瑞士团队提出HyperGaussians技术改进3D高斯面部建模

让数字面孔的细微表情、镜面高光乃至发丝眼镜都变得前所未有的清晰与生动
(映维网Nweon 2025年11月20日)在追求元宇宙与数字交互极致体验的今天,如何创造一个既真实又灵活的数字人面部Avatar,一直是计算机视觉领域的核心挑战。针对这个问题,瑞士苏黎世联邦理工学院的研究团队带来了一个名为HyperGaussians的技术,它如同给当前最流行的3D建模技术“3D高斯飞溅”进行了一次“高维进化”,让数字面孔的细微表情、镜面高光乃至发丝眼镜都变得前所未有的清晰与生动。
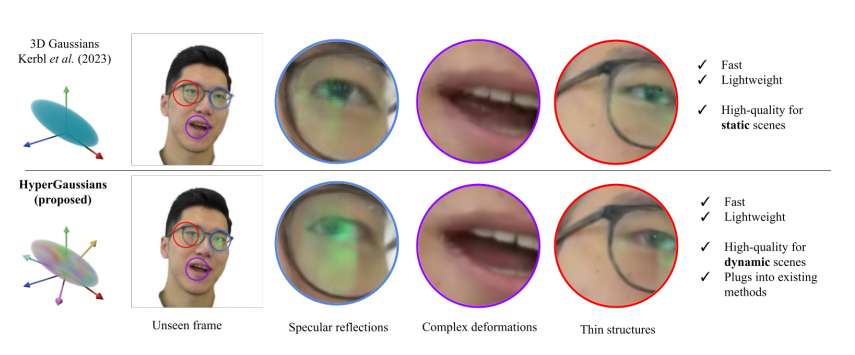
3D高斯飞溅自诞生以来,以其惊艳的渲染速度和渲染质量,迅速成为三维场景表示的新标准。其核心在于用数以万计、带有颜色、透明度和三维方向的小椭球来“泼溅”出一整个场景,从而实现实时、逼真的渲染。
然而,当这项技术应用于从单目视频创建可驱动、可动画的面部Avatar时,瓶颈出现了。现有的顶尖方法,如FlashAvatar、MonoGaussianAvatar等,通常将高斯点绑定在参数化人脸模型上,并利用神经网络根据表情参数来预测每个高斯点的位置、旋转和尺度的偏移量。
......(全文 2076 字,剩余 1700 字)
 请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
请微信扫码通过小程序阅读完整文章或者登入网站阅读完整文章
映维网会员可直接登入网站阅读
PICO员工可联系映维网免费获取权限







