北京交通大学与帝国理工提出MLLM语义通信框架助力6G AR/VR沉浸式应用

任务导向、上下文感知的智能通信
(映维网Nweon 2025年11月28日)在6G网络即将到来的时代,增强现实、虚拟现实与全息通信等沉浸式应用对高维多模态数据的实时传输与智能处理提出了前所未有的挑战。所述应用需要实时处理高分辨率视频、密集点云、音频流和传感器信息等多模态数据,然而带宽受限的无线信道以及终端设备有限的计算能力和存储容量,使得高维数据传输和智能数据处理面临重大难题。
为应对这一挑战,北京交通大学与英国帝国理工学院的研究团队联合提出了一种名为”MLLM-SC”的新型语义通信框架,深度融合多模态大语言模型(MLLM)以实现任务导向、上下文感知的智能通信,为6G时代的沉浸式体验提供了创新解决方案。
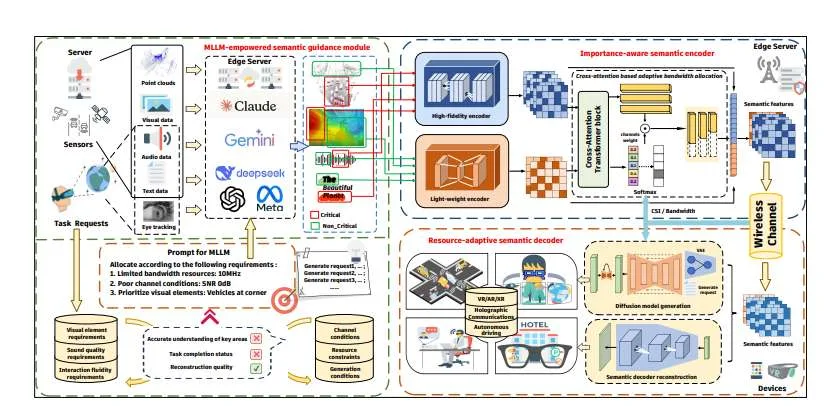
所述框架采用创新的”设备-边缘”协同架构,在边缘服务器部署MLLM作为语义理解与推理引擎。MLLM综合分析来自用户的多模态输入(包括图像、语音、眼动信号)、任务请求(如视觉问答、驾驶意图)及无线信道状态信息(CSI),通过先进的提示工程、上下文学习和软提示技术,生成语义注意力热图或二进制掩码,精确标识出对任务关键的区域与内容。
......(全文 1865 字,剩余 1457 字)








