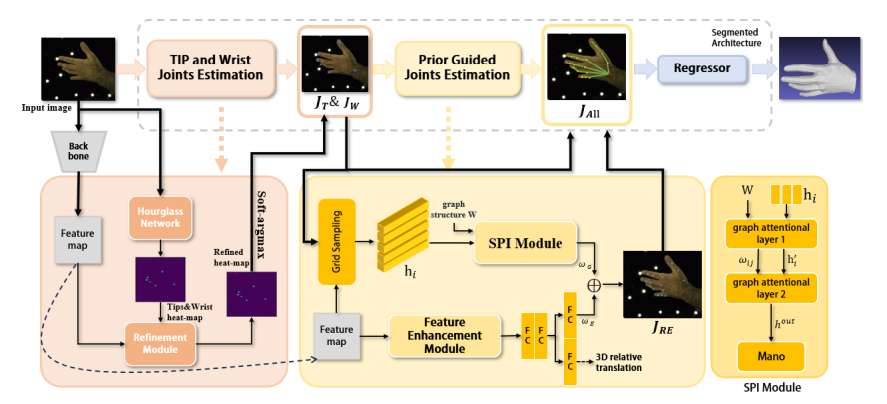
架构的核心思想是“分而治之”:首先集中优势兵力精准攻克误差最大、影响最大的指尖(TIP) 和腕部(Wrist) 关节,构建一个稳固的“空间坐标系”;然后,以其为基础,利用手部的生物力学先验,如同填充框架一般,智能地推理出其余所有关节的位置。这一策略不仅在技术上实现了精度的显著提升,更在方法论上为整个模型姿态估计领域提供了全新的思路。
......(全文 2024 字,剩余 1634 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限







